译:从分布式微服务到单体
Posted IAyue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了译:从分布式微服务到单体相关的知识,希望对你有一定的参考价值。
从分布式微服务架构迁移到整体式应用程序有助于实现更高的规模、弹性并降低成本。
在Prime Video,我们为客户提供数千个直播流。为了确保客户无缝接收内容,Prime Video设置了一个工具来监控客户观看的每个流。该工具使我们能够自动识别感知质量问题(例如,块损坏或音频/视频同步问题)并触发修复过程。
我们在Prime Video的视频质量分析(VQA)团队已经拥有了一个用于音频/视频质量检查的工具,但我们从未打算也没有设计过它大规模运行(我们的目标是监控数千个并发流并随着时间的推移而增加这个数字)。在将更多流载入服务时,我们注意到大规模运行基础结构非常昂贵。我们还注意到扩展瓶颈,使我们无法监控数千个流。因此,我们退后一步,重新审视了现有服务的体系结构,重点关注成本和扩展瓶颈。
我们服务的初始版本由由 AWS Step Functions 编排的分布式组件组成。就成本而言,两个最昂贵的操作是业务流程工作流和数据在分布式组件之间传递的时间。为了解决这个问题,我们将所有组件移动到单个进程中,以将数据传输保留在进程内存中,这也简化了编排逻辑。由于我们将所有操作编译到单个进程中,因此我们可以依靠可扩展的 Amazon Elastic Compute Cloud (Amazon EC2) 和 Amazon Elastic Container Service (Amazon ECS) 实例进行部署。
分布式系统开销
