python构建 城市和省份字典 的实例应用
Posted aaaaaronqin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python构建 城市和省份字典 的实例应用相关的知识,希望对你有一定的参考价值。
1. 首先导入数据
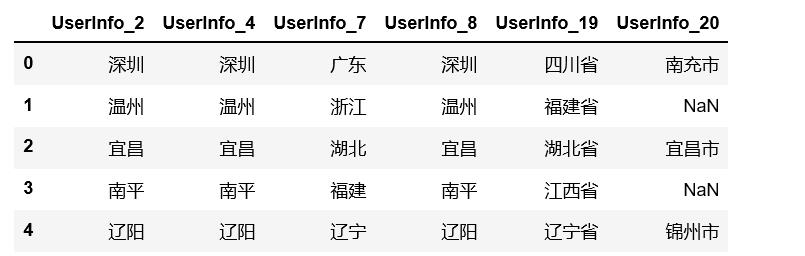
UserInfoData1 = pd.read_csv(\'data.csv\',encoding = \'GBK\') UserInfoData1.head()
数据长这个样子:
3. 统一格式,去掉后缀
# 去掉城市名称中的 “市” # UserInfoData1.UserInfo_20 = [x[0:-1] for x in UserInfoData1.UserInfo_20 if UserInfoData1.UserInfo_20.notnull().all()] # Length of values does not match length of index # 用此方法的时候,当把序列里面的单个缺失值拿出来的时候,不能判断是否为缺失值,因此转化为字符串判断 == ‘nan’ def delete_shi(s): str_s = str(s) if str_s==\'nan\': # AttributeError: \'str\' object has no attribute \'isnull\' return s else: if str_s[-1]==\'市\': return str_s[0:-1] else: return s UserInfoData1.UserInfo_20 = UserInfoData1.UserInfo_20.apply(lambda s: delete_shi(s)) UserInfoData1.UserInfo_8 = UserInfoData1.UserInfo_20.apply(lambda s: delete_shi(s))
4. 查看一下UserInfo_2为非缺失值时的情况
# UserInfo_2 为非缺失值 index=UserInfoData1[UserInfoData1.UserInfo_2.notnull() & UserInfoData1.UserInfo_4.isnull() & UserInfoData1.UserInfo_8.isnull() & UserInfoData1.UserInfo_20.isnull()].index UserInfoData1[UserInfoData1.UserInfo_2.notnull() & UserInfoData1.UserInfo_4.isnull() & UserInfoData1.UserInfo_8.isnull() & UserInfoData1.UserInfo_20.isnull()]
输出如下:
可以看到,在UserInfo_2为非缺失值时,其他数据有不同程度缺失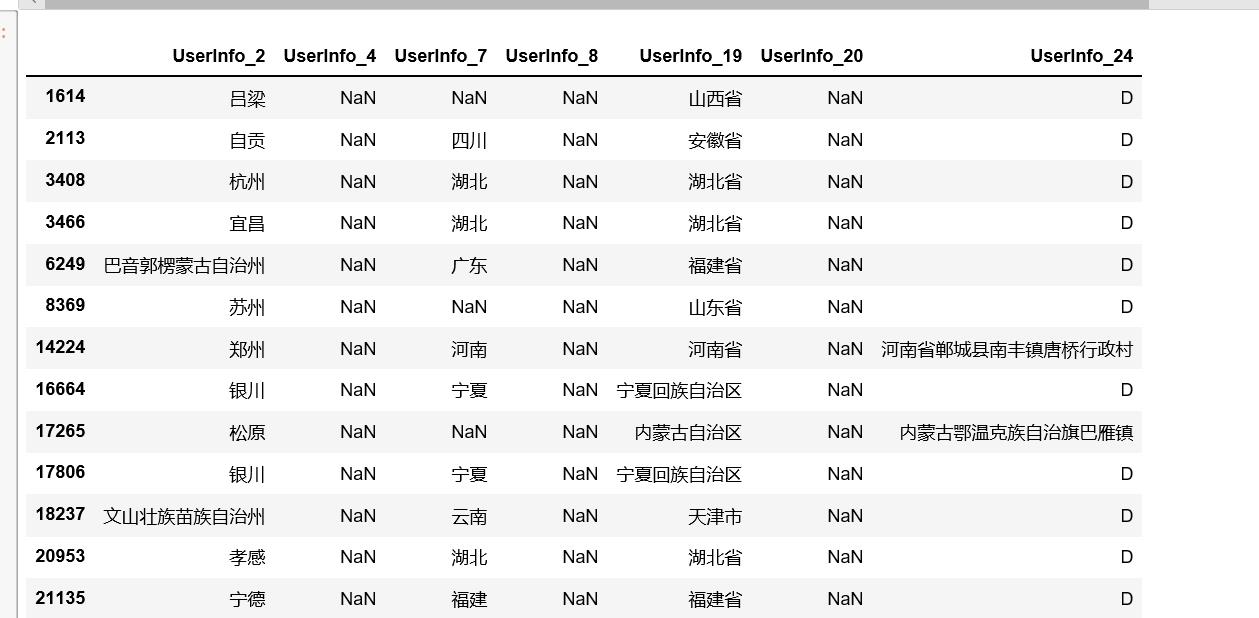
4. 我们以UserInfo_2填充UserInfo_4
# 填补UserInfo_4缺失值 UserInfoData1.UserInfo_4[index]=UserInfoData1.UserInfo_2[index]
5. 统一格式,去掉省份变量后缀
