Python工具箱系列(三十一)
Posted shanxihualu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python工具箱系列(三十一)相关的知识,希望对你有一定的参考价值。
 Neo4j是一个高性能的开源的,使用Java语言实现的NoSQL图数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。
Neo4j是一个高性能的开源的,使用Java语言实现的NoSQL图数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。
Neo4j是一个高性能的开源的,使用Java语言实现的NoSQL图数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。现实中很多数据都是用图来表达的,比如社交网络中人与人的关系、地图数据、或是基因信息等等。RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘。NoSQL数据库的兴起,很好地解决了海量数据的存放问题,图数据库也是NoSQL的一个分支,相比于NoSQL中的其他分支,它很适合用来原生表达图结构的数据。图数据库存储的结构就如同计算机科学中的数据结构中所论述的图,由顶点和边组成。
Neo4j适用于图形一类数据,例如:社会关系,公共交通网络,地图及网络拓扑。Neo4j并为此专门进行了算法优化,也开发了相关的查询语言。这是Neo4j与其他NoSQL数据库的最显著区别。Neo4j不适用于:
◆记录大量基于事件的数据(例如日志条目或传感器数据)
◆对大规模分布式数据进行处理,类似于Hadoop
◆二进制数据存储
◆适合于保存在关系型数据库中的结构化数据
Neo4j提供了免费的社区版本,在数据量不大的情况下,可以用于开发。大规模部署与应用建议购买企业版。在ubuntu bionic下的安装过程如下所示:
