SQL多个字段如何去重
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL多个字段如何去重相关的知识,希望对你有一定的参考价值。
目前我有一张表,如下:
表名:test
字段:telephone, date, quhao
telephone date quhao
13888888888 201107052314 010
13899999999 201107042315 010
13888888888 201107040900 010
上表是号码有重复,日期不重复,我想要查询的结果是
telephone date quhao
13888888888 201107052314 010
13899999999 201107042315 010
请问该如何实现,谢谢大家了!
我要SQL语句,非常感谢!!!
SQL语句为:select distinct telephone (属性) from test(表名)
因为号码有重复,所以以号码telephone来查询,配合distinct,使得查询结果不重复。
使用关键字:distinct 即可去重。

扩展资料:
选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。
1、选择所有列
例如,下面语句显示testtable表中所有列的数据:
SELECT * FROM testtable
2、选择部分列并指定它们的显示次序
查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。
3、更改列标题
在选择列表中,可重新指定列标题。定义格式为:
列标题=列名 列名 列标题
如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题: SELECT 昵称=nickname,电子邮件=email FROM testtable。
4、删除重复行
SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。
5、限制返回的行数
使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是表示一百分数,指定返回的行数等于总行数的百分之几。TOP命令仅针对SQL Server系列数据库,并不支持Oracle数据库。
参考资料来源:百度百科-结构化查询语言
参考技术A对想要去除重复的列使用 group by 函数即可。
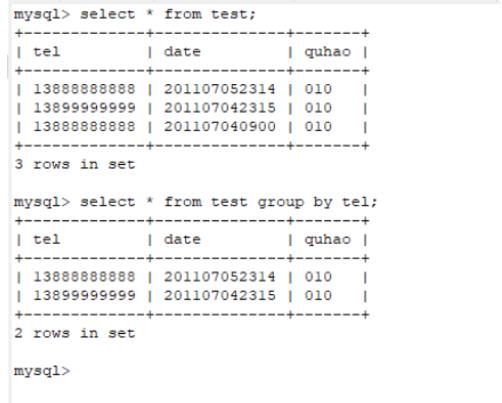
可以使用:select * from test group by tel。
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组,如合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句用于分组。
结果如图所示:
扩展资料:
1、介绍
合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句。
2、GROUP BY 语句
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
3、SQL GROUP BY 语法
SELECT column_name, aggregate_function(column_name)FROM table_name WHERE column_name operator valueGROUP BY column_name
SQL是一种查询功能很强的语言,只要是数据库存在的数据,总能通过适当的方法将它从数据库中查找出来。
SQL中的查询语句只有一个:SELECT,它可与其它语句配合完成所有的查询功能。SELECT语句的完整语法,可以有6个子句。
参考资料:百度百科——SQL GROUP BY
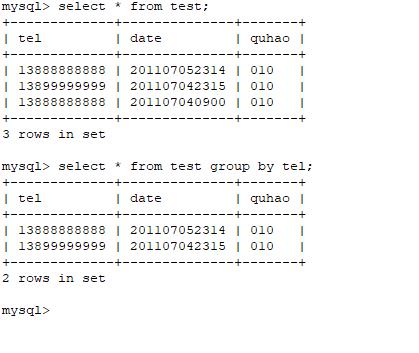
对想要去除重复的列使用 group by 函数即可。
可以使用:select * from test group by tel
结果如图所示:
扩展资料
GROUP BY我们可以先从字面上来理解,GROUP表示分组,BY后面写字段名,就表示根据哪个字段进行分组,如果有用Excel比较多的话,GROUP BY比较类似Excel里面的透视表。
GROUP BY必须得配合聚合函数来用,分组之后你可以计数(COUNT),求和(SUM),求平均数(AVG)等。
常用聚合函数:
count() 计数
sum() 求和