我们的服务由三个主要部分组成。
- 媒体转换器将输入音频/视频流转换为发送到检测器的帧或解密的音频缓冲区。
- 缺陷检测器执行实时分析帧和音频缓冲区的算法,以查找缺陷(例如视频冻结、块损坏或音频/视频同步问题),并在发现缺陷时发送实时通知。有关此主题的更多信息,请参阅我们的 Prime Video 如何使用机器学习来确保视频质量一文。
- 第三个组件提供控制服务中流的业务流程。
我们将最初的解决方案设计为使用无服务器组件(例如 AWS Step Functions 或 AWS Lambda)的分布式系统,这是快速构建服务的不错选择。从理论上讲,这将允许我们独立扩展每个服务组件。但是,我们使用某些组件的方式导致我们在预期负载的 5% 左右达到了硬扩展限制。此外,所有构建块的总体成本都太高,无法大规模接受解决方案。
下图显示了我们服务的无服务器体系结构。
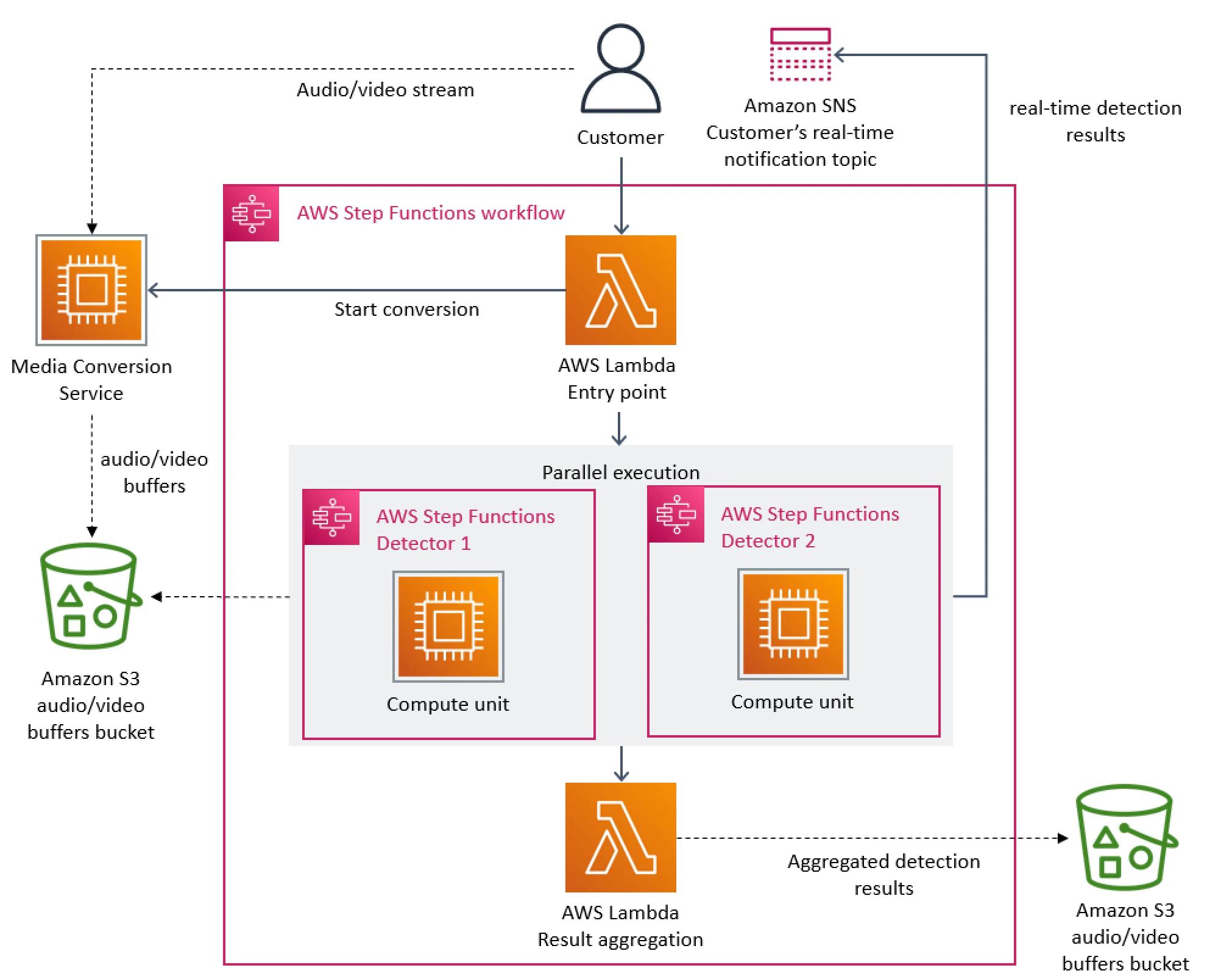
架构中的主要扩展瓶颈是使用 AWS Step Functions 实施的编排管理。我们的服务对流的每一秒执行了多次状态转换,因此我们很快就达到了帐户限制。除此之外,AWS Step Functions 还按状态转换向用户收费。
我们发现的第二个成本问题是关于我们在不同组件之间传递视频帧(图像)的方式。为了减少计算成本高昂的视频转换作业,我们构建了一个微服务,将视频拆分为帧,并将图像临时上传到 Amazon Simple Storage Service (Amazon S3) 存储桶。然后,缺陷检测器(其中每个缺陷检测器也作为单独的微服务运行)下载图像并使用 AWS Lambda 同时处理它。但是,对 S3 存储桶的大量 Tier-1 调用成本很高。
