基于华为云图引擎GES,使用Cypher子查询进行图探索
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于华为云图引擎GES,使用Cypher子查询进行图探索相关的知识,希望对你有一定的参考价值。
摘要:本文以华为云图引擎 GES 为例,来介绍如何使用图查询语言 Cypher 表达一些需要做数据局部遍历的场景。
本文分享自华为云社区《使用 Cypher 子查询进行图探索 -- 以华为云图引擎 GES 为例》,作者:蜉蝣与海。
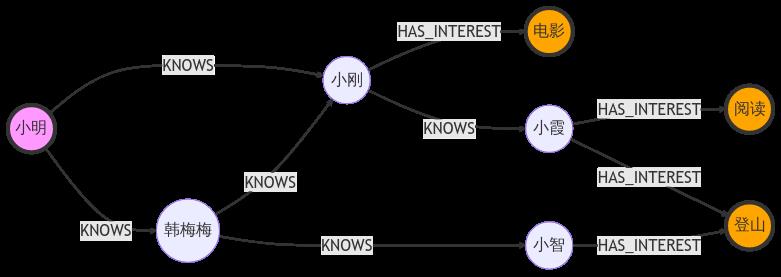
在图数据库 / 图计算领域,很多查询可以使用图查询语言 Cypher、Gremlin 或者指令式 API 进行表达,如多跳过滤、全局检索以及对过滤后的结果进行聚集排序等操作。然而有些查询不是那么容易表达,常常需要对图中的一组数据去做局部遍历,例如在社交网络(人 - 人,人 - 兴趣,人 - 工作地的关联网络)场景中,常常涉及以下场景:
- 朋友推荐:看看小明的朋友的朋友中,哪些不是小明的朋友,进而推荐给小明。
- 潜在二度人脉分析:选取一组点,每个点代表一个人,在他们朋友的朋友中,统计他们各自有多少不认识的男性朋友和女性朋友。
- 兴趣推荐 A:兴趣爱好也是社交网络中的点,看看小明的朋友有哪些兴趣爱好(人 - INTEREST - 兴趣),从每个朋友的兴趣爱好中选取至多 N 个兴趣爱好推荐给小明。
- 兴趣推荐 B:看小小明有哪些朋友还没有录入兴趣爱好,允许小明把自己的兴趣爱好推荐给他们。
这些查询往往只关注图中的某个局部,对局部进行多跳查询,且局部上往往有类似下列限制:
- 数量限制:例如兴趣推荐 A 场景中,限制了每个朋友的兴趣数目,而不是总数目。
- 条件限制:例如朋友推荐场景中,“哪些不是小明的朋友” 需要先查询小明和朋友的朋友间有没有边,并将结果作为查询条件输入。
在查询语言 Cypher 中,常常使用子查询来解决这类问题。本文会以华为云图引擎 GES 为例(图引擎版本 >=2.3.6),来介绍如何使用 Cypher 表达上述场景。
注:本文同步发布至华为云 AI Gallery,文中所有代码皆可以在AI Gallery上运行:【AI Gallery】使用Cypher子查询进行图探索 – 以华为云图引擎GES为例。
阅读前准备
基础知识
阅读前需要了解如下基础知识
- Cypher查询语言的基本结构:
- 关于Cypher样例语句,可以参考:图引擎服务帮助文档-业务面API-Cypher-基本操作和兼容性
- 关于Cypher的文法说明,可以参考openCypher 9官方页面。
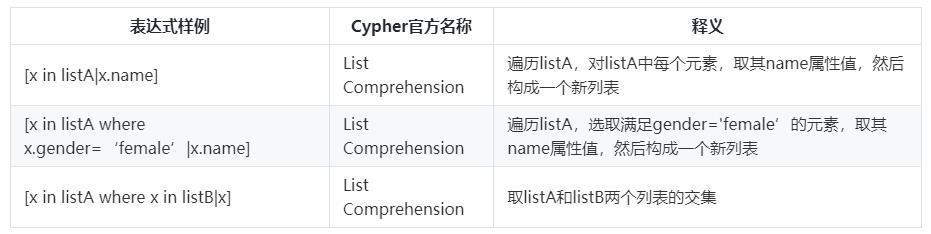
- Cypher的列表表达式:
- 华为云图引擎GES支持的列表表达式,可以参考图引擎服务帮助文档-业务面API-Cypher-支持的表达式,函数及过程
- Neo4j 3.5 Cypher Manual - Lists - List Comprehension
- 对本文中使用到的列表表达式,提前做下述解释:
下方三个小节会指导如何配置一个 GES 实例并使用 notebook 连接 GES 服务进而做查询演示。如果你只想了解如何编写查询语句,对输入的 Cypher 查询获取返回结果没有需求,可以直接跳过下方三个小节。
本文使用的数据集
本教程使用 LDBC-SF0.1 社交数据集中截选的人物关系数据集,数据集可以从此处下载。下载后需要在 GES 中创建图并导入数据集,详细指导流程可参见华为图引擎文档 - 快速入门和华为云图引擎服务 GES 实战 —— 创图。
如何调用 GES 的 Cypher API
GES 官网帮助文档上有 GES Cypher 的 API,为了方便用户调用,API 设计为基于 http/https 请求,响应体的设计也兼容的 neo4j 的 json 格式。这里放置一下链接执行 Cypher 查询。调用 API 时需要将 Token 输入请求头中进行鉴权,有关 Token 的获取问题请参考业务面 API 认证鉴权。