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add - echo \'deb https://debian.neo4j.com stable latest\' | sudo tee /etc/apt/sources.list.d/neo4j.list sudo apt-get update # 安装社区版本 sudo apt-get install -y neo4j # 安装企业版本 sudo apt-get install -y neo4j-enterprise systemctl status neo4j systemctl start neo4j systemctl enable neo4j # 直接在本地检测是否安装成功 curl http://localhost:7474/
同样的,缺省情况下是只接受本地访问要求,可以编辑/etc/neo4j/neo4j.conf文件增加"dbms.default_listen_address=0.0.0.0"这一行,随后重新启动服务即可远程访问:
sed -i \'$adbms.default_listen_address=0.0.0.0\' /etc/neo4j/neo4j.conf systemctl restart neo4j
以上使用sed命令增加了绑定地址,随后使用主流的浏览器(Edge,firefox,chrome)就可以访问数据库,如下图所示:
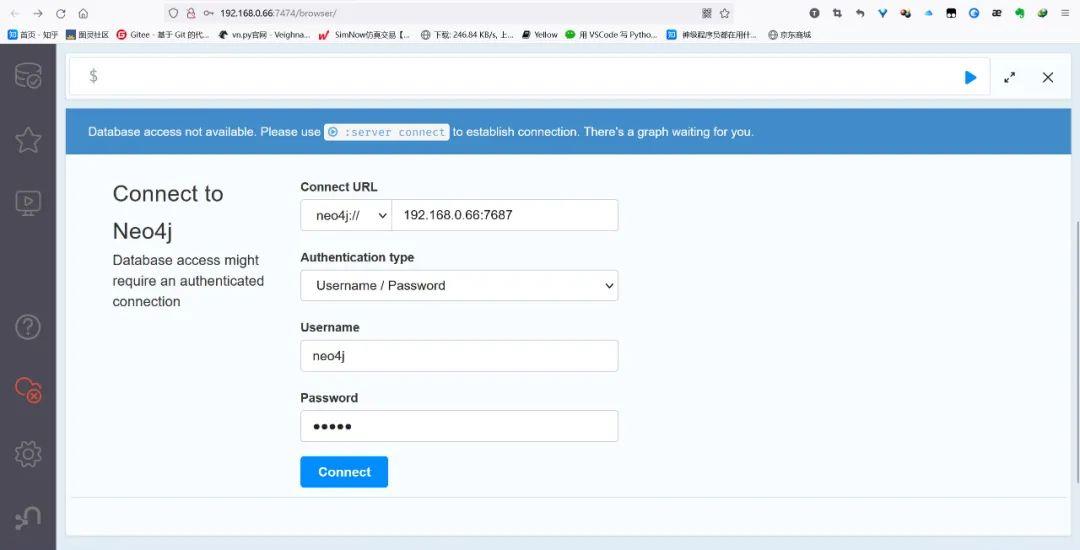
第一次访问时的缺省用户名与口令均是Neo4j,登录后需要修改。随后就进入到工作界面如下:
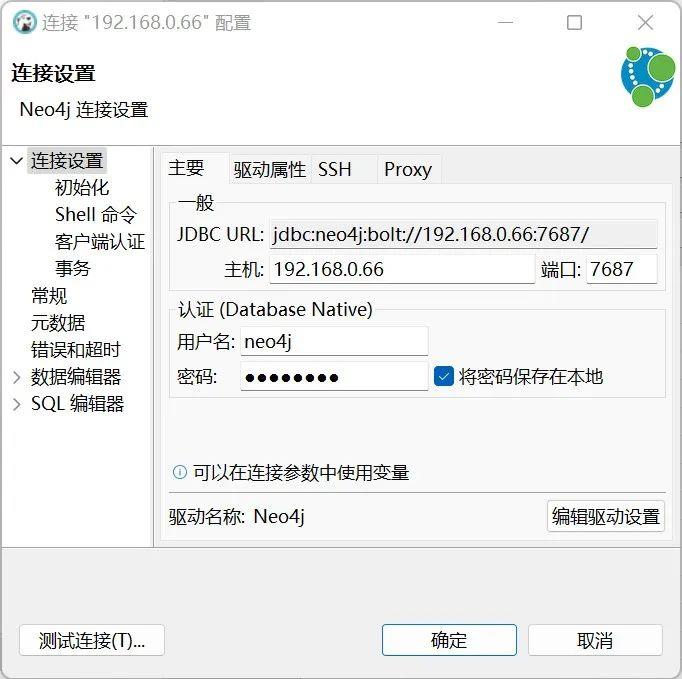
也可以使用传统的数据库客户端如DBeaver来访问Neo4j数据库。此时的连接属性设置如下图所示:
与SQL类似,Neo4j推出了专用于图的声明性文本查询语言Cypher。Cypher包含语句、关键词和表达式,比如谓词、函数等,其中很多大家都很熟悉(如WHERE,ORDER BY,SKIP LIMIT,AND,p.unitPrice > 10)。与SQL不同,Cypher完全是表达图模式的。添加了一个特殊子句MATCH来匹配数据中的这些模式。使用圆括号表示节点实体的圆,比如:(p:Product)。而关系的箭头使用-->来表达。Cypher语言在其它方面的重点是图概念,例如路径、可变长度路径、最短路径函数;列表上许多功能,操作和谓词的支持以及链接查询的功能。使用Cypher可以更新图结构和数据,甚至导入大量的CSV数据。通过用户定义的过程能够扩展语言。通过openCypher项目,Cypher已经成为一种现代图查询语言的开放标准,并且得到了多家数据库公司的支持。其语法可以参考[语法卡](https://neo4j.com/docs/cypher-refcard/current/)。
