开源图像模型Stable Diffusion入门手册
Posted 轻风博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源图像模型Stable Diffusion入门手册相关的知识,希望对你有一定的参考价值。

Stable Diffusion 是 2022 年发布的深度学习文字到图像生成模型。它主要用于根据文字的描述产生详细图像,能够在几秒钟内创作出令人惊叹的艺术作品,本文是一篇使用入门教程。
硬件要求
建议使用不少于 16 GB 内存,并有 60GB 以上的硬盘空间。需要用到 CUDA 架构,推荐使用 N 卡。(目前已经有了对 A 卡的相关支持,但运算的速度依旧明显慢于 N 卡,参见:
Install and Run on AMD GPUs · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
过度使用,显卡会有损坏的风险。
进行 512x 图片生成时主流显卡速度对比:

环境部署
手动部署
可以参考 webui 的官方 wiki 部署:Home · AUTOMATIC1111/stable-diffusion-webui Wiki (github.com)
stable diffusion webui 的完整环境占用空间极大,能达到几十 G。同时,webui 需要联网下载安装大量的依赖,在境内的网络环境下下载很慢,请自带科.学.上.网.工具。
-
安装 Python 安装 Python 3.10,安装时须选中
Add Python to PATH -
安装 Git 在 Git-scm.com 下载 Git 安装包并安装。
-
下载 webui 的 github 仓库 按下
win+r输入 cmd,调出命令行窗口。运行:cd PATH_TO_CLONE git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git请把代码中的
PATH_TO_CLONE替换为自己想下载的目录。
-
装配模型 可在如Civitai上下载标注有CKPT的模型,有模型才能作画。下载的模型放入下载后文件路径下的
models/Stable-diffusion目录。 -
使用 双击运行
webui-user.bat。脚本会自动下载依赖,等待一段时间(可能很长),程序会输出一个类似http://127.0.0.1:7860/的地址,在浏览器中输入这个链接开即可。详细可参见模型使用。 -
更新 按下
win+r输入 cmd,调出命令行窗口。运行:cd PATH_TO_CLONE git pull请把代码中的:
PATH_TO_CLONE替换为自己下载仓库的目录。
整合包
觉得麻烦的同学可以使用整合包,解压即用。比如独立研究员的空间下经常更新整合包。秋叶的启动器 也非常好用,将启动器复制到下载仓库的目录下即可,更新管理会更方便。
打开启动器后,可一键启动:

如果有其他需求,可以在高级选项中调整配置。
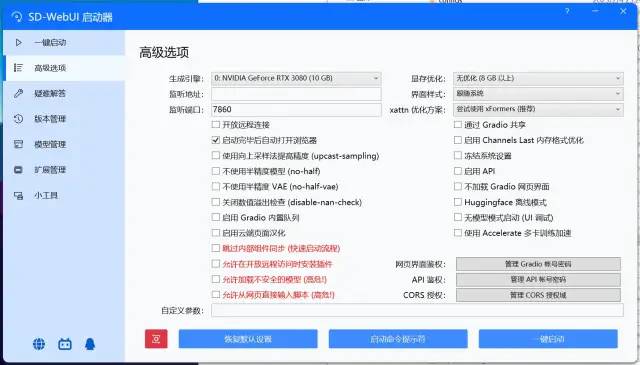
显存优化根据显卡实际显存选择,不要超过当前显卡显存。不过并不是指定了显存优化量就一定不会超显存,在出图时如果启动了过多的优化项(如高清修复、人脸修复、过大模型)时,依然有超出显存导致出图失败的几率。
xFormers 能极大地改善了内存消耗和速度,建议开启。准备工作完毕后,点击一键启动即可。等待浏览器自动跳出,或是控制台弹出本地 URL 后说明启动成功
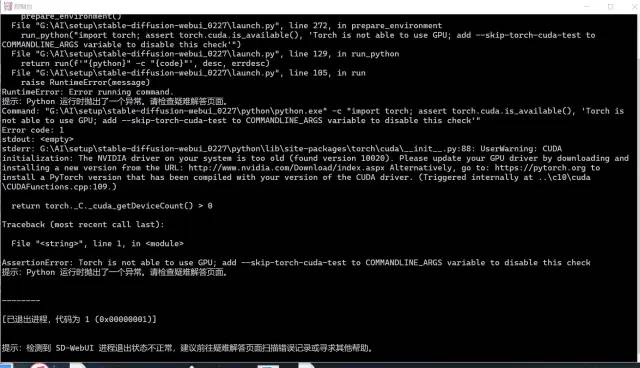
如果报错提示缺少 Pytorch,则需要在启动器中点击配置:

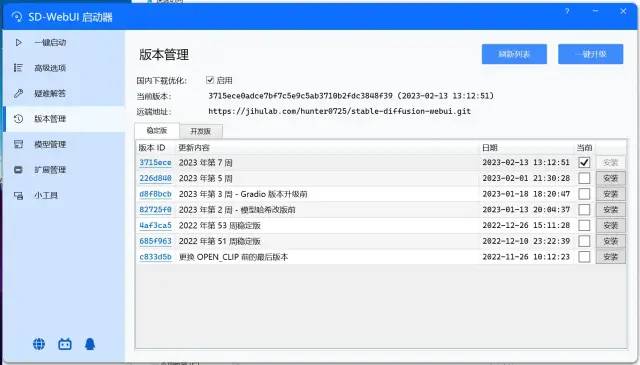
Stable Diffusion webui 的更新比较频繁,请根据需求在“版本管理”目录下更新:
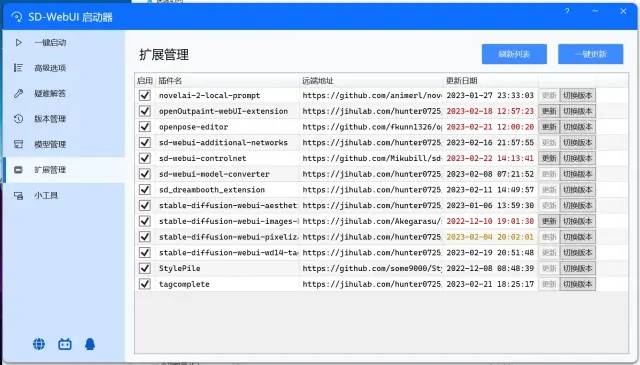
同样地,也请注意插件的更新:
关于插件
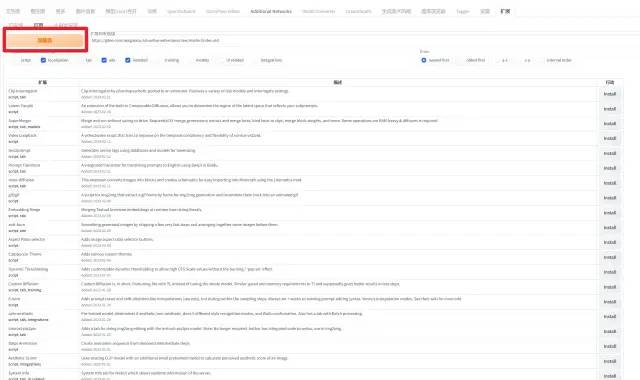
Stable Diffusion 可配置大量插件扩展,在 webui 的“扩展”选项卡下,可以安装插件:

点击“加载自”后,目录会刷新,选择需要的插件点击右侧的 install 即可安装。
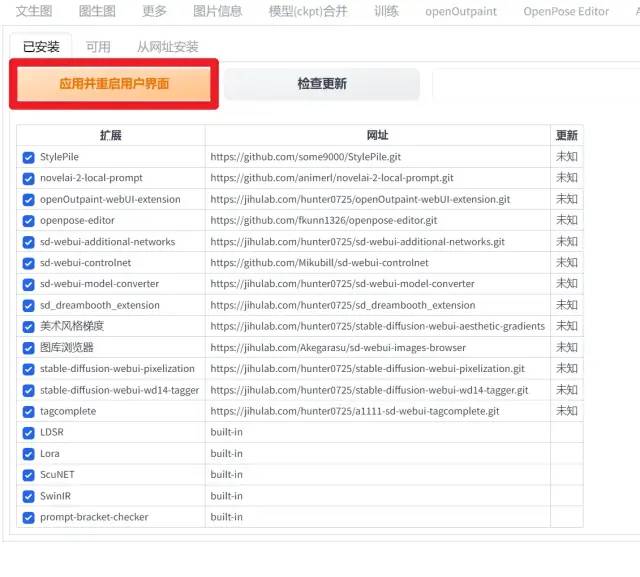
安装完毕后,需要重新启动用户界面:
文生图最简流程
-
选择需要使用的模型(底模),这是对生成结果影响最大的因素,主要体现在画面风格上。 
-
在第一个框中填入提示词(Prompt),对想要生成的东西进行文字描述 
-
在第二个框中填入负面提示词(Negative prompt),你不想要生成的东西进行文字描述 
-
选择采样方法、采样次数、图片尺寸等参数。 
-
Sampler(采样器/采样方法)选择使用哪种采样器。Euler a(Eular ancestral)可以以较少的步数产生很大的多样性,不同的步数可能有不同的结果。而非 ancestral 采样器都会产生基本相同的图像。DPM 相关的采样器通常具有不错的效果,但耗时也会相应增加。 -
Euler 是最简单、最快的 -
Euler a 更多样,不同步数可以生产出不同的图片。但是太高步数 (>30) 效果不会更好。 -
DDIM 收敛快,但效率相对较低,因为需要很多 step 才能获得好的结果,适合在重绘时候使用。 -
LMS 是 Euler 的衍生,它们使用一种相关但稍有不同的方法(平均过去的几个步骤以提高准确性)。大概 30 step 可以得到稳定结果 -
PLMS 是 Euler 的衍生,可以更好地处理神经网络结构中的奇异性。 -
DPM2 是一种神奇的方法,它旨在改进 DDIM,减少步骤以获得良好的结果。它需要每一步运行两次去噪,它的速度大约是 DDIM 的两倍,生图效果也非常好。但是如果你在进行调试提示词的实验,这个采样器可能会有点慢了。 -
UniPC 效果较好且速度非常快,对平面、卡通的表现较好,推荐使用。 -
Sampling Steps(采样步数)Stable Diffusion 的工作方式是从以随机高斯噪声起步,向符合提示的图像一步步降噪接近。随着步数增多,可以得到对目标更小、更精确的图像。但增加步数也会增加生成图像所需的时间。增加步数的边际收益递减,取决于采样器。一般开到 20~30。 -
不同采样步数与采样器之间的关系: 
-
CFG Scale(提示词相关性)图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示,但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。过高的 CFG Scale 体现为粗犷的线条和过锐化的图像。一般开到 7~11。CFG Scale 与采样器之间的关系: 
-
生成批次每次生成图像的组数。一次运行生成图像的数量为“批次* 批次数量”。 -
每批数量同时生成多少个图像。增加这个值可以提高性能,但也需要更多的显存。大的 Batch Size 需要消耗巨量显存。若没有超过 12G 的显存,请保持为 1。 -
尺寸指定图像的长宽。出图尺寸太宽时,图中可能会出现多个主体。1024 之上的尺寸可能会出现不理想的结果,推荐使用小尺寸分辨率+高清修复(Hires fix)。 -
种子种子决定模型在生成图片时涉及的所有随机性,它初始化了 Diffusion 算法起点的初始值。
理论上,在应用完全相同参数(如 Step、CFG、Seed、prompts)的情况下,生产的图片应当完全相同。
-
高清修复

通过勾选 "Highres. fix" 来启用。默认情况下,文生图在高分辨率下会生成非常混沌的图像。如果使用高清修复,会型首先按照指定的尺寸生成一张图片,然后通过放大算法将图片分辨率扩大,以实现高清大图效果。最终尺寸为(原分辨率*缩放系数 Upscale by)。
-
放大算法中,Latent 在许多情况下效果不错,但重绘幅度小于 0.5 后就不甚理想。ESRGAN_4x、SwinR 4x 对 0.5 以下的重绘幅度有较好支持。 -
Hires step 表示在进行这一步时计算的步数。 -
Denoising strength 字面翻译是降噪强度,表现为最后生成图片对原始输入图像内容的变化程度。该值越高,放大后图像就比放大前图像差别越大。低 denoising 意味着修正原图,高 denoising 就和原图就没有大的相关性了。一般来讲阈值是 0.7 左右,超过 0.7 和原图基本上无关,0.3 以下就是稍微改一些。实际执行中,具体的执行步骤为 Denoising strength * Sampling Steps。
-
面部修复修复画面中人物的面部,但是非写实风格的人物开启面部修复可能导致面部崩坏。 -
点击“生成” 
提示词
提示词所做的工作是缩小模型出图的解空间,即缩小生成内容时在模型数据里的检索范围,而非直接指定作画结果。提示词的效果也受模型的影响,有些模型对自然语言做特化训练,有些模型对单词标签对特化训练,那么对不同的提示词语言风格的反应就不同。
提示词内容
提示词中可以填写以下内容:
-
自然语言 可以使用描述物体的句子作为提示词。大多数情况下英文有效,也可以使用中文。避免复杂的语法。
-
单词标签 可以使用逗号隔开的单词作为提示词。一般使用普通常见的单词。单词的风格要和图像的整体风格搭配,否则会出现混杂的风格或噪点。避免出现拼写错误。可参考Tags | Danbooru (donmai.us)
-
Emoji、颜文字 Emoji (
由浅入深理解latent diffusion/stable diffusion:写给初学者的图像生成入门课
前言: 关于如何使用stable diffusion的文章已经够多了,但是由浅入深探索stable diffusion models背后原理,如何在自己的科研中运用stable diffusion预训练模型的博客少之又少。本系列计划写5篇文章,和读者一起遨游diffusion models的世界!本文主要介绍图像生成的历史,研读经典,细数发展历程。
目录
以上是关于开源图像模型Stable Diffusion入门手册的主要内容,如果未能解决你的问题,请参考以下文章