本文会使用 ges4jupyter 工具脚本进行相关查询的演示,该脚本中封装了刚刚提到的鉴权 & Cypher 查询 API,并对结果进行了一些处理,提供了相关可视化的能力。
本文使用的代码包
ges4jupyter 是 jupyter 连接 GES 服务的工具文件。文件中封装了使用 GES 查询的预置条件,包括配置相关参数和对所调用 API 接口的封装,如果你对这些不感兴趣,可直接运行而不需要了解细节,这对理解后续具体查询没有影响。本文的所有语句请求都会访问一个 GES 实例并得到实际的响应。
import moxing as mox mox.file.copy(\'obs://obs-aigallery-zc/GES/ges4jupyter/beta/ges4jupyter.py\', \'ges4jupyter.py\') mox.file.copy(\'obs://obs-aigallery-zc/GES/ges4jupyter/beta/ges4jupyter.html\', \'ges4jupyter.html\')
GESConfig 的参数都是与调用 GES 服务有关的参数,依次为 “公网访问地址”、“项目 ID”、“图名”、“终端节点”、“IAM 用户名”、“IAM 用户密码”、“IAM 用户所属账户名”、“所属项目”,其获取方式可参考调用 GES 服务业务面 API 相关参数的获取。这里通过 read_csv_config 方法从配置文件中读取这些信息。如果没有配置文件,可以根据自己的需要补充下列字段。对于开启了 https 安全模式的图实例,参数 port 的值为 443。
from ges4jupyter import GESConfig, GES4Jupyter, read_csv_config eip = \'\' project_id = \'\' graph_name = \'\' iam_url = \'\' user_name = \'\' password = \'\' domain_name = \'\' project_name = \'\' port = 80 eip, project_id, graph_name, iam_url, user_name, password, domain_name, project_name, port = read_csv_config(\'cn_north_4_graph.csv\') config = GESConfig(eip, project_id, graph_name, iam_url = iam_url, user_name = user_name, password = password, domain_name = domain_name, project_name = project_name, port = port) ges_util = GES4Jupyter(config, True);
首先在 GES 中创建索引,这有利于后续查询加速。
import time def wait_job_finish(util, job_id, max_loop): job_result = util.get_job(job_id) if \'errorCode\' not in job_result: for i in range(max_loop): if job_result[\'status\'] == \'success\': break else: time.sleep(1) job_result = util.get_job(job_id) print(job_result) job_id = ges_util.build_vertex_index() wait_job_finish(ges_util, job_id, 100) job_id = ges_util.build_edge_index() wait_job_finish(ges_util, job_id, 100)
