Python2 编码问题分析
Posted alpha_panda
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python2 编码问题分析相关的知识,希望对你有一定的参考价值。
本文浅显易懂,绿色纯天然,手工制作,请放心阅读。
编码问题是一个很大很杂的话题,要向彻底的讲明白可以写一本书了。导致乱码的原因很多,系统平台、编程语言、多国语言、软件程序支持、用户选择等都可能导致无法正确的解析编码。
导致乱码的主要原因可以简单归结于文本的编码方式和解码方式不同导致的。本文将通过在win7(zh-cn)系统下分析python2.7的编解码问题来简单窥探一下编码的冰山一角。
今后遇到编码问题时能够多一点分析解决思路,要是能起到一个抛砖引玉的作用,那就再好不过了。
1.为什么需要编码
物理存储介质上的基本存储单元只能有两种状态,使用0和1区分。一段连续的0,1序列可以表示特定的信息。
理论上任何字符都可以被唯一的一个连续0,1组成的bit序列表示。如果这样的一个bit序列也唯一的代表一个字符,那么我们可以由此建立一个bit序列和字符之间的转换关系。
数字0 - 9和字母a - z(A - Z)等是人类可识别的字符,但是无法存入到计算机的存储介质中。
| 十进制 | 二进制(bit 序列) | 字符 |
| 48 | 0011 0000 | 0 |
| 65 | 0100 0001 | A |
| 97 | 0110 0001 | a |
为此,我们将这些人类可识别的有意义的字符与特定0,1组成的bit序列建立起一一对应的关系。
由字符转成对应的bit序列的过程称为编码,将bit序列解释成对应的字符则称之为解码。
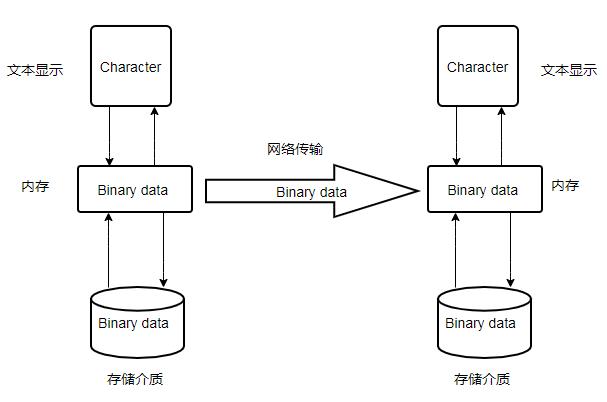
这样的一个bit序列可以用于存盘和网络传输等所有只能使用二进制表示的环境中。当需要阅读文件时再解码并在显示屏上显示出人类可识别的字符。
编码是人和机器之间的传递和表示信息的一种方式。
2.编码方式
字符与bit序列之间的转换随之带来的两个问题是:
- 怎么确定每个字符对应的编码?
- 每个字符的编码长度应该是多少?