可以通过多种方式来访问Neo4j数据库:
◆ 使用命令行工具如Cypher shell等
◆使用主流的浏览器访问,Neo4j称为Neo4j browser
◆其它第三方工具软件
模仿movie graph,我们建立一个中文的图数据库。相关创建内容如下:
CREATE (Jiangshuying:Person name:\'江疏影\', born:1986) CREATE (胡哥:Person name:\'胡哥\', born:1982) CREATE (Jindong:Person name:\'靳东\', born:1976) CREATE (万莤:Person name:\'万莤\', born:1982) CREATE (Gentlemen:Teleplay title:"恋爱先生", released:2017) CREATE (NothingButThirty:Teleplay title:\'三十而已\', released:2020) CREATE (外科风云:Teleplay title:\'外科风云\', released:2017) CREATE (伪装者:Teleplay title:\'伪装者\', released:2015) CREATE (好先生:Teleplay title:\'好先生\', released:2016) CREATE (县委大院:Teleplay title:\'县委大院\', released:2022) CREATE (Jiangshuying)-[:ACTED_IN roles:[\'江莱\']]->(好先生) CREATE (Jiangshuying)-[:ACTED_IN roles:[\'罗钥\']]->(Gentlemen) CREATE (Jiangshuying)-[:ACTED_IN roles:[\'王漫妮\']]->(NothingButThirty) CREATE (Jindong)-[:ACTED_IN roles:[\'庄恕\']]->(外科风云) CREATE (Jindong)-[:ACTED_IN roles:[\'明楼\']]->(伪装者) CREATE (Jindong)-[:ACTED_IN roles:[\'Boss\']]->(Gentlemen) CREATE (胡哥)-[:ACTED_IN roles:[\'明台\']]->(伪装者) CREATE (胡哥)-[:ACTED_IN roles:[\'梅晓哥\']]->(县委大院) CREATE (万莤)-[:ACTED_IN roles:[\'徐丽\']]->(好先生)
此时形成的知识图谱如下所示:
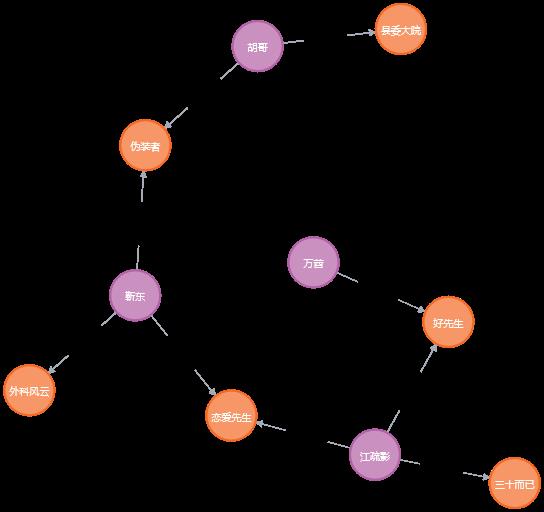
由此可见Neo4j对中文的支持非常好,可以混合用中英文来建立自己的知识图谱。下面的代码显示了,寻找万莤与胡哥间相互认识的最短路径。
match p=shortestpath((:Person name:\'江疏影\')-[*]-(:Person name:\'胡哥\')) return p
查询结果如下图所示:
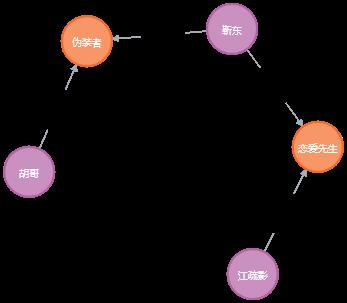
当然这只是一个示例,因为并没有真正梳理每个人的关系,仅仅是从现有的知识中计算出来的。对于知识图谱来说,信息越充分,威力越巨大。
需要注意的是,以上命令必须一次性输入执行完成,否则就会出现看起来是一样的节点,但Neo4j会认为是不同的对象,从而形成意料之外的节点与关系。
Python操作知识图谱
安装了Py2neo就可以使用Python操作Neo4j了。我们也就可以在线处理大规模的数据,实现知识图谱的自动构建了。安装方法非常简单,直接在cmd中输入下列命令即可:
pip install py2neo
以下代码创建了一个极简的知识图谱,如下图所示:
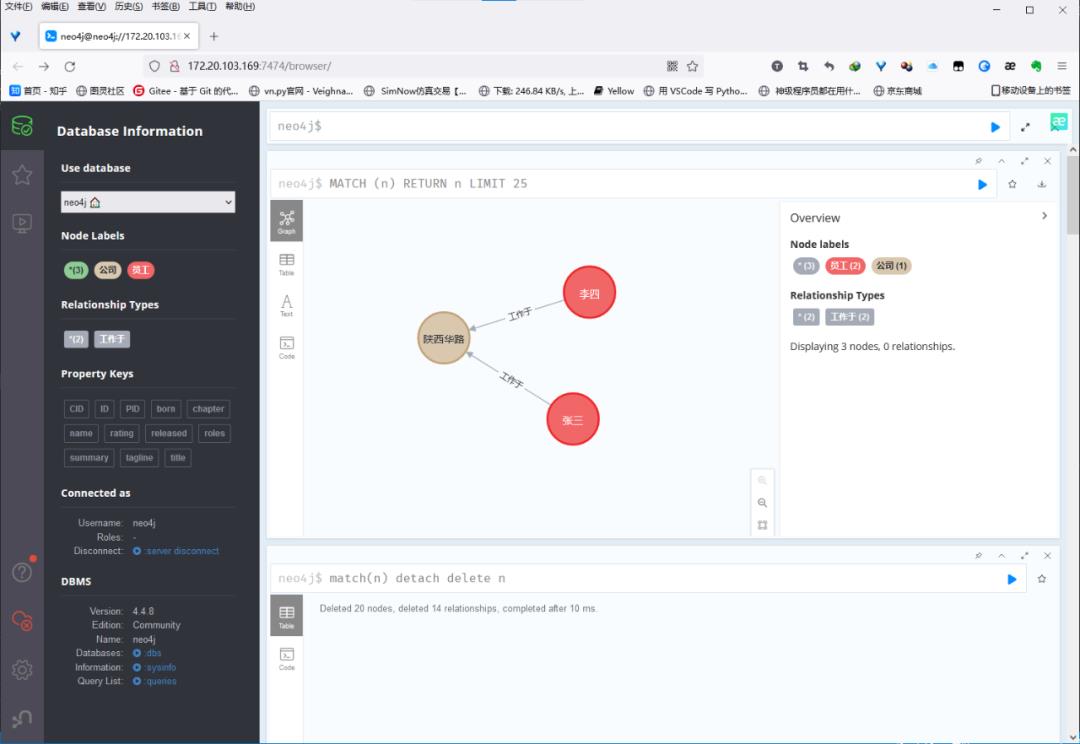
示例代码如下所示:
from py2neo import Node, Relationship, Graph, NodeMatcher, RelationshipMatcher # 远端NEO4J服务器 test_graph = Graph(\'http://172.20.103.169:7474\',auth=(\'neo4j\',\'88488848\')) A = Node("员工", name="张三", PID = 100) B = Node("员工", name="李四", PID = 100) C = Node("公司", name="西安衍舆", CID = 99) test_graph.create(A) test_graph.create(B) test_graph.create(C) test_graph.create(Relationship(A, "工作于", C)) test_graph.create(Relationship(B, "工作于", C)) print(test_graph.nodes.match(\'员工\').all())
从图中可以看出,Neo4j对于中文的支持是非常好的。能够以非常符合中文习惯的方式写出相关知识。真正能够实用的知识图谱必须是日积月累的过程,有了称手的工具后,知识本身的正确性才是重点。
python学习第三十一节
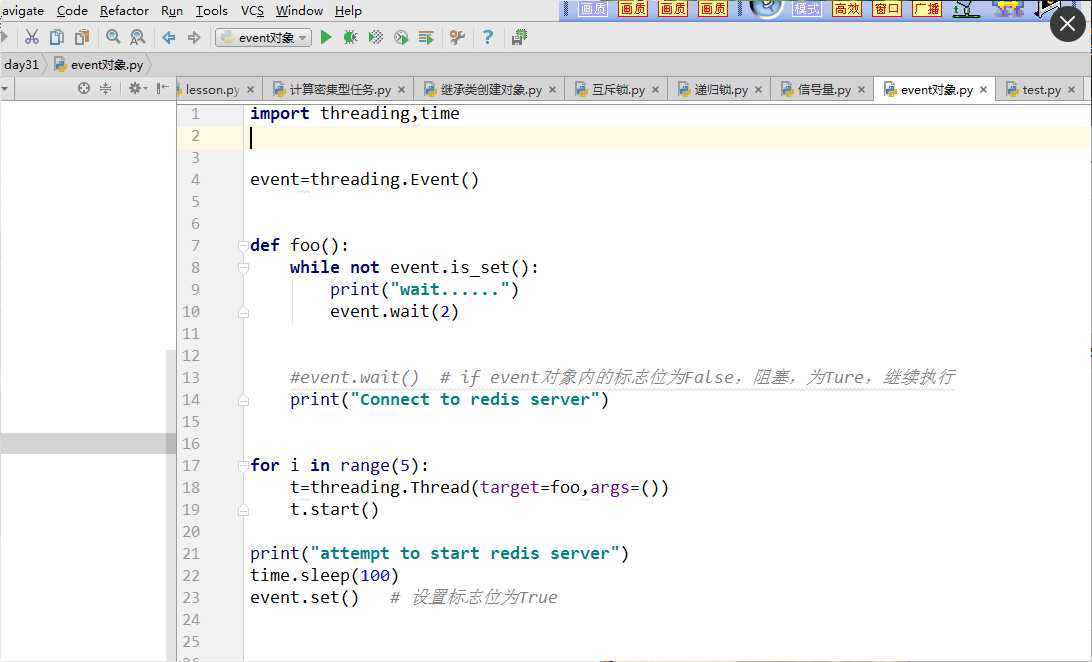
event模块
event.wait() 等待相当于标志位为False。()内可以传参数数字,为几秒。
event.set()给另一个线程传标志位True。
队列 queue
和列表类似,但是函数内置了互斥锁,保证了线程安全。是具有线程安全的数据结构。
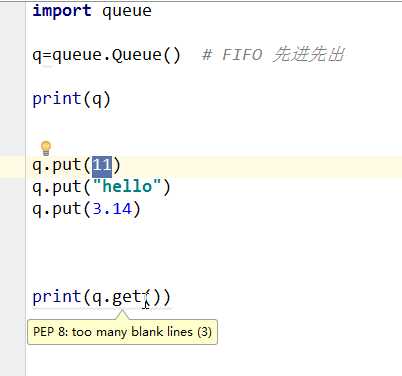
put传进去,get取出来,取是先进先出的方法,吃了拉,而且queue没有别的方法。
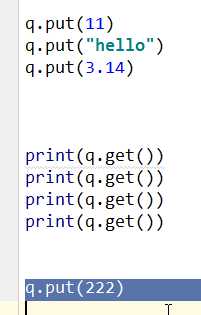
上图这种情况没有意义,最后一次get取不到值在等待put 单线程写到后面的put并不能运行,需要再
开一个线程。
取值之后,queue就少了一个。
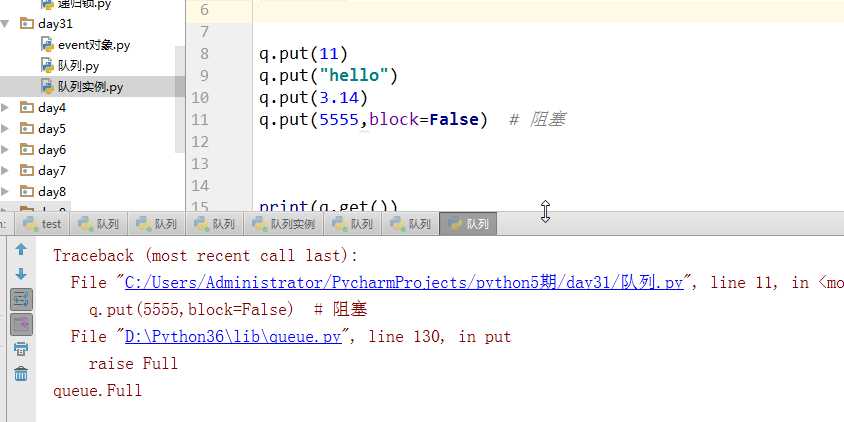
如上图put里写block=False参数,当queue满了在添加,将报错而不是卡死。
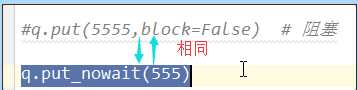
上图如上上图效果一样,写法不一样。
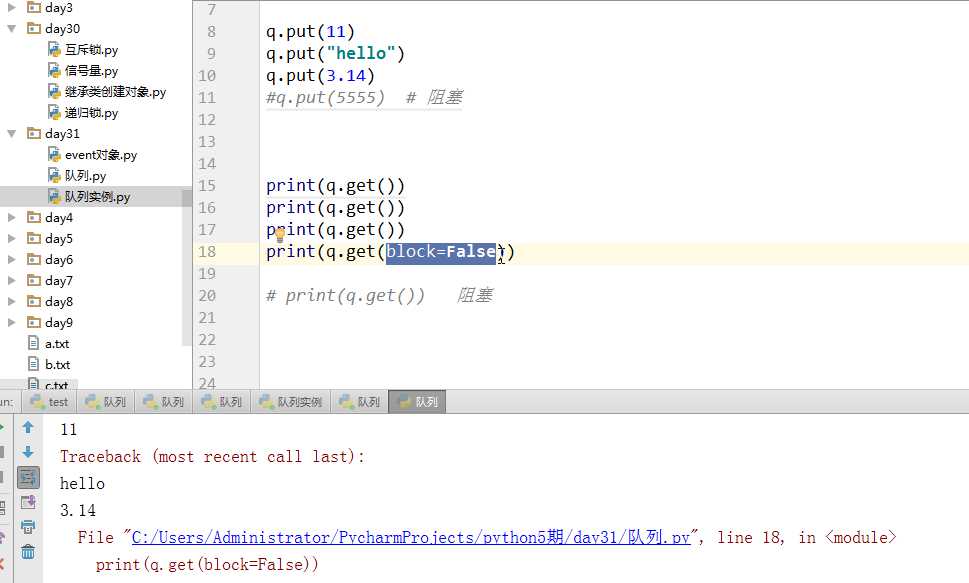
如上图,get参数可以写block=False 当取不到值的时候立刻报错。
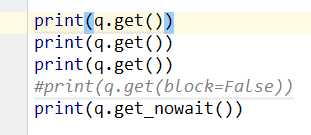