可以使用下列语句查看 schema 信息:
import time body = ges_util.generate_schema_structure() job_id = body["jobId"] print(\'开始构造schema结构:\') wait_job_finish(ges_util, job_id, 100) print(\'schema结构构造完成\') cypher_result = ges_util.cypher_query("call db.schema()",formats=[\'row\',\'graph\']); ges_util.format_cypher_result(cypher_result, candidate_title = [\'description\', \'name\'])
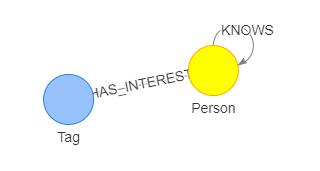
如图是本文使用的数据集的 schema,主要包括下列类型的点边:

使用子查询
一般来说,使用 Cypher 查询朋友的朋友是相对容易的,下列语句演示了如何查询顶点 p367 朋友的朋友。
match (n)-[:KNOWS]->(a)-[:KNOWS]->(b) where id(n)=\'p367\' return distinct b
然而,使用一般的 Cypher 语义,从朋友的朋友中移除所有的朋友,表达朋友推荐场景中的 “朋友的朋友而非我的朋友” 却很困难。文章如何使用GES进行社交关系考据?—GES查询能力介绍中,描述了一种常规的查询语句的写法:
match (n)-[:KNOWS]->(a) where id(n)=\'p367\' with n, collect(a) as neighbor match (n)-[:KNOWS]->(a)-[:KNOWS]->(b) where not (b in neighbor) return b
由于 cypher 的结果是使用行(Row)组织数据,所有的计算以 “行” 作为单元进行,如果要进行过滤,只能进行行内过滤。所以上述语句第一步,先通过 collect (a), 将 “朋友” 这个集合组织到了一行里,而后才能将 collect (a) 作为过滤条件,进行二次查询。
将子查询作为查询条件
在 GES 2.3.6 版本,实现了子查询能力,支持 Neo4j 中的 SemiApply 算子,该算子支持类似于下列语句的运行,使得查询更为简洁:
match (n) where id(n)=\'p367\' match (n)-[:KNOWS*2..2]->(b) where not (n)-[:KNOWS]->(b) return id(b) limit 10 cypher_result = ges_util.cypher_query(""" match (n) where id(n)=\'p367\' match (n)-[:KNOWS*2..2]->(b) where not (n)-[:KNOWS]->(b) return id(b) limit 10""",formats=[\'row\',\'graph\']); ges_util.format_cypher_result(cypher_result)

- SemiApply: 用于支撑 “where (n)-[:KNOWS]->(b)” 这样的条件,表示对应的查询模式存在。
- AntiSemiApply:用于支撑 “where not (n)-[:KNOWS]->(b)” 这样的条件,表示对应的查询模式不存在。
这两个算子对每个左子树生成的结果,都去检查右子树是否会 / 不会产生满足条件的结果,并将右子树的结果作为过滤条件,辅助左子树的结果过滤。
通过这两个算子,即可实现简单的条件子查询。