第一个问题可以用一个大家公认的标准来解决。
第二个问题则主要是节约的角度考虑,在可以表示特定字符集的情况下,需要用尽可能短的二进制序列。
问题看似简单,但由于历史原因,不同国家不同语种的编码标准并不相同。而且即使同一个标准也在不断的发展。
我们常见的编码标准ASCII,UTF-8,Unicode,GBK(中文编码标准)等。
编码长度由编码方式决定,如ASCII码表示的字符都是一个字节(8 bits),Unicode编码的字符一般用两个字节。
同一种编码中不同字符的编码长度也可能不同。如UTF-8,对字符编码尽量压缩以节俭空间,是一种“可变长编码”。
既然存在这么多种编码方式,那么对于一段经过编码的二进制序列,如果以其他的编码方式解码,显然会得到错误的解码信息。
这就是我们所遇到的乱码问题。
那有没有一种编码方式可以将世界上所有的可表示字符都赋予一个唯一的编码?Unicode便是这样一种编码方式。
但是表示范围包罗万象的一个代价就是字符编码长度的增加。这样数据传输和存放时占用的网络和空间资源就会更多。
UTF-8是在Unicode基础上发展而来的可变长的编码方式。
| Character | ASCII | Unicode | UTF-8 | GBK |
| 0 | 00110000 | 00000000 00110000 | 00110000 | 00110000 |
| a | 01100001 | 00000000 01100001 | 01100001 | 01100001 |
| 字 | 无法表示 | 01011011 01010111 (u\'\\u5b57\') | 11100101 10101101 10010111 (\'\\xe5\\xad\\x97\') | 11010111 11010110 (\'\\xd7\\xd6\') |
注意:
上面的0是字符0,对应程序中“0”,而不是数字0。
数字是不使用字符编码的,数字可以使用原码、反码和补码表示,在内存中一般使用补码表示,其字节序有大小端模式决定。
3.编码转换
不同的编码有各自的特点,下面是一种可能的字符编辑显示、加载传输和存储对应的各阶段编码。
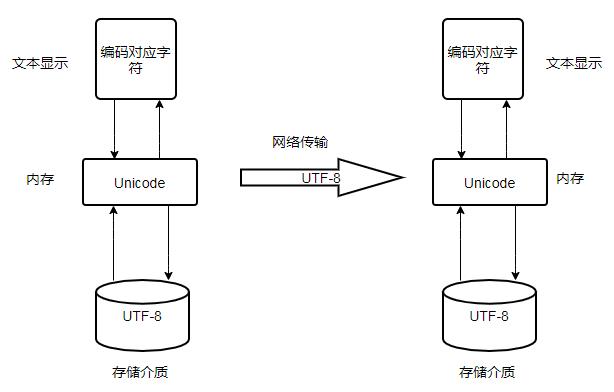
由于Unicode可以和任何编码相互转换,可以借助Unicode实现不同编码之间的变换。
python2中有两种表示字符串的类型:str 和 unicode。basestring是二者的共同基类。
Unicode对象包含的是unicode字符,而str对象包含的是字节(byte)。

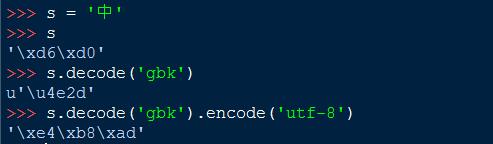
汉字“中”的编码三种编码方式
\'\\xd6\\xd0\'(GBK) <==> u\'\\u4e2d\'(UNICODE) <==> \'\\xe4\\xb8\\xad\'(UTF-8)
在win7 + python2.7的环境下,Python 自带的IDE中输入的中文默认编码方式为GBK
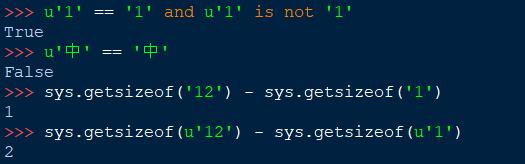
