数据库 增量同步和全量同步 是啥
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库 增量同步和全量同步 是啥相关的知识,希望对你有一定的参考价值。
增量同步和全量同步是数据库同步的两种方式。全量同步是一次性同步全部数据,增量同步则只同步两个数据库不同的部分。

数据库简介:
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,它产生于距今六十多年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。数据库有很多种类型,从最简单的存储有各种数据的表格到能够进行海量数据存储的大型数据库系统都在各个方面得到了广泛的应用。
参考技术A 1.背景数据如果保留多份,就会存在一致性问题,就需要同步,同步分为两大类:全量和增量
2. 概述
数据如果要保留副本,要么同时写(就是多写),或者进行复制:异步写(即从主数据拷贝到副本);
同时写(多写),引出一个问题,写多少节点算成功(场景:分布式系统)?全部写成功才算成功,还是写大多数成功算成功,还是写指定几个节点算成功?
异步写的话,如果采用异步复制,那么实时性需要考量的话,就需要采用性能优先的架构。
3.同步方式
数据同步一般分为两种方式:全量和增量。
3.1 全量
全量,这个很好理解。就是每天定时或者周期性全量把数据从一个地方拷贝到另外一个地方;
全量的话,可以采用直接全部覆盖(使用“新”数据覆盖“旧”数据);或者走更新逻辑(覆盖前判断下,如果新旧不一致,就更新);
这里面有一个隐藏的问题:如果采用异步写,主数据物理删除了,怎么直接通过全量数据同步?这就需要借助一些中间操作日志文件,或者其他手段,把这些“看不到”的数据记录起来。
3.2 增量(类如有;坚果云网盘增量同步功能)
增量的基础是全量,就是你要使用某种方式先把全量数据拷贝过来,然后再采用增量方式同步更新。
增量的话,就是指抓取某个时刻(更新时间)或者检查点(checkpoint)以后的数据来同步,不是无规律的全量同步。这里引入一个关键性的前提:副本一端要记录或者知道(通过查询更新日志或者订阅更新)哪些更新了。 参考技术B 是数据库同步的两种方式。全量同步是一次性同步全部数据;增量同步则只同步两个数据库不同的部分。本回答被提问者采纳 参考技术C 常见的备份方式有全量备份、增量备份、差异备份,其中:
全量备份是指对某一时间点上的所有数据进行全量备份,包括系统和所有数据。这种备份方式每次都需要对系统和所有数据进行一次全量备份。如上,如果两次备份之间数据没有任何变化,那么两次备份的数据是一样的。也就是说100GB的数据即使没有发生任何数据变化,也会多耗费100GB的存储空间去做备份。但这种备份方式最大的好处就是在恢复丢失数据时,只需要对一个完整的备份进行操作就能够恢复丢失数据,大大加快了系统或数据恢复的时间。
增量备份即在第一次全量备份的基础上,分别记录每次的变化。由于增量备份在备份前会判断数据是否发生变化,并仅记录每次变化情况,所以相较于其他两种备份方式它最大的好处在于其所需存储空间最少的(相同的变化情况下),备份速度最快的。当然在数据还原上来说,它的恢复时间是最长的,效率较低。恢复数据时,需要在第一次完备的基础上,整合每次的一个变化情况。
差异备份就是在第一次全量备份的基础上,记录最新数据较第一次全量备份的差异。简单来说,差异备份就是一个积累变化的过程:在全量备份之后,第一天记录第一天的变化,第二天记录第一天和第二天的变化,以此类推......因此,恢复系统或者数据时,只需要先恢复全量备份,然后恢复最后一次的差异备份即可完成。所以差异备份占用的储存空间和所需恢复时间介于全量备份和增量备份之间。
通过Logstash全量和增量同步Mysql一对多关系到Elasticsearch
前言
在实际开发项目过程当中,难免会使用到Elasticsearch做搜索。文章描述从Mysql通过Logstash实时同步到Elasticsearch,下面就开始来进行实现吧!具体的Elasticsearch+Logstash+kibana搭建,请移步到 ELK搭建步骤。
实现方案
本人总结了两种实现方案来实现mysql到es的同步。
- 使用Elastic官方提供的 Logstash 来实现Mysql的全量和增量同步(根据时间戳或者自增id)。
- 使用Elastic 官方提供的 Logstash 来实现全量同步,后续的数据库表更新、删除、修改等通过阿里开源的框架canal实现(增量同步)。 canal伪装成mysql的从节点,通过binlog日志文件进行同步,通过Java程序进行监听,同步到Elasticsearch当中。
本次介绍通过 Elastic 官方提供的 Logstash 来实现Mysql的全量和增量同步。
全量和增量同步
先看Mysql表的关系
一个是主表:news 资讯文章表,表内容如下:

一个是从表:custom_infomation 定制信息表,与news 成 一对多的关系,一条文章对应多条定制信息。表内容如下:

描述:custom_information表中的item_id和news表中的id有关联关系。
用JSON数据结构来描述一对多的关系,如下:
{
"id":"15c7ee7a5dc411ea9bc2fa163e0c8256",
"title":"“宅经济”进入数字化时代",
"source":"人民日报",
"customList":[
{
"secondLevel":"32552",
"isRelEnterprise":"0",
"secondLevelName":"济南",
"moduleType":"1",
"customName":"地区1",
"firstLevel":"37200",
"firstLevelName":"山东",
"customId":"1",
"detId":"1"
},
{
"secondLevel":"222",
"isRelEnterprise":"0",
"secondLevelName":"林业1",
"moduleType":"1",
"customName":"行业1",
"firstLevel":"11",
"firstLevelName":"林业",
"customId":"2",
"detId":"3"
}
]
}
这里需要和Elasticsearch做映射关系。在Elasticsearch中也是一对多的关系。大致是这样的结构,这里采用的是Elasticsearch中的nested类型来实现。

创建所需索引(采用静态mapping映射)
PUT app-article-link
{
"mappings" : {
"properties" : {
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"customList" : {
"type" : "nested",
"properties" : {
"customId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"customName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"detId" : {
"type" : "keyword"
},
"firstLevel" : {
"type" : "keyword"
},
"firstLevelName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"isRelEnterprise" : {
"type" : "keyword"
},
"moduleType" : {
"type" : "keyword"
},
"secondLevel" : {
"type" : "keyword"
},
