解释性与编译型 Python2和python3的区别
Posted 2275114213
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解释性与编译型 Python2和python3的区别相关的知识,希望对你有一定的参考价值。
一 基础:
1.解释型语言与编译型语言的区别
首先,我们编程都是用的高级语言(写汇编和机器语言的大牛除外),计算机不能直接理解高级语言,只能理解和运行机器语言,所以必须要把高级语言翻译成机器语言,计算机才能运行高级语言所编写的程序,
说到翻译其实有两种:解释和编译,两种翻译的时间不同而已.
用编译性语言写的程序执行之前,需要一个专门的编译过程,通过编译系统(不仅仅只是通过编译器.编译器只是编译系统的一部分)把高级语言翻译成机器语言,把源高级语言程序编译成机器语言文件,比如windows的exe文件.以后直接运行就可以了,不需要在编译le,因为翻译只做了一次,运行时不需要翻译,所以编程语言的程序执行效率高,但也不能一概而论,
部分解释性语言的解释器通过在运行时动态优化代码,甚至超过编译型语言.
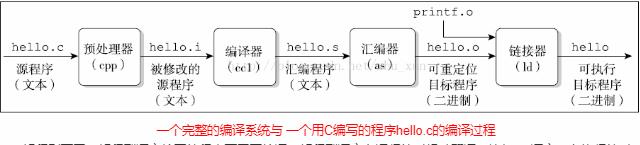
(1)解释型语言
解释则不同,解释型语言编写的程序不需要编译。解释型语言在运行的时候才翻译,比如VB语言,在执行的时候,专门有一个解释器能够将VB语言翻译成机器语言,每个语句都是执行的时候才翻译。这样解释型语言每执行一次就要翻译一次,效率比较低 .
2.二者的利弊
编译型与解释型,两者各有利弊。前者由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)等都是编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如JavaScript、VBScript、Perl、Python、Ruby、MATLAB 等等。 但随着硬件的升级和设计思想的变革,编译型和解释型语言越来越笼统,主要体现在一些新兴的高级语言上,而解释型语言的自身特点也使得编译器厂商愿意花费更多成本来优化解释器,解释型语言性能超过编译型语言也是必然的。
3.java和c#
JAVA语言是一种编译-解释型语言,同时具备编译特性和解释的(其实,确切的说java就是解释性语言,其所谓编译过程是将.java文件编译成平台无关的字节码.class文件,并不是向C一样编译成可执行文件的机器语言,作为编译型语言,JAVA程序要被统一编译成字节码文件——文件后缀是class。此种文件在java中又称为类文件。java类文件不能再计算机上直接执行,它需要被java虚拟机翻译成本地的机器码后才能执行,而java虚拟机的翻译过程则是解释性的。java字节码文件首先被加载到计算机内存中,然后读出一条指令,翻译一条指令,执行一条指令,该过程被称为java语言的解释执行,是由java虚拟机完成的。而在现实中,java开发工具JDK提供了两个很重要的命令来完成上面的编译和解释(翻译)过程。两个命令分别是java.exe和javac.exe,前者加载java类文件,并逐步对字节码文件进行编译,而另一个命令则对应了java语言的解释(javac.exe)过程。在次序上,java语言是要先进行编译的过程,接着解释执行。
C#程序在第一次运行的时候,会依赖其.NET Frameworker平台,编译成IL中间码),然后由JIT compiler翻译成本地的机器码执行。从第二次在运行相同的程序,则不需要再执行以上编译和翻译过程,而是直接运行第一次翻译成的机器码。所以对于C#来说,通常第一次运行时间会很长,但从第二次开始,程序的执行时间会快很多。 那么,C#为什么要进行两次“编译”呢?其实,微软想通过动态编译(由JIT compiler工具实现)来实现其程序运行的最优化。如果代码在运行前进行动态编译运行,那么JIT compiler可以很智能的根据你本地机器的硬件条件来进行优化,比如使用更好的register,机器指令等等,而不是像原来那样,build一份程序针对所有硬件的机器跑,没有充分利用各个机器的条件。