从分布式微服务到单体应用程序
为了解决瓶颈问题,我们最初考虑单独修复问题,以降低成本并提高扩展能力。我们进行了试验并做出了一个大胆的决定:我们决定重新构建我们的基础设施。
我们意识到分布式方法在我们的特定用例中并没有带来很多好处,因此我们将所有组件打包到一个流程中。这消除了对 S3 存储桶作为视频帧中间存储的需求,因为我们的数据传输现在发生在内存中。我们还实现了控制单个实例中的组件的编排。
下图显示了迁移到整体架构后的系统体系结构。
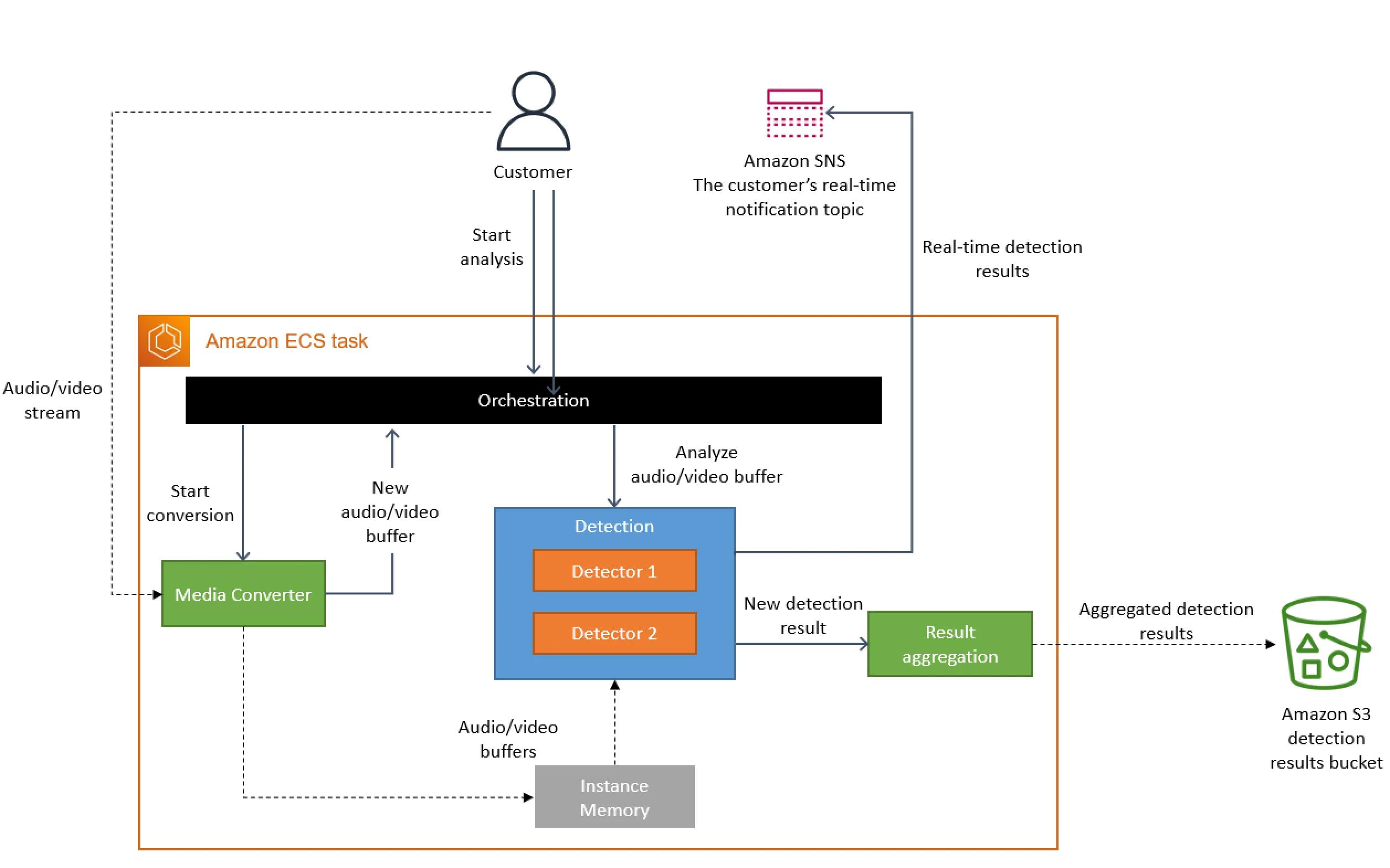
从概念上讲,高级体系结构保持不变。我们仍然拥有与初始设计(媒体转换、检测器或编排)完全相同的组件。这使我们能够重用大量代码并快速迁移到新架构。
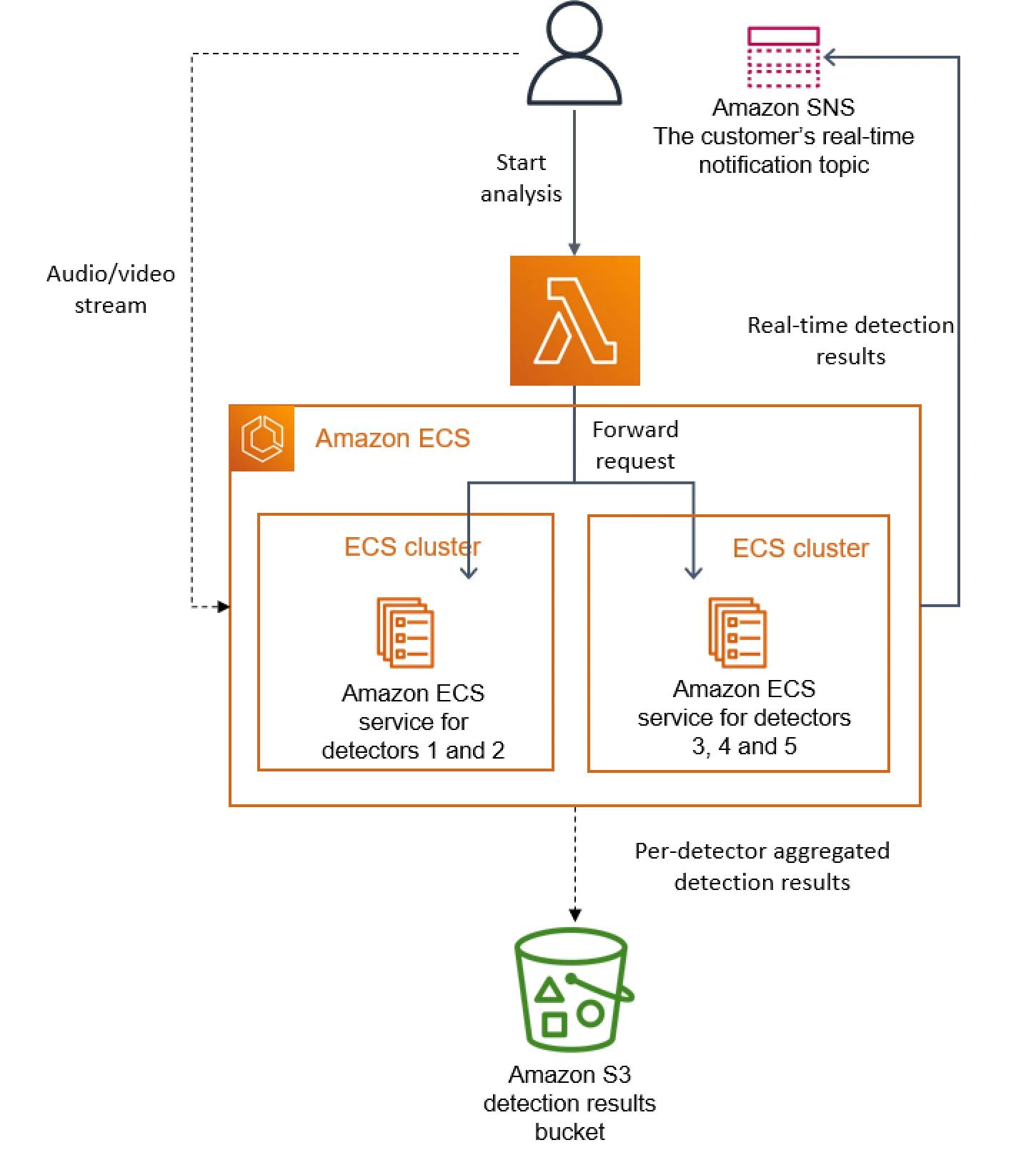
在初始设计中,我们可以水平扩展多个检测器,因为它们中的每一个都作为单独的微服务运行(因此添加新检测器需要创建一个新的微服务并将其插入业务流程)。然而,在我们的新方法中,探测器的数量只能垂直缩放,因为它们都在同一实例中运行。我们的团队会定期向服务中添加更多检测器,我们已经超出了单个实例的容量。为了克服这个问题,我们多次克隆服务,用不同的检测器子集对每个副本进行参数化。我们还实现了一个轻量级编排层来分发客户请求。
下图显示了我们在超出单个实例容量时部署检测器的解决方案。
结果和要点
微服务和无服务器组件是可以大规模工作的工具,但是否在整体式架构上使用它们必须根据具体情况进行。