cypher_result = ges_util.cypher_query("""explain match (n) where id(n)=\'p367\' match (n)-[:KNOWS*2..2]->(b) where not (n)-[:KNOWS]->(b) return id(b) limit 10""",formats=[\'row\',\'graph\']); ges_util.format_cypher_result(cypher_result)
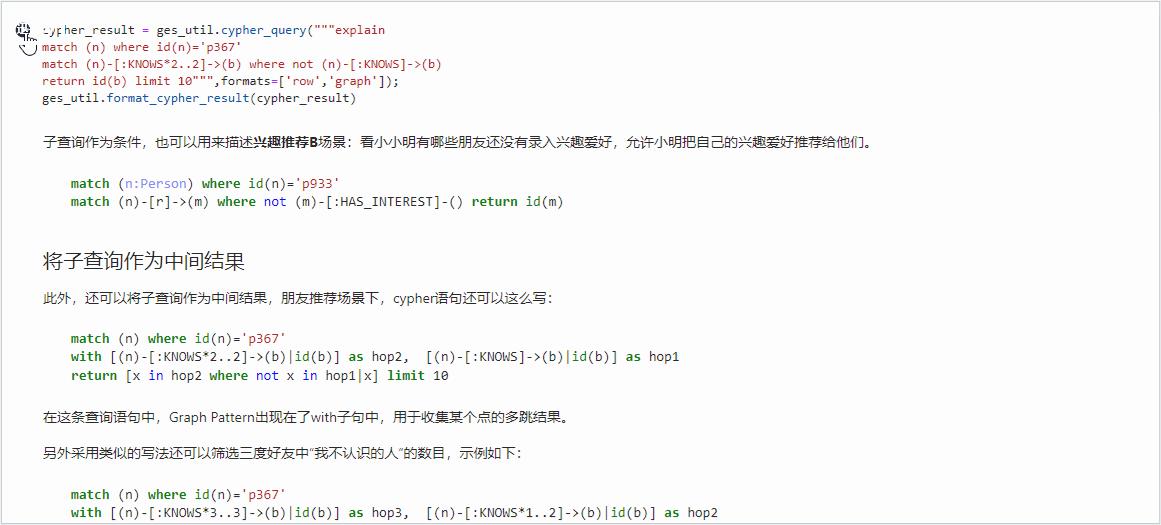
子查询作为条件,也可以用来描述兴趣推荐 B 场景:看小小明有哪些朋友还没有录入兴趣爱好,允许小明把自己的兴趣爱好推荐给他们。
match (n:Person) where id(n)=\'p933\' match (n)-[r]->(m) where not (m)-[:HAS_INTEREST]-() return id(m)
将子查询作为中间结果
此外,还可以将子查询作为中间结果,朋友推荐场景下,cypher 语句还可以这么写:
match (n) where id(n)=\'p367\' with [(n)-[:KNOWS*2..2]->(b)|id(b)] as hop2, [(n)-[:KNOWS]->(b)|id(b)] as hop1 return [x in hop2 where not x in hop1|x] limit 10
在这条查询语句中,Graph Pattern 出现在了 with 子句中,用于收集某个点的多跳结果。
另外采用类似的写法还可以筛选三度好友中 “我不认识的人” 的数目,示例如下:
match (n) where id(n)=\'p367\' with [(n)-[:KNOWS*3..3]->(b)|id(b)] as hop3, [(n)-[:KNOWS*1..2]->(b)|id(b)] as hop2 return size([x in hop3 where not x in hop2|x]) cypher_result = ges_util.cypher_query(""" match (n) where id(n)=\'p367\' with [(n)-[:KNOWS*3..3]->(b)|id(b)] as hop3, [(n)-[:KNOWS*1..2]->(b)|id(b)] as hop2 return size([x in hop3 where not x in hop2|x])""",formats=[\'row\',\'graph\']); ges_util.format_cypher_result(cypher_result, boxHeight=200)

同时这种子查询也可以包含子查询过滤条件,进行各类统计操作,如上述提到的潜在二度人脉分析:
match (n:Person) where id(n) in [\'p367\',\'p13194139534836\',\'p932\',\'p4398046512206\',\'p6597069767359\'] with n, [(n)-[:KNOWS*2..2]->(m) where not (n)-->(m)|m] as recSet return id(n) as key, size([x in recSet where x.gender=\'male\']) as maleNumber, size([x in recSet where x.gender=\'female\']) as femaleNumber cypher_result = ges_util.cypher_query(""" match (n:Person) where id(n) in [\'p367\',\'p13194139534836\',\'p932\',\'p4398046512206\',\'p6597069767359\'] with