二python的优缺点
优点:(1)开发效率非常高,(2)可移植性(3)可扩展性:如果希望一段代码运行的更快或不希望公开,那么可以用c++编写,然后在python中使用他们,(4)可嵌入型:可以把python嵌入到c++里
缺点:(1)速度慢:确实比c语言慢得多,比java也要慢一些(2)代码不能加密(3)线程不能利用多cpu问题(GIL锁全局解释锁)
三.python2和python3的区别
1.字符串
python3有两种表示字符序列的类型:bytes和str。前者的实例包含原始的8位值;后者的实例包含Unicode字符。
python2中也有两种表示字符序列的类型,分别叫做str和unicode。与python3不同的是,str的实例包含原始的8位值,而unicode的实例,则包含Unicode字符。
py2:
unicode v = u"root" 本质上用unicode存储(万国码)
(str/bytes) v = "root" 本质用字节存储
py3:
str v = "root" 本质上用unicode存储(万国码)unicode是一个“字符集”,而不是编码方式。
2.编码
计算机中只有0和1,一切都是有二进制表示,包括文本字符。当我们编辑文本"hello world"并保存,计算机首先把文本编码为二进制表示,然后再存储。当我们试图读取刚才保存的文本,首先也是读取二进制数据,然后通过解码,得到文本"hello world"
编码:
py2:
- ascii
python2中默认ascii码,所以不支持中文.如果改变编码方式,需要在文件开头编写:
文件头可以修改:#-*- encoding:utf-8 -*-
py3:
python3对内容进行编码默认的是- utf-8
文件头可以修改:#-*- encoding:utf-8 -*-
内存中使用的是unicode码
字符编码非常容易出问题,我们要牢记几句话:
1.用什么编码保存的,就要用什么编码打开
2.程序的执行,是先将文件读入内存中
3.unicode是父编码,只能encode解码成其他编码格式
utf-8,GBK这些是子8编码,只能decode编码成Unicode
三、Python解释器执行
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器作为文本编辑器,去打开t.py文件,从硬盘上将t.py的文件内容读入到内存中
第三阶段:python解释器解释执行刚刚加载到内存中t.py的代码
其中第二阶段,t.py文件在保存时有一个字符编码,在Python解释器打开文件时也要指定一样的编码方式(Python2默认的编码方式是ASCII,Python3默认是utf-8),如果文件保存的编码格式和Python解释器默认的编码方式不一样,就要在文件的开头写上#coding: ,来告诉python解释器不要用自己默认的编码方式来读,而是要用头文件指定的方式来读文件,这样才不会出错。
第三阶段:读取已经加载到内存中的代码(默认是Unicode),然后执行,执行过程中如果碰到类似定义变量的操作,就会在内存中开辟一块新的内存空间。此时注意,新开辟的内存空间不一定也是Unicode,用户可以在定义变量的时候指定编码方式,定义时开辟的内存空间,也只是一块空间而已,可以存放任意编码格式的代码。以Python3为例
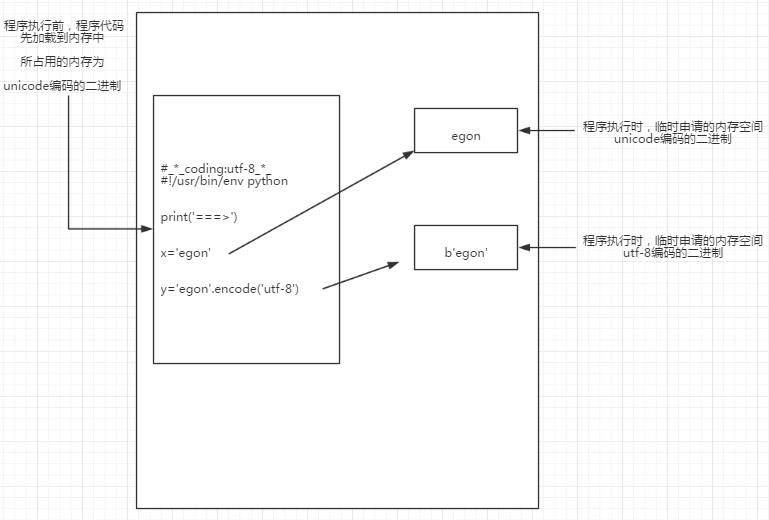
四、编码解码
保存文件是把内存中的文件保存到硬盘上
读文件是把硬盘中的文件读到内存