将我们的服务迁移到整体式架构可将我们的基础架构成本降低 90% 以上。它还提高了我们的扩展能力。今天,我们能够处理数千个流,我们仍然有能力进一步扩展服务。将解决方案迁移到 Amazon EC2 和 Amazon ECS 还使我们能够使用 Amazon EC2 计算节省计划,这将有助于进一步降低成本。
我们做出的一些决定并不明显,但它们带来了重大改进。例如,我们复制了一个计算成本高昂的媒体转换过程,并将其放置在更靠近检测器的位置。虽然运行一次媒体转换并缓存其结果可能被认为是更便宜的选择,但我们发现这不是一种经济高效的方法。
我们所做的更改使Prime Video能够监控客户观看的所有流,而不仅仅是观看人数最多的流。这种方法可以带来更高的质量和更好的客户体验。
本文来自博客园,作者:IAyue,转载请注明原文链接:https://www.cnblogs.com/zmj-pr/p/17391507.html
单体架构,集群架构,SOA架构,分布式微服务架构
演变过程
一. 单体应用架构
为什么要用单体架构?
单体架构的特点就是:所有的业务功能都在一个项目里面 逻辑也简单 还不贵 适合于小型项目。
在以前计算机才刚刚普及的时候,那个时候基本上都是单体项目架构,因为简单还实用,那个年代能上网的才有多少人无非都是家里有钱的或者是体制内的上个班以前是喝杯茶看看报纸现在是喝杯茶看看电脑,所以能够真正上的了网的人很少,那么用单体应用架构完全够了
那么单体架构又是什么呢?
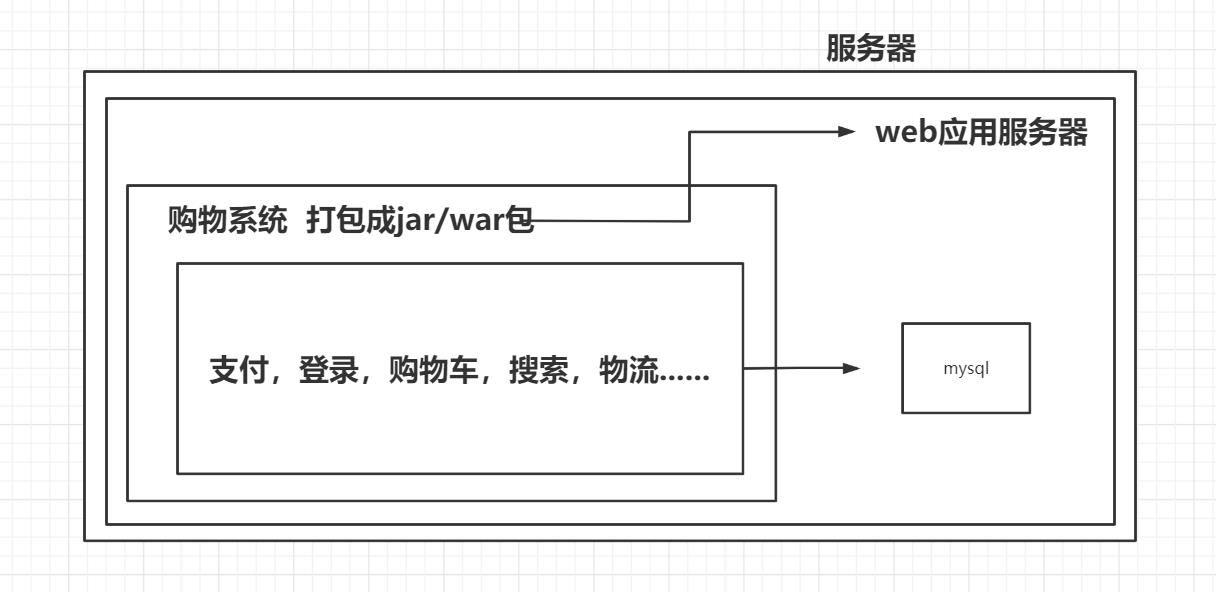
一个典型的单体应用就是将所有的业务处理功能都放在一个工程中,最终经过编译、打包,部署在一台服务器上。
通俗点讲就是你整个项目都运行在一个web应用服务器上,然后这整个web应用服务器又运行在一个服务器上