"secondLevelName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"custom_list" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"detail" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"endTime" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"industryName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"isDelete" : {
"type" : "keyword"
},
"price" : {
"type" : "keyword"
},
"publishDate" : {
"type" : "keyword"
},
"relevanceType" : {
"type" : "keyword"
},
"savePath" : {
"type" : "keyword"
},
"source" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
},
"suggest" : {
"type" : "completion",
"analyzer" : "simple",
"preserve_separators" : true,
"preserve_position_increments" : true,
"max_input_length" : 50
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"startTime" : {
"type" : "keyword"
},
"summary" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"techFieldName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
},
"suggest" : {
"type" : "completion",
"analyzer" : "simple",
"preserve_separators" : true,
"preserve_position_increments" : true,
"max_input_length" : 50
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"update_time" : {
"type" : "keyword"
},
"videoStatus" : {
"type" : "keyword"
}
}
}
}
以下是Logstash 相关配置操作:
由于上面描述的数据库表是一对多的关系,这里选择先建立一个视图,原因是会通过数据库表的最新时间字段来作为临界点进行数据同步(关键点是找出主表和从表的最新时间点)。视图创建sql如下:
SELECT
t.id,
t.title,
t.source,
'8' AS relevanceType ,
date_format( greatest( `t`.`update_time`, ifnull( `i`.`update_time`, '1970' )), '%Y-%m-%d %H:%i:%s' ) AS `update_time`
FROM
`news` t
LEFT JOIN custom_information i
ON t.id=i.item_id
AND i.is_delete='0'
AND i.module_type='8'
WHERE
t.state = '0'
AND t.publish_status='3'
AND t.relevance_type='2'
上面的update_time为两表中的最新时间。
在logstash congf目录下创建news.conf,内容如下:
input {
jdbc {
jdbc_driver_library => "/opt/apps/logstash/lib/mysql-connector-java-8.0.13.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.0.178:3306/test?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
jdbc_user => "root"
jdbc_password => "123456"
connection_retry_attempts => "3"
jdbc_validation_timeout => "3600"
jdbc_paging_enabled => "true"
jdbc_page_size => "500"
statement_filepath => "/opt/apps/logstash/sql/news.sql"
use_column_value => true
lowercase_column_names => false
tracking_column => "update_time"
tracking_column_type => "timestamp"
record_last_run => true
last_run_metadata_path => "/opt/apps/logstash/station/news.txt"
clean_run => false
schedule => "*/5 * * * * *"
type => "news"
}
}
filter {
aggregate {
task_id => "%{id}"
code => "
map['id'] = event.get('id')
map['title'] = event.get('title')
map['source'] = event.get('source')
map['custom_list'] ||=[]
map['customList'] ||=[]
if (event.get('detId') != nil)
if !(map['custom_list'].include? event.get('detId'))
map['custom_list'] << event.get('detId')
map['customList'] << {
'detId' => event.get('detId'),
'moduleType' => event.get('moduleType'),
'customId' => event.get('customId'),
'customName' => event.get('customName'),
'firstLevel' => event.get('firstLevel'),
'firstLevelName' => event.get('firstLevelName'),
'secondLevel' => event.get('secondLevel'),
'secondLevelName' => event.get('secondLevelName'),
'isRelEnterprise' => event.get('isRelEnterprise')
}
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
mutate {
}
mutate {
remove_field => ["@timestamp","@version"]
}
}
output {
elasticsearch {
document_id => "%{id}"
document_type => "_doc"
index => "app-article-link"
hosts => ["http://192.168.0.178:9200"]
}
stdout{
codec => rubydebug
}
}
input{} 中
statement_filepath 为sql语句位置,
last_run_metadata_path 记录最新时间位置,下次从这个时间点开始更新,
tracking_column 为更新的时间字段,
schedule 执行的时间 上述中每个五秒钟执行一次,
执行的sql:
SELECT
n.id,
n.title,
n.source
FROM
news_view n
order by n.update_time
编辑conf/pipelines.yml
[root@localhost config]# vi pipelines.yml
# List of pipelines to be loaded by Logstash
#
# This document must be a list of dictionaries/hashes, where the keys/values are pipeline settings.
# Default values for omitted settings are read from the `logstash.yml` file.
# When declaring multiple pipelines, each MUST have its own `pipeline.id`.
#
# Example of two pipelines:
#
# - pipeline.id: test
# pipeline.workers: 1
# pipeline.batch.size: 1
# config.string: "input { generator {} } filter { sleep { time => 1 } } output { stdout { codec => dots } }"
# - pipeline.id: another_test
# queue.type: persisted
# path.config: "/tmp/logstash/*.config"
#
#- pipeline.id: news_table
# path.config: /opt/apps/logstash/config/addmysql.conf
#- pipeline.id: news_table3
# path.config: /opt/apps/logstash/config/addmysql3.conf
- pipeline.id: news
path.config: /opt/apps/logstash/config/news.conf
执行./bin/logstash
[root@localhost logstash]# ./bin/logstash
kibana常用查询
精确查询
GET /app-article-link/_search
{
"_source": ["id","title","source","customList","update_time","savePath","isDelete"],
"query": {
"bool": {
"must": [
{ "match": { "id": "15c7ee7a5dc411ea9bc2fa163e0c8256" }}
]
}}}
nested查询,mapping映射类型必须为nested
GET app-article-link/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "customList",
"query": {
"bool": {
"must": [
{ "match": { "customList.customId": "1" }},
{ "match": { "customList.secondLevel": "5552" }}
]
}}}}
]
}}}
自动补全查询,字段类型必须为completion
GET app-article-link/_search
{
"_source": ["source","title","detail"],
"suggest": {
"title_suggest": {
"prefix": "国家知识产",
"completion": {
"field": "title.suggest",
"size": 10,
"skip_duplicates": true
}
}
}
}
高亮查询
GET app-article-link/_search
{
"query": {
"multi_match": {
"query": "安徽",
"fields": ["title"]
}
},
"highlight": {
"pre_tags": "<span class='highLight'>",
"post_tags": "</span>",
"fields": {
"title": {}
}
}
}
最终通过Logstash导入的数据格式:
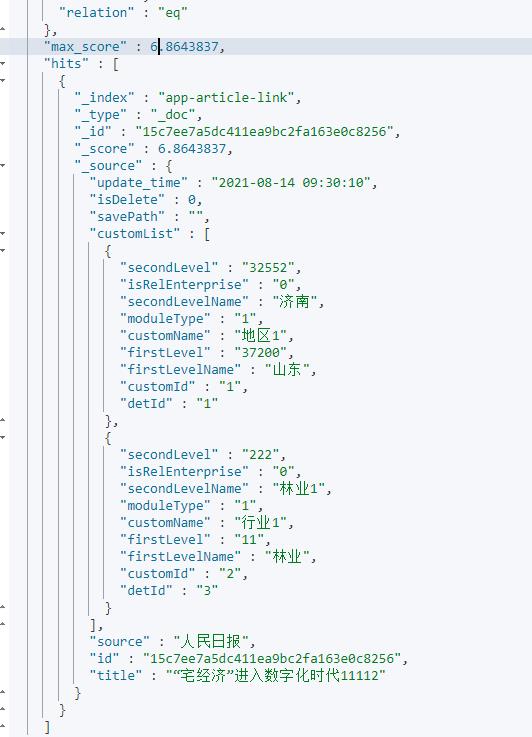
SpringBoot集成Elasticearch
搭建的Elasticsearch为7.8.1版本。
引入依赖
<!-- es搜索 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.1<以上是关于数据库 增量同步和全量同步 是啥的主要内容,如果未能解决你的问题,请参考以下文章