组合数据类型,英文词频统计 python
Posted 玉滨的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了组合数据类型,英文词频统计 python相关的知识,希望对你有一定的参考价值。
练习:
总结列表,元组,字典,集合的联系与区别。列表,元组,字典,集合的遍历。
区别:
一、列表:列表给大家的印象是索引,有了索引就是有序,想要存储有序的项目,用列表是再好不过的选择了。在python中的列表很好区分,遇到中括号(即[ ]),都是列表,定义列表也是如此。列表中的数据可以进行增删查改等操作;
增加有两种表达方式(append()、expend()),关于append的用法如下(注:mylist定义的列表名称):不难看出,用append方法增加元素,不用给元素加中括号,而用extend方法加元素(一个元素可以不用中括号),(多个元素)必须要用一个中括号。
【mylist.append(5) >>>[1, 2, [3, 4], 5]
mylist.append([5]) >>>[1, 2, [3, 4], [5]]
mylist.extend([5]) >>> mylist.expand(1, 2, [3, 4], 5) 】
删除元素:del mylist[0] 既删除了mylist的第一个元素。

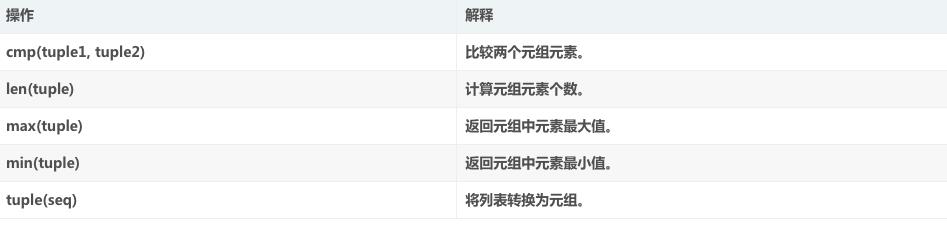
二、元组:元组给我的感觉,是列表的儿子,儿子终究是儿子,元组不可以进行删改,但可以查询、删除、增加。如以下代码所示(定义元组名字 yubin=("sun","yu","bin")):
删除元素:del yubin[0] ; 删除元素,查找元素是要用索引值,这点和列表list类似
索引元素:yubin.index["sun"] 索引元素,不是通过索引值来索引的,而是通过名字来索引的。
增加元素:yubin.append("az") 增加元素,这也和列表倒也没有太大的差别。

三、字典:字典是我用的最多的,说到字典,最离不开的就是“键值对”,键既是key,也是一个属性的名字,值就是这个属性的具体表现,可以是整型、字符型...字典没有排序,其输出的顺序也是按照先前定义时候的顺序输出。定义字典:sunyubin={"name":"sunyubin","age":22,"gender":"boy"}
删除元素:del.sunyubin[name]

四、集合:说到集合,首先想到就是set,其次是每个元素之间,用逗号(,)相隔。而且还不能有重复元素。
写入代码:
# 两种方法创建
set1 = set(\'kydaa\')
set2 = {\'abc\', \'jaja\', \'abc\', \'kyda\'}
print(set1)
print(set2)
输出代码:结构自动去重
{\'a\', \'y\', \'d\', \'k\'}
{\'jaja\', \'abc\', \'kyda\'}
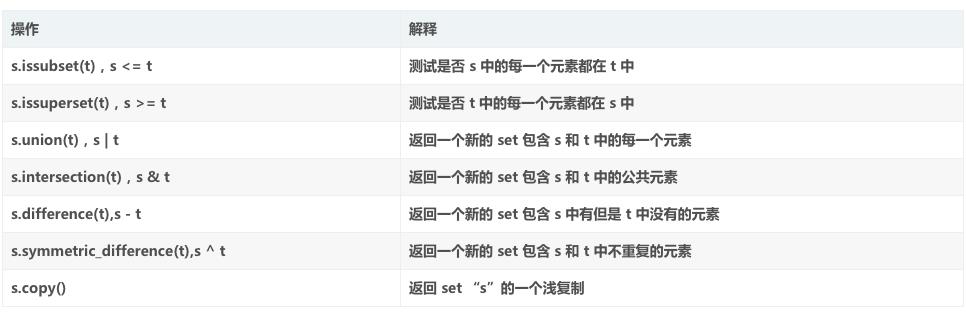
集合的方法:
英文词频统计:下载一首英文的歌词或文章str,分隔出一个一个的单词 list,统计每个单词出现的次数 dict。
有错误,在修改中
def getTxt():
txt = open("music").read()
txt = txt.lower()
for ch in \'!"@#$%^&*()+,-./:;<=>?@[\\\\]_`~{|}\':
txt.replace(ch," ")
return txt
hamletTxt = getTxt()
txtArr = hamletTxt.split()
counts = {}
for word in txtArr:
counts[word] = counts.get(word,0)+1
countList = list(counts.items())
countList.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = countList[i]
print(\'{0:<10}{1:>5}\'.format(word,count))
方法二:
with open(\'music\',\'r\') as f:
niubi = f.read()
niubi = niubi.lower()
print(\'全部转换为小写的结果:\' + niubi + \'\\n\')
for p in \'\'\',.?!’\':"“”-%$\'\'\':
niubi = niubi.replace(p, \' \')
print(\'分隔符替换为空格的结果:\' + niubi + \'\\n\')
split = niubi.split()
word = {}
for i in split:
count = niubi.count(i)
word[i] = count
words = \'\'\'
a an the in on to at and of is was are were i he she you your they us their our it or for be too do no
that s so as but it\'s don\'t
\'\'\'
prep = words.split()
for i in prep:
if i in word.keys():
del (word[i])
word = sorted(word.items(), key=lambda item: item[1], reverse=True)
for i in range(10):
print(word[i])
以上是关于组合数据类型,英文词频统计 python的主要内容,如果未能解决你的问题,请参考以下文章