但是随着时代的发展计算机的普及 越来越多的人有了可以上网的权力 这个时候 单体架构的弊端出来了
举个栗子:
某企鹅 在它刚创建的那时候基本上是没什么人用的大概顶多500应该,后面随着越来越多人有电脑,在加上我们某马哥坚持不懈的陪用户聊天
某企鹅的使用用户也越来越多了起来,但也随之带来的就是单体架构的弊端
用户越来越多,访问量越来越大,也就是CPU运行内存打满,服务器响应缓慢,带宽被用尽,一开始我们是采取的更新服务器硬件配置 和提升带宽
带宽是什么?
宽带是一种相对的描述方式,频带的范围愈大,也就是带宽愈高时,能够发送的数据也相对增加。譬如说在无线电通信上,频率范围比较窄的带宽只能发送摩尔斯电码,发送高质量的音乐就需要较大的带宽。
比如说你这个服务器最大能接受的带宽是多少 然后如果访问量大于你这个临界点就会404 或者 ○加载中
这个时候我们是怎么解决的呢?
垂直扩容 更新服务器配置和提升带宽,
好解决完了老板非常开心给奖励你5000奖金,然后你开开心心的拿着奖金开始摸鱼了
但这只是能缓解我们的燃眉之急…
因为当时的服务器硬件配置也就那样,就算你把服务器升到顶配也还是会有一个天花板 万一你的访问量到了天花板呢?超过了服务器所能承受的访问量呢 假如1000万人访问会怎么样怎么办…
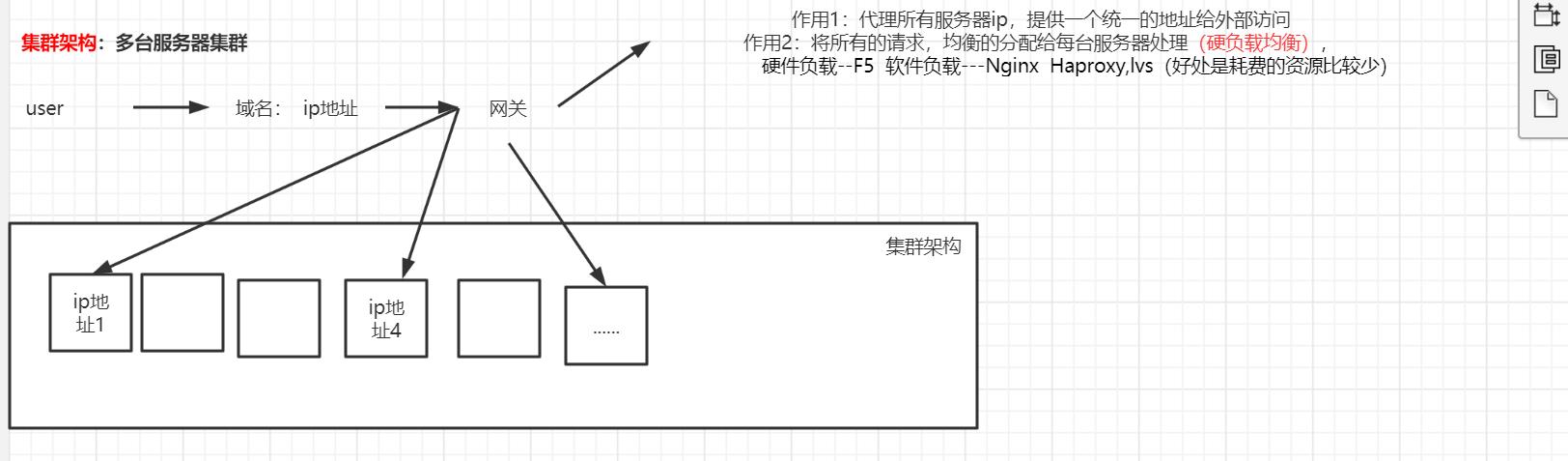
水平扩容(集群架构)
分流,将很多服务器集中起来一起进行同一种服务,在客户端看来就像是只有一个服务器,主要是分散压力。
相当于同一个工程代码拷贝多份部署到多台服务器,每台服务器单独独立部署运行。
他是怎么解决我们的前面两个问题的呢?