# 处理省份变量 def delete_postfix1(s,str): if s[-1]==str: return s[0:-1] else: return s def delete_postfix2(s,str): if s[0]==\'内\': return s[0:3] elif s[-3:]==str: return s[0:2] else: return s UserInfoData1.UserInfo_19 = UserInfoData1.UserInfo_19.apply(lambda s:delete_postfix2(s,\'自治区\')) UserInfoData1.UserInfo_19 = UserInfoData1.UserInfo_19.apply(lambda s:delete_postfix1(s,\'省\')) UserInfoData1.UserInfo_19 = UserInfoData1.UserInfo_19.apply(lambda s:delete_postfix1(s,\'市\'))
6. 格式统一好后,导入之前处理好的 城市-省份 对应字典
因为,字典中的城市并不全,且名称与数据中有出入,所以用数据更新字典
import pickle pickle_file = open(\'dicts.pkl\', \'rb\') my_list2 = pickle.load(pickle_file) pickle_file.close() my_list2.update({\'山东\':[\'济南\',\'青岛\',\'淄博\',\'枣庄\',\'东营\',\'烟台\',\'潍坊\',\'济宁\',\'泰安\',\'威海\',\'日照\',\'莱芜\', \'临沂\',\'德州\',\'聊城\',\'滨州\',\'荷泽\',\'菏泽\']}) my_list2.update({\'内蒙古\':[\'呼和浩特\',\'包头\',\'乌海\',\'赤峰\',\'通辽\',\'鄂尔多斯\',\'呼伦贝尔\',\'巴彦淖尔\',\'乌兰察布\', \'兴安盟\',\'锡林郭勒盟\',\'阿拉善盟\',\'巴彦淖尔盟\',\'乌兰察布盟\']}) my_list2.update({\'贵州\':[\'贵阳\',\'六盘水\',\'遵义\',\'安顺\',\'铜仁地区\',\'黔西南布依族苗族自治州\',\'毕节地区\', \'黔东南苗族侗族自治州\',\'黔南布依族苗族自治州\',\'黔南\',\'黔东南\',\'毕节\',\'铜仁\']}) my_list2.update({\'新疆\':[\'乌鲁木齐\',\'克拉玛依\',\'吐鲁番地区\',\'哈密地区\',\'昌吉回族自治州\',\'博尔塔拉蒙古自治州\',\'巴音郭楞蒙古自治州\',\'阿克苏地区\',\'克孜勒苏柯尔克孜自治州\', \'喀什地区\',\'和田地区\',\'伊犁哈萨克自治州\',\'塔城地区\',\'阿勒泰地区\',\'石河子\',\'阿拉尔\',\'图木舒克\',\'五家渠\',\'哈密\',\'阿克苏\']})
7. 根据UserInfo_4,UserInfo_7的数据填充UserInfo_8的数据
思路是:UserInfo_4是城市,UserInfo_7是省份,如果UserInfo_4属于UserInfo_7,那么认为UserInfo_8(城市)跟UserInfo_4大概率为一个城市
for c,p in zip(UserInfoData1.UserInfo_4,UserInfoData1.UserInfo_7): if str(p)==\'nan\': pass else: province = my_list2.get(p) if c in province: i = UserInfoData1[UserInfoData1.UserInfo_4==c].index UserInfoData1.UserInfo_8[i] = UserInfoData1.UserInfo_4[i]
当然,这个方法处理这个问题也不是特别合适,但如果遇到需要用城市判断省份,用县城判断城市,省份的时候还是大有可为的。
以上是关于python构建 城市和省份字典 的实例应用的主要内容,如果未能解决你的问题,请参考以下文章
Python 地图篇 - 使用pyecharts绘制世界地图中国地图省级地图市级地图实例详解
Python 地图篇 - 使用pyecharts绘制世界地图中国地图省级地图市级地图实例详解