上图和上上图效果一样,写法不一样。
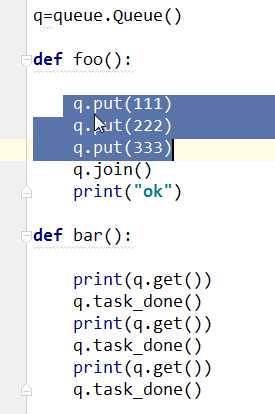
put之后加入一个join可以阻塞该子线程后面的程序,然后另一个线程取出来需要每次都要task_done()
表示执行完毕,当所有任务完成之后会继续上一个线程的后面任务。
q.empty()
如果queue为空布尔值为True
priority优先级
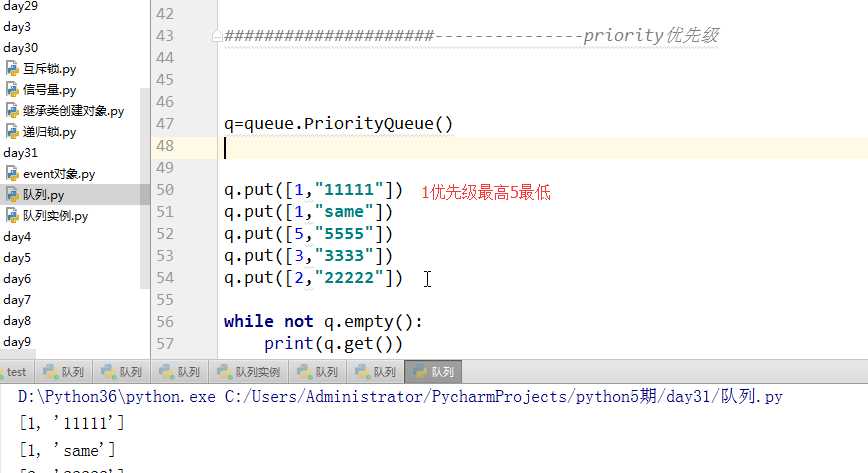
如上图,设置优先级的例子。


生产者消费者模型

多进程
1 from multiprocessing import Process#import 2 import os 3 import time 4 5 6 def info(name): 7 ‘‘‘打印父进程PID和进程PID‘‘‘ 8 print("name:", name)#打印名字 9 print(‘parent process:‘, os.getppid())#获取父进程ID 10 print(‘process id:‘, os.getpid())#获取子进程ID 11 print("------------------") 12 time.sleep(1) 13 14 15 def foooooo(name): 16 ‘‘‘调用info‘‘‘ 17 info(name) 18 19 20 if __name__ == ‘__main__‘: 21 info(‘main process line‘) 22 23 process_one = Process(target=info, args=(‘alvin‘,))#创建一个进程 24 process_two = Process(target=foooooo, args=(‘egon‘,)) 25 process_one.start()#激活这个进程 26 process_two.start() 27 28 process_one.join()#进程的join和线程的join是一样的,子进程运行结束之后运行主进程 29 process_two.join() 30 31 print("ending")#主进程
多进程的联系。
以上是关于Python工具箱系列(三十一)的主要内容,如果未能解决你的问题,请参考以下文章