设置多台服务器多台服务器都拥有自己独立的ip地址,那这肯定很麻烦如果是按照记ip地址才能访问的话你肯定要记很多0.0.0.0 — 255.255.255.255
所以我们提供了一个东西叫 ”域名“ ,域名代理了所有服务器的IP地址,提供一个统一的访问地址给外界进行访问
但这个时候又有了一个问题所有的用户都访问我这一个域名 那我怎么进行分配呢?
负载均衡
负载均衡(Load
Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。
硬负载均衡又分为硬件负载均衡和软件负载均衡
硬件负载均衡是靠负载均衡器来实现的
负载均衡设备:将用户访问的请求,根据负载均衡算法,分发到集群中的一台处理服务器。(一种把网络请求分散到一个服务器集群中的可用服务器上去的设备)
软件负载均衡是靠软件来的
指在服务器的操作系统上,安装软件,来实现负载均衡,如Nginx负载均衡。它的优点是基于特定环境、配置简单、使用灵活、成本低廉,可以满足大部分的负载均衡需求。
软件负载均衡器有:Lvs ,Nginx,Haproxy
好解决完了老板非常开心给奖励你1万奖金,然后你开开心心的拿着奖金又开始摸鱼了
但这个时候又有一个问题出来了假如我有一个亿的用户呢?
难不成还用这思想去解决问题?
那假如我一个亿的用户,市面上好的服务器我们来大概一下一台好的服务器咱们就算他200万好吧,一台好的可以解决五百万的用户量,算算多少钱
这应该有几个小目标了吧,这你 这钱都进老板兜里了难不成还让他掏出来这他肯定是不愿意的呐对吧。
老板说 这你要搞不好你就可以走人了,怎么办咱也没办法为了不被炒鱿鱼咱只能想办法呗
SOA架构
什么是SOA架构这东西每个人的理解都不一样但是每个人的理解都差不多比较抽象
我的理解来说就是
把一个项目按照功能来拆分成对多个独立的项目,
在根据使用频繁的业务服务来对其进行集群架构
这里支付用户访问量比其他的多的多所以我们就可以使用集群架构
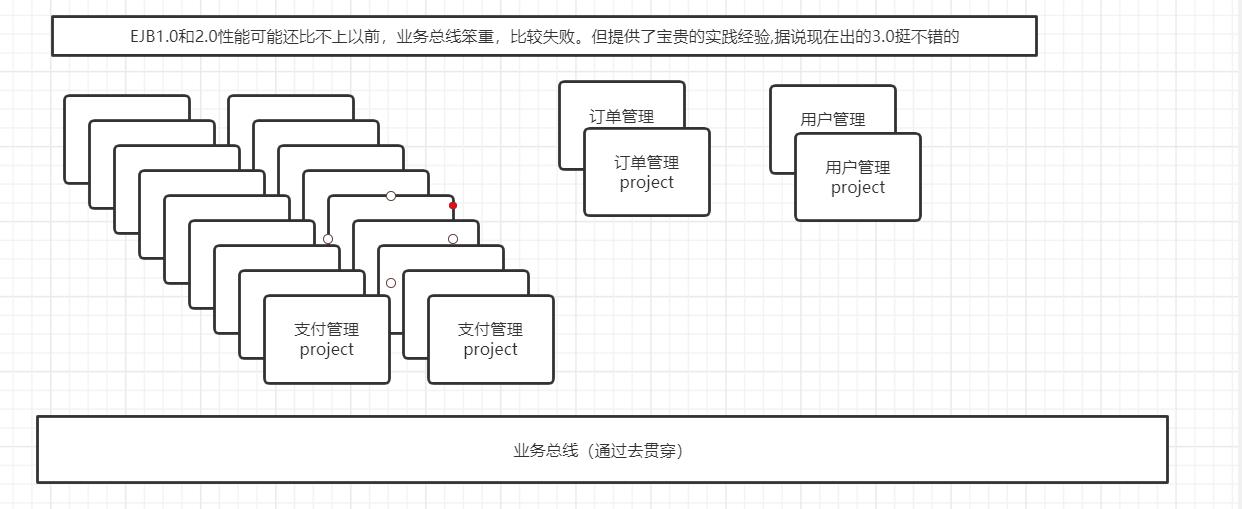
但是你把每个实际业务都区分成独立的项目时候,但各个业务总会有那么一些交互的区域 比如说你 用户要看他这个用户的订单是不是用户管理就和订单管理交互起来了。
这些交互的区域相互调用非常凌乱,这个时候前辈开发了EJB EJB里面实践了业务总线这个概念,这个经验是非常宝贵的他帮助我们把这些交互的区域统一起来了,在EJB1版本到2版本的时候也可以算是不成功的但也又是成功的,不成功是因为性能不好业务总线太过笨重,好是他提供了宝贵的实际经验。
