pandas DataFrame的增删查改总结系列文章:
在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧。
首先,还是列出一个我们用的DataFrame,注意index一列,如下:
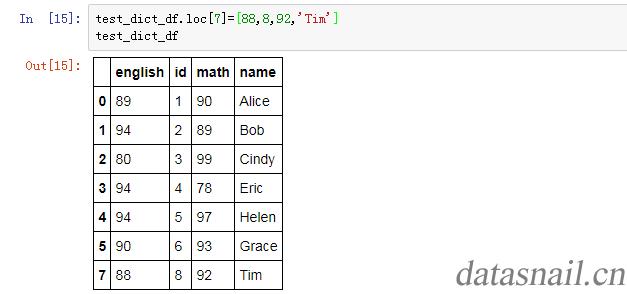
接下来,介绍下各个函数的用法:
1、loc函数
愿意看官方文档的,请戳这里,这里一般最权威。
loc函数是基于“标签”选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例:
1.1 单个label
接受一个“标签”(label)参数,返回一个Series,例如下面这个例子收一个标签,返回通过这个标签定位的行的值,注意这里是通过标签定位,而不是通过中括号中的数字定位第几行,之后我们通过对比iloc函数时还会细说。
test_dict_df.loc[1] #return the row with name \'Bob\'
test_dict_df.loc[7] #return the row with name \'Time\' important!!!
# type(test_dict_df.loc[1]) #pandas.core.series.Series
1.2 一个label的array
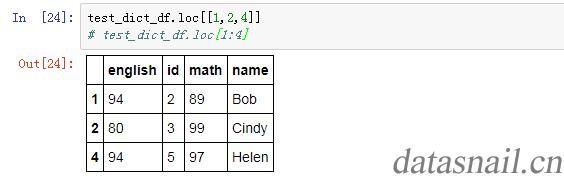
如果键入一个标签的array,那么就返回一个对应的DataFrame:
test_dict_df.loc[[1,2,4]]
结果如下:
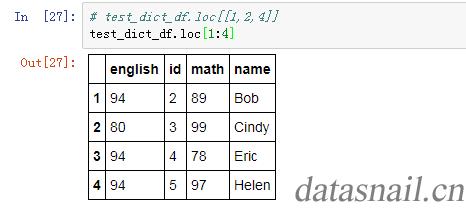
1.3 加入一个切片array
test_dict_df.loc[[1:4]]
结果如下:
1.4 行标签,列标签
通过在中括号中加入行标签和列标签来定位一个cell,相当于坐标的定位:
test_dict_df.loc[1,\'english\'] #result:94
1.5 行标签或者列标签是切片array
test_dict_df.loc[1:4,\'english\']
# test_dict_df.loc[1:4,\'english\':\'math\']
1.6 还可以接受条件,进行选择
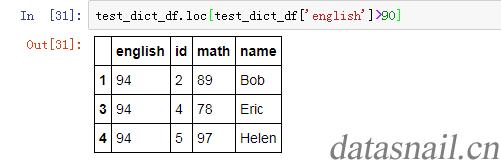
例如我们选择英语成绩超过90的所有行:
test_dict_df.loc[test_dict_df[\'english\']>90]
当然,也可以再条件选择后,再加入列选择,列选择的时候可以单列,也可以是切片数组,通过上面的介绍这里就可以灵活处理:
test_dict_df.loc[test_dict_df[\'english\']>90,\'english\'] #single label
test_dict_df.loc[test_dict_df[\'english\']>90,\'english\':\'name\'] #slice array
test_dict_df.loc[test_dict_df[\'english\']>90,[\'english\',\'name\']] #label array
1.7 接受一个boolean的array
可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值
test_dict_df.loc[[True,False,False,True]]
loc还有很多用法,这里先介绍到这里吧,当然如果你的DataFrame是复合的行或者复合列,写法也是不同的,具体就可以查阅官方文档了!
2、iloc函数
官方文档戳这里。
iloc函数与loc函数不同的是,它接受的是一个数字,代表着要选择数据的位置:
test_dict_df.iloc[6]
这代表我们选择的是第6行,而不是index为6的那一行。当然,也可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值:
test_dict_df.iloc[[True,False,False,True]]
这里iloc也可以接受切片array:
# test_dict_df.iloc[1:2]
test_dict_df.iloc[[1,2,4]]
3、ix函数(0.20.0版本后已经弃用)
ix就是一种混合索引,字符串的标签和证书的数据索引都可以作为合法输入,其实相当于loc和iloc的一个混合方法:
test_dict_df.ix[\'Alice\']
test_dict_df.ix[1]
上述两种方法都能得到值,这里我们就不追究这个函数具体是怎样的检索顺序或者工作原理了。因为官方给出的是从pandas0.20.0之后,ix函数已经被弃用。其实在使用的时候,ix函数虽然方便,但是的确有时候会显得比较混乱,所以我们之后也尽量少用这个函数吧,还是按照官方大佬的指导。
4、at函数
at是用来选择单个值的,此时用法类似于loc:
test_dict_df.at[1,\'english\']
test_dict_df.loc[1,\'english\']
以上两种方法都能选择到,label为1,列为\'english\'的那个值,但是据说at速度要快,这点我没有考证过。
5、iat函数
iat函数相对于at函数,就相当于iloc相对于loc函数。iat也只能选择一个值。只不过是用索引位置来选择,注意:行列都是索引位置来选择,从0开始数。
# test_dict_df.iat[1,\'english\'] #error!!!
test_dict_df.iat[2,2] #right!!!
6、概括一下
最后我们概括一下:
1、 loc和iloc函数都是用来选择某行的,iloc与loc的不同是:iloc是按照行索引所在的位置来选取数据,参数只能是整数。而loc是按照索引名称来选取数据,参数类型依索引类型而定;
2、 at和iat函数是只能选择某个位置的值,iat是按照行索引和列索引的位置来选取数据的。而at是按照行索引和列索引来选取数据;
3、 loc和iloc函数的功能包含at和iat函数的功能。
相应的代码连接:github代码
先写到这里,如有新的再补充。