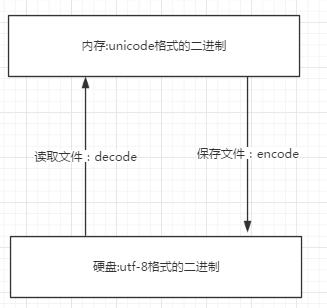
Unicode是父编码,utf-8,GBK这些是子编码,如果子码想转换成其他编码,必须要先转换成父编码,再由父编码转换成其他子编码
解码就是decode,是由子码转成父码Unicode的过程
编码就是encode,是由Unicode转换成其他编码的过程
之前说过,文件读入内存中,就成了Unicode编码(当然这是默认情况,也可以根据指令更改),从硬盘读文件的过程就是把硬盘中的utf-8解码成Unicode
文件保存时,就是由内存保存到硬盘的过程,硬盘中是utf-8的编码方式,需要由Unicode编码成utf-8
五、Python2和Python3的区别
1.Python2的默认编码方式是ASCII,打开utf-8保存的文件时会报错,应该在头文件上加#coding : utf-8
Python2中的str被识别为Bytes,所以Python2中的str是被编码后的结果,其实会默认做一件事,就是在str前面加一个u,先转换成Unicode,在encode成bytes
Python2中有两种字符串类型,str和Unicode,str可以通过在前面加个‘u\'来转换成Unicode
2.python 3 的默认编码方式是utf-8,可以直接打开用utf-8保存的文件
Python3中的str被识别成Unicode
Python3中也有两种字符串类型(bytes和str),但bytes就是bytes,str是unicode
六、打印到终端
首先要知道,Windows的终端的默认编码方式是GBK
终端也是应用程序,是运行在内存中的,所以我们用print()打印的过程,是从内存中到内存中。所以对于unicode,怎么打印都不会出错,但是Python2中除了加‘u\'的字符串外,其他的字符串是Bytes,此时终端中是GBK编码,而Python2中是指定的utf-8或者默认的ascii码时,在终端中打印就会出错。
编码小知识点:
python2解释器在加载.py文件中的代码时会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8.
ASCII:最早的编码,里面有英文大写字母,小写字母,数字,一些特殊字符.没有中文,8个01代码,8个bit(位),一个bytes(字节)


一个字节相当于一个房间
一个房间里有8个开关
开关上有两个选项01,只能选一个,
所以ASCII 2^8 =256可以表示256个字节
GBK:中文国标码,占两个字节,里面包含了ASCII码和中文常用编码.16个bit,2个byte(只能中国人使用)
Unicode:占四个字节(32bit)万国码里面包含了全世界所有国家的文字的编码.32个bit,4个byte,包含了ASCII
utf-8:可变长度的万国码.是unicodede一种实现,最小字符占8位
1.英文:8bit 1byte
2.欧洲文字:16bit 2byte
3.中文:24bit 3byte
终端是用GBK解码
3.类
python2:经典类/新式类
python3:新式类
新式类,如果自己或自己的前辈只要有人继承object,那么此类就是新式类。
经典类和新式类的查找成员的顺序不一样。
经典类,一条道走到黑(深度优先)。
新式类,C3算法实现(python2.3更新时c3算法)。经典类与新式类算法
4.
- 范围
py2:range/xrange
py3: range
- 输入
py2: v1 = raw_input(\'请输入用户名:\')
py3: v2 = input(\'请输入用户名:\')
- 打印
py2: print \'xx\'
py3: print(123)
以上是关于解释性与编译型 Python2和python3的区别的主要内容,如果未能解决你的问题,请参考以下文章