好了这个时候你解决了集群架构的缺点 老板又又给你奖励了你又又可以开开心心摸鱼了
过了几天由于业务总线太过于笨重有时候效率和不弄SOA差不多 老板又来找你了
你又开始了你那苦逼的生活…
分布式微服务架构
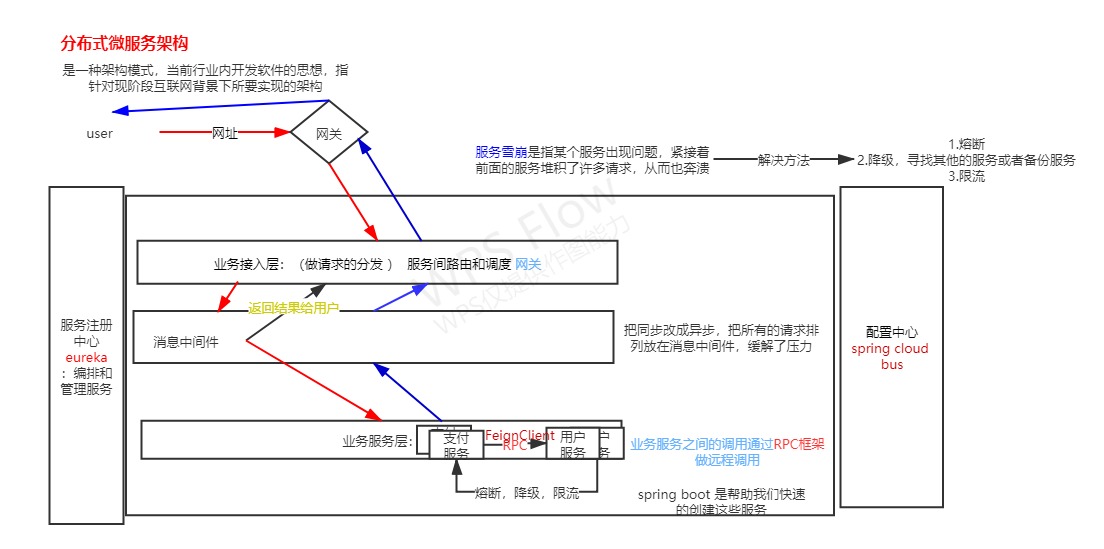
为了解决前面提到的业务总线过于笨重的问题,分布式微服务架构去掉了业务总线去掉了中心化。
分布式微服务架构也是当前行内开发软件的思想,指针对现阶段互联网背景下所需要的架构
而且相比于前面而言
微服务是真正的分布式的、去中心化的。把所有的“思考”逻辑包括路由、消息解析等放在服务内部,去掉一个大一统的 ESB,服务间轻通信,是比SOA更彻底的拆分。
分布式微服务架构强调的重点是业务系统需要彻底的组件化和服务化,原有的单个业务系统会拆分为多个可以独立开发,设计,运行和运维数据的小应用,这些小应用之间通过服务完成交互和集成。
可以分为六个组件
- 业务接入层:
(请求的分发):服务间路由和调度网关
- 业务服务层:
各个功能模块服务 比如:支付,用户,订单
- 服务注册中心:
提供服务的注册和发现以及编排和管理的功能,维护一个可用分的服务列表,当你在服务层上线了一个服务后必须要先在服务注册中心注册一下 和我们签到是一个意思 至于为什么后面会讲 我在这里就不多说了
- RPC:
(远程工程的调用):每个独立的服务项目之间的调用
- 配置中心:
将配置的参数统一管理的场所
- 消息中间介:
记录用户发起的请求,各个服务可以通过定时任务或者自由访问消息中间介中的请求。
服务器雪崩:
服务器雪崩是一个很严重的问题,是怎么来的呢?
由于你支付管理的这个服务器,天灾人祸了 总而言之就是挂掉了没了访问不了,怎么办你这个支付管挂掉了,那么需要请求支付管理来进行数据交互的时候就请求不到,假如是订单管理购买个东西肯定有订单 对吧肯定要支付但是你支付这个时候挂掉了怎么办?
请求肯定是请求不到了,就和几个月之前的b站一样的结果
而然你这个时候还有可能刷新一下 没有雪中送炭还来了一波补刀 你每刷新一次就多了一个请求在加上不可能就你一个访问不到而是所有人都访问不到那么请求就会越来越多越来越多 到最后订单管理也撑不住了请求堆积太多了 超过了他所能接受的范围 所以他也挂掉了,然后蝴蝶效应他后面的噼里啪啦也全部挂掉了 爽不爽起不起飞
那么有问题肯定就有解决的办法,俗话说得好只要思想不滑坡,方法总比困难多 那么到底怎么解决呢?