字符串 \'3132\' 的编码是 \'\\x31\\x32\\x33\\x34\'

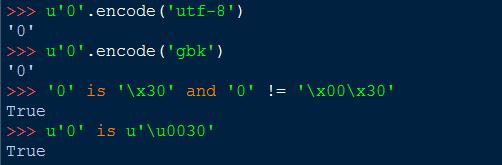
对应第二节表中的数值可以清楚的看到相同的字符对应的不同的编码。
也可以说明UTF-8和GBK的编码兼容ASCII。而ASCII表示的字符在Unicode中则需要两个字节表示。
一个以ASCII编码的文档(注意不是ANSI编码)可以使用UTF-8和GBK编码方式打开,而不能使用Unicode。
为了进一步验证,新建notepad++文档,选择编码方式为ANSI(即GBK),用喜欢的输入法以最快的方式键入汉字“中”。
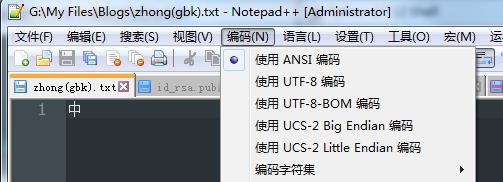
使用HEX-Editor插件查看文档的GBK编码二进制表示:
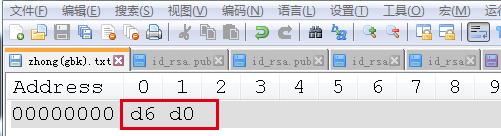
“中”的UTF-8编码二进制表示:
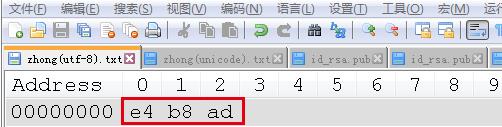
“中”的Unicode(对应notepad++中的USC-2 Big Endian)编码二进制表示:
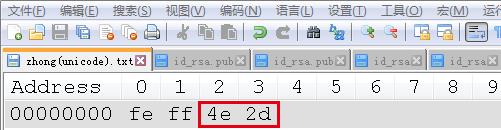
和python2中的结果相比可以看出
除了Unicode字符外,文件中存储的二进制数据和对应的编码是一一对应的。而这也验证了先前说的Unicode对象本身包含的并不是字节。
\\u是unicode编码的转义字符,上面起始的0xfeff可以看做unicode编码文件的一个起始标记。
例如
Unicode: 前两个字节为FFFE;
Unicode big endian: 前两字节为FEFF;
实际读取文件时会根据文件的前两个字节就可以判定出文件的具体格式。
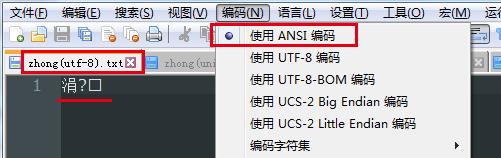
使用gbk的方式读取utf-8编码文件(将utf-8文件编码方式改为ANSI),将会以GBK的方式解读字utf-8的节序列\'\\xe4\\xb8\\xad\',结果如下:
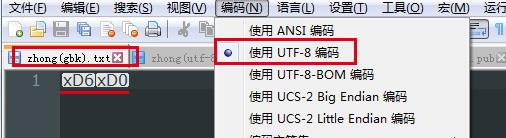
反之,使用utf-8的方式读取GBK编码文件(以utf-8的方式解读字GBK的节序列\'\\xd6\\xd0\'):
下面再看一个编解码不一致导致的显示问题:
看一下我们IDLE默认编码方式的确为GBK方式
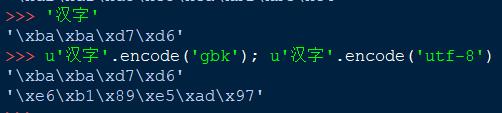
下面是一个字符串,我们平时常见的编码错误大概就是这种形式。
\'宸茬敤鏃堕棿\'
这个可以看做乱码,因为组合没有字面意思。其实这是一个utf-8编码按照gbk方式解码的结果,因此正确的方式先按照utf-8方式解码,然后编码成当前环境默认编码方式然后输出。
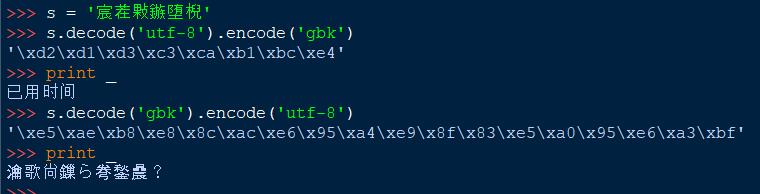
上面第二种错误的解码导致了更深一层次的乱码问题;解决这个问题是对字符串(非unicode)进行逆向的转换
