catboost原理以及Python代码
Posted 嘟嘟_猪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了catboost原理以及Python代码相关的知识,希望对你有一定的参考价值。
原论文:
http://learningsys.org/nips17/assets/papers/paper_11.pdf
catboost原理:
One-hot编码可以在预处理阶段或在训练期间完成。后者对于训练时间而言能更有效地执行,并在Catboost中执行。
类别特征:
为了减少过拟合以及使用整个数据集进行训练,Catboost使用更有效的策略。
1、对输入的观察值的集合进行随机排列,生成多个随机排列;
2、给定一个序列,对于每个例子,对于相同类别的例子我们计算平均样本值;
3、使用如下公式将所有的分类特征值转换为数值:
让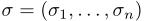 ,那么
,那么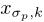 可以代替为
可以代替为
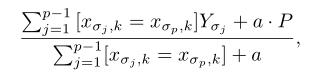
在这里,我们还增加了先验值P和参数a>0,即为先验的权重。添加先验是一种常见的做法,它有助于减少从低频类别获得的噪声。
特征组合:
在数据集中,组合的数量随类别特征个数成指数型增长,在算法中不太可能考虑所有。在当前树考虑新的拆分时,Catboost以贪婪的方式考虑组合。
1、 第一次分裂不考虑任何组合在树上;
2、 对于下一次分类,在有所有类别特征的数据集的当前树,Catboost包含了所有的组合和分类特征。组合值即被转换为数字;
3、 Catboost还以以下方式生成数值和类别特征的组合:在树中选择的所有分裂视为具有两个值的类别,并在组合中也类似使用。
python代码:
import catboost
model = CatBoostClassifier(iterations=17000,
# depth = 6,
learning_rate = 0.03,
custom_loss=\'AUC\',
eval_metric=\'AUC\',
bagging_temperature=0.83,
od_type=\'Iter\',
rsm = 0.78,
od_wait=150,
metric_period = 400,
l2_leaf_reg = 5,
thread_count = 20,
random_seed = 967
)
model.fit(tr_x, tr_y, eval_set=(te_x, te_y),use_best_model=True)
pre= model.predict_proba(te_x)[:,1].reshape((te_x.shape[0],1))
train[test_index]=pre
test_pre[i, :]= model.predict_proba(test_x)[:,1].reshape((test_x.shape[0],1))
print (roc_auc_score(te_y, pre))
cv_scores.append(roc_auc_score(te_y, pre))
以上是关于catboost原理以及Python代码的主要内容,如果未能解决你的问题,请参考以下文章