三大剑客
- 熔断
当他发现了某个服务器挂掉的时候就把他的电路断开,不要让他可以继续访问,也不让正常的流程去访问这个挂掉的服务
- 降级
找一个替代品 可以是支付管理的备份,也可以是其他正常的服务
- 限流
字面意思 主要是限制访问数量 辅助前面两个 来给服务器雪崩提供解决时间
分布式微服务框架
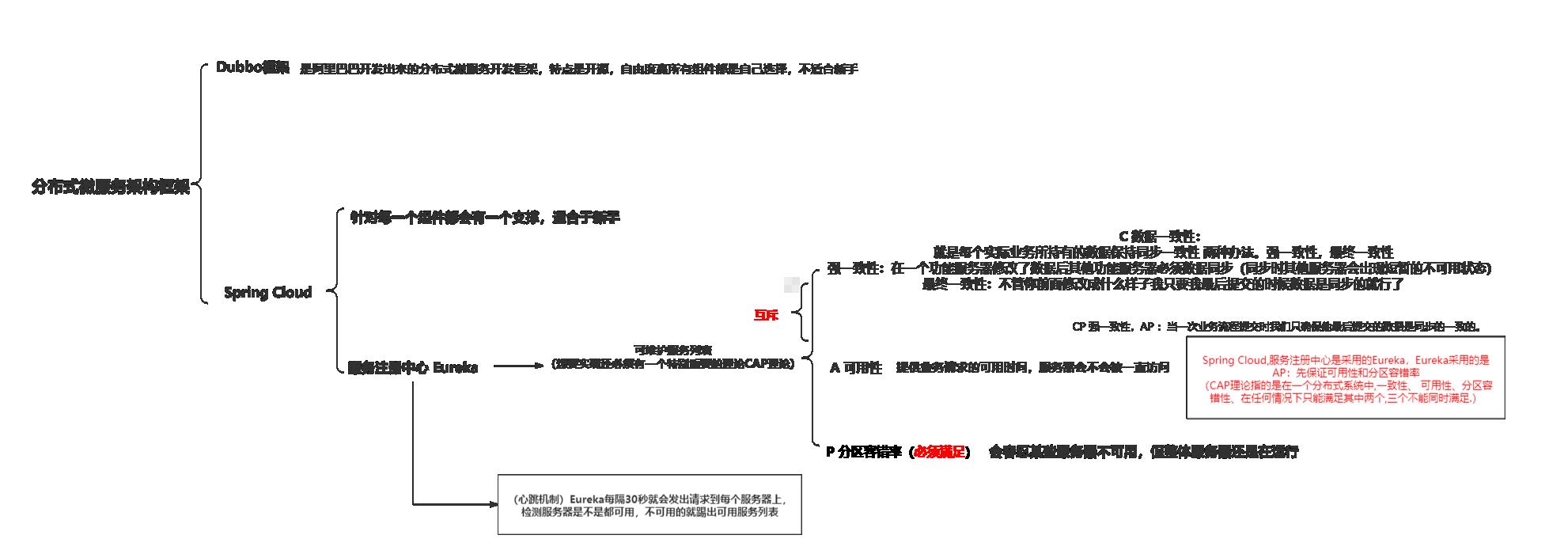
CAP理论是什么?为什么想实现可维护列表需要CAP
而也因为分布式微服务架构 是一个真正的分布式架构项目里的功能模块都是独立开来的包括数据也是独立的,这就会造成什么结果数据不同步,假如我
用户管理修改了年龄但由于我其他的功能模块是独立的数据所以就不同步这就是一个很严重的问题那么…
咱们就要用到CAP理论了
- C 数据一致性:
分为强数据一致性和最终数据一致性,强数据一致性就是当你在某个服务中修改了数据 那么其他服务就必须将数据同步(数据同步时会造成短暂的不可访问状态),最终一致性 字面意思 就是最终提交的数据我要他是数据同步
不管你前面改了啥 反正我最后提交的时候要数据同步提交
- A 可用性
提供业务访问的可用时间,就是你服务是不是可用一直开着可用一直访问
一般都是999 99999 这样子 一个礼拜停那么一两个小时或者一个月停那么一两个小时 可以率99%
- P 分区容错率(必须满足)
会容忍某个服务不可用 但是不影响整体服务器的运行
可以看出来 可用性和数据一致性 是互斥的 因为你想要数据一致性就必须要停一会服务 让他数据同步 这样就会降低可用性 所以我们一般都是在这两个选择一个 然后在选上一个必选的分区容错率
对于新手而已 Spring Cloud 他的服务注册中心是用的Eureka 而Eureka 所选择的是AP 也就是先可用性和分区容错率
我只是把我知道的总结出来当做笔记防止以后不记得了可以看看所以欢迎各位大哥指点小弟哪里写的不好
有时间会持续更新…
以上是关于译:从分布式微服务到单体的主要内容,如果未能解决你的问题,请参考以下文章