>>> \'瀹歌尙鏁ら弮鍫曟?\'.decode(\'utf-8\').encode(\'gbk\').decode(\'utf-8\').encode(\'gbk\') \'\\xd2\\xd1\\xd3\\xc3\\xca\\xb1\\xbc\\xe4\' >>> print _ 已用时间
上面的转换过程如下:
\'\\xe5\\xae\\xb8\\xe8\\x8c\\xac\\xe6\\x95\\xa4\\xe9\\x8f\\x83\\xe5\\xa0\\x95\\xe6\\xa3\\xbf\', # 瀹歌尙鏁ら弮鍫曟? \'\\xe5\\xb7\\xb2\\xe7\\x94\\xa8\\xe6\\x97\\xb6\\xe9\\x97\\xb4\', #宸茬敤鏃堕棿 \'\\xd2\\xd1\\xd3\\xc3\\xca\\xb1\\xbc\\xe4\' #已用时间
4.文件显示标注编码类型
在python文件中我们可以使用下面的方式标记文件的编码类型:
# -*- coding:utf-8 -*-
#coding:utf-8
关于python文件编码类型的声明可以参考官网: PEP 263
网上有很多人认为上面的编码声明定义了python文件的编码方式,但与其说定义python文件的编码方式,不如说是这仅仅是对python解释器的一种编码方式声明。即python 文件的编码声明 # -*- coding: utf-8 -*- 只是给python解释器看的。当python解释器执行py文件时会根据这个声明来解析文件编码格式。
也就是说这个声明和文件本身实际的文件编码没有关系。但两者最好保持一致,否者python解释器会以错误的方式去解码文件内容并执行。
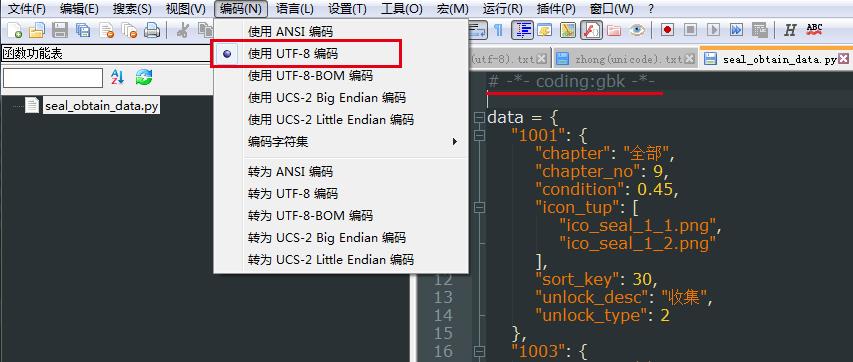
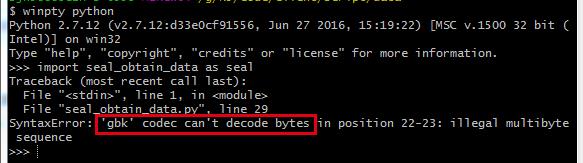
上面的文件声明 # -*- coding:gbk -*- 误导python解释器以gbk的编码方式去解析一个utf-8编码的文件。
实际开发过程中只需要统一将文件声明为utf-8即可。
再解释一下文件相关的编码概念:
文件本身的编码方式,该编码决定了文件数据以怎样的二进制格式保存在存储介质中。
文件内容显示的格式(解码方式),该编码方决定了文件内容是以怎样的解码方式被显示出来的。
一般文本显示类的程序打开一个文本时会根据文本文件起始字节判断该文本的编码方式,当然也可以有用户手动改变文件的解码方式。
如果文本程序或用户选择和编码方式不兼容的错误的解码方式,可能就会出现乱码。
但是对于可执行py文件而言,python解释器会以py文件开头的编码声明方式来解释文件内容,如果没有声明,python解释器会以默认的ASCII编码解析文件。
也就是只要python可执行文件的声明编码只要和实际文件的编码方式一致,就没有任何问题。因此可以使用# -*- coding:gbk -*-作为声明,但考虑到兼容性和可移植性,最好编码和声明均采用utf-8。
以上结果均在特定的平台和环境下得出,仅为个人见解。如有错误欢迎指正,共同探讨学习。
以上是关于Python2 编码问题分析的主要内容,如果未能解决你的问题,请参考以下文章