avg() 平均数
max() 最大值
min() 最小值
语法:
SELECT column_name, aggregate_function(column_name)FROM table_nameWHERE column_name operator valueGROUP BY column_name;
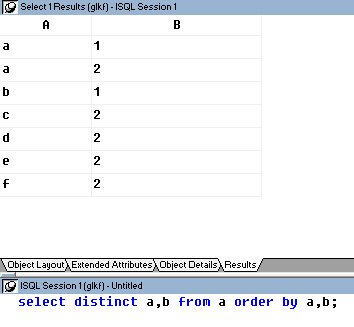
参考技术Csql 的 distinct ,作用是去除结果集中的重复值。可以是单字段也可以是多字段。
例:

去重结果
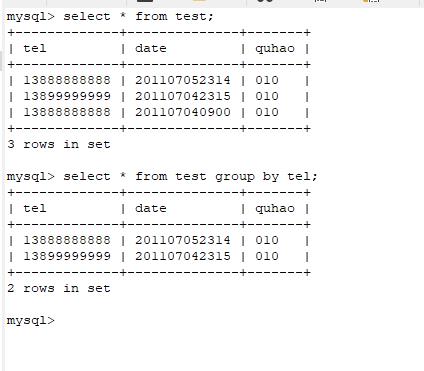
对想要去除重复的列使用 group by 函数即可。
可以使用:select * from test group by tel;
结果如图所示:
SQL GROUP BY 语句
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
SQL GROUP BY 语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
oracle中查询多个字段并根据部分字段进行分组去重
说到分组和去重大家率先想到的肯定是group by和distinct,
1.distinct对去重数据是要根据所有要查询的字段去重,不能对查询结果部分去重。
例如:
select name ,age ,sex from user where sex = "男";
要是只根据name和age去重,这里无法使用distinct关键字了。
2.group by ,可以在mysql中进行分组查询
select name ,age ,sex from user where sex = "男" group by name,age;
但是在Oracle数据库中该sql语句是无法正常执行的,会报如下错误
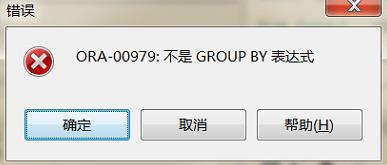
意思是在Oracle中,group by后的字段需要与select中查询的字段需要一一对应(函数除外);
3.使用over()分析函数
首先看原始sql
SELECT t3.* FROM ( SELECT t1.cateid, t1.product_id, t1.user_type, t2.expire_time FROM ( SELECT cfg.cateid, cfg.product_id, cfg.user_type FROM xshe_product_cfg cfg WHERE cfg.product_id IN (1080005002, 1100000001, 1100000002) ) t1 LEFT JOIN ( SELECT * FROM xshe_stock WHERE status = \'04\' AND expire_time >= sysdate ) t2 ON t1.cateid = t2.cateid ) t3
得到的数据结果集
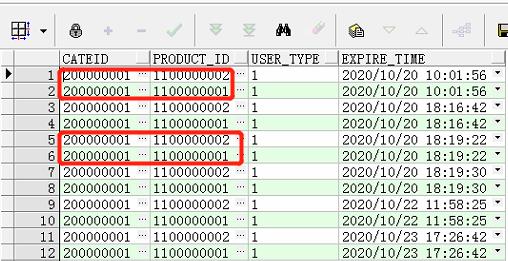
我们想根据cateid和product_id查询出有效期离得最近的一条记录,这里把重复数据都查询出来了
这里我们使用row_number() over()函数进行去重
SELECT t3.* FROM ( SELECT t1.cateid, t1.product_id, t1.user_type, t2.expire_time, ROW_NUMBER() OVER (PARTITION BY t1.cateid, t1.product_id ORDER BY t2.expire_time ASC) AS ROW_NUM FROM ( SELECT cfg.cateid, cfg.product_id, cfg.user_type FROM xshe_product_cfg cfg WHERE cfg.product_id IN (1080005002, 1100000001, 1100000002) ) t1 LEFT JOIN ( SELECT * FROM xshe_stock WHERE status = \'04\' AND expire_time >= sysdate ) t2 ON t1.cateid = t2.cateid ) t3 WHERE t3.ROW_NUM = 1
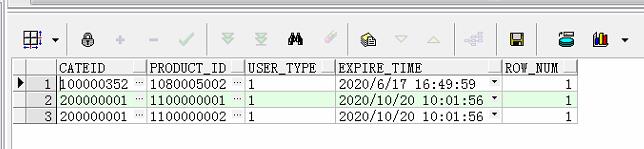
这里我们就对数据进行了完整的去重操作。
以上是关于SQL多个字段如何去重的主要内容,如果未能解决你的问题,请参考以下文章