n, [(n)-[:KNOWS*2..2]->(m) where not (n)-->(m)|m] as recSet return id(n), size([x in recSet where x.gender=\'male\']),size([x in recSet where x.gender=\'female\']) """,formats=[\'row\',\'graph\']); ges_util.format_cypher_result(cypher_result, boxHeight=200)
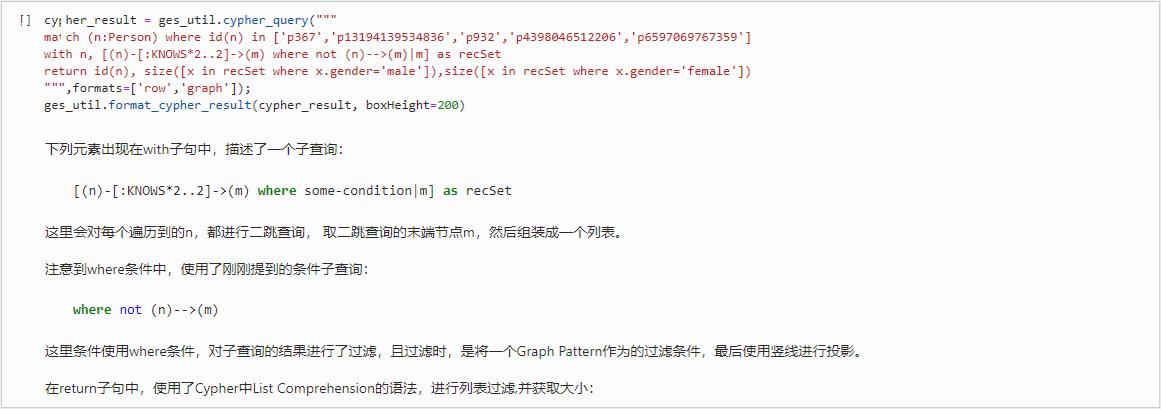
下列元素出现在 with 子句中,描述了一个子查询:
[(n)-[:KNOWS*2..2]->(m) where some-condition|m] as recSet
这里会对每个遍历到的 n,都进行二跳查询, 取二跳查询的末端节点 m,然后组装成一个列表。
注意到 where 条件中,使用了刚刚提到的条件子查询:
where not (n)-->(m)
这里条件使用 where 条件,对子查询的结果进行了过滤,且过滤时,是将一个 Graph Pattern 作为的过滤条件,最后使用竖线进行投影。
在 return 子句中,使用了 Cypher 中 List Comprehension 的语法,进行列表过滤,并获取大小:
return id(n) as key, size([x in recSet where x.gender=\'male\']) as maleNumber, size([x in recSet where x.gender=\'female\']) as femaleNumber
支撑子查询作为过滤条件的,是 RollUpApply 算子,可以通过 explain 看到其在查询计划中发挥价值:
cypher_result = ges_util.cypher_query("""explain match (n:Person) where id(n) in [\'p367\',\'p13194139534836\',\'p932\',\'p4398046512206\',\'p6597069767359\'] return n, [(n)-[:KNOWS*2..2]->(m) where not (n)-->(m)|m] as recSet""",formats=[\'row\',\'graph\']); ges_util.format_cypher_result(cypher_result, boxHeight=200)
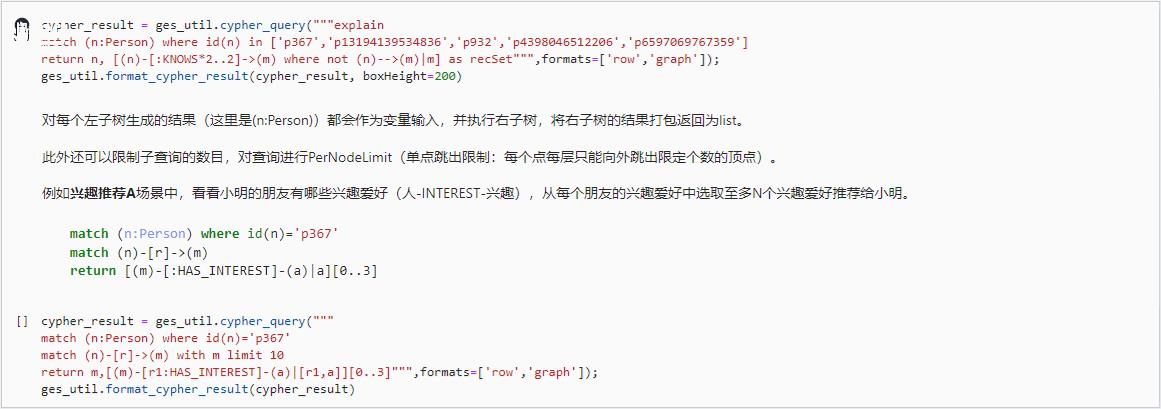
对每个左子树生成的结果(这里是 (n:Person))都会作为变量输入,并执行右子树,将右子树的结果打包返回为 list。
此外还可以限制子查询的数目,对查询进行 PerNodeLimit(单点跳出限制:每个点每层只能向外跳出限定个数的顶点)。
例如兴趣推荐 A 场景中,看看小明的朋友有哪些兴趣爱好(人 - INTEREST - 兴趣),从每个朋友的兴趣爱好中选取至多 N 个兴趣爱好推荐给小明。
match (n:Person) where id(n)=\'p367\' match (n)-[r]->(m) return [(m)-[:HAS_INTEREST]-(a)|a][0..3]
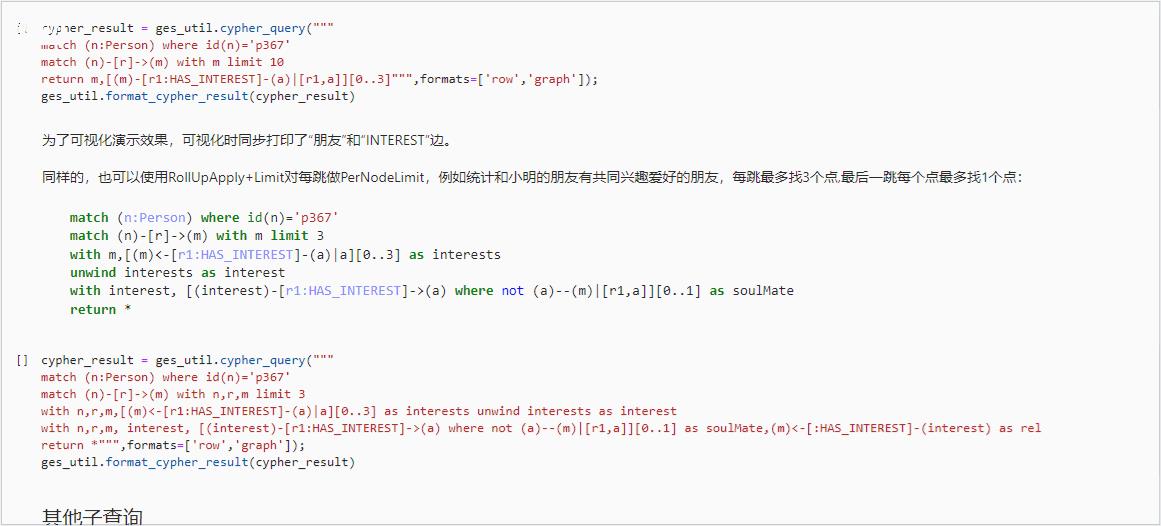
为了可视化演示效果,可视化时同步打印了 “朋友” 和 “INTEREST” 边。
同样的,也可以使用 RollUpApply+Limit 对每跳做 PerNodeLimit,例如统计和小明的朋友有共同兴趣爱好的朋友,每跳最多找 3 个点,最后一跳每个点最多找 1 个点:
match (n:Person) where id(n)=\'p367\' match (n)-[r]->(m) with m limit 3 with m,[(m)<-[r1:HAS_INTEREST]-(a)|a][0..3] as interests unwind interests as interest with interest, [(interest)-[r1:HAS_INTEREST]->(a) where not (a)--(m)|[r1,a]][0..1] as soulMate return *

其他子查询
使用 with 也可以实现其他子查询任务,例如上一跳的查询结果经过 limit 限制后输入下一跳,成为查询条件:
match (n:Person) where id(n) in [\'p367\',\'p13194139534836\',\'p932\',\'p4398046512206\',\'p6597069767359\'] with n limit 10 match (m:PersonlastName:n.lastName) return n.lastName, m.firstName
使用 explain 也可以看到其查询计划:
cypher_result = ges_util.cypher_query("""explain match (n:Person) where id(n) in [\'p367\',\'p13194139534836\',\'p932\',\'p4398046512206\',\'p6597069767359\'] with n limit 10 match (m:PersonlastName:n.lastName) return n.lastName, m.firstName""",formats=[\'row\',\'graph\']); ges_util.format_cypher_result(cypher_result)

由于不同的 n,其 n.lastName 的值是不固定的,所以需要针对每个 n,去做 match (m:Person lastName:n.lastName) 这样的查询,因此需要使用 Apply 子查询算子支撑这样的语句。
总结
借助子查询局部遍历是图查询中的常用操作,将子查询作为条件过滤或者中间结果,可以满足某些业务场景下的对查询的局部有限制的诉求,如文中提到的社交网络分析,再如股权穿透网络中穿透层数分析、装备制造和配置管理(IT 设备管理)领域依赖识别和变更影响分析等。
此外,由于 Cypher 以行的形式组织数据,某些情况下使用子查询可以节省中间结果产生,加速 Cypher 查询的执行。
当然,使用更高效的 API(如 GES 产品中有多跳过滤 API) 或者使用非行存的查询执行引擎也是可选的解决方案。
教你使用Jupyter可视化查询语句的语法树
摘要:本文以华为图引擎使用的cypher查询语言为例,将查询语句的解析结果(语法树)在jupyterLab上可视化。
本文分享自华为云社区《使用Jupyter可视化查询语句的语法树--以图查询语言Cypher为例》,作者: 蜉蝣与海。
“语法解析”和“词法解析”是计算机理解查询语句的重要一环。而词法和语法的解析依赖于一定的文法规则,对这些文法规则生成的语法树进行可视化,可以降低查询语言的理解成本。本文以华为图引擎使用的cypher查询语言为例,将查询语句的解析结果(语法树)在jupyterLab上可视化。案例中使用的工具不仅可以可视化cypher语言的语法树结构,对其他antlr生成的抽象语法树同样适用。
查询语言是用于从数据库或信息系统中查询数据的计算机语言,使用查询语言可以很方便地在数据库中完成各类数据管理以及查询操作。在关系数据库中常用的查询语言是SQL,在图数据库管理系统中,常用的查询语言有Cypher、Gremlin、SPARQL等。
当数据管理系统收到一条查询语句时,会对这条查询语句进行一些理解和解释,最终会翻译为一系列可以执行的步骤来处理数据。其中“语法解析”和“词法解析”是计算机理解查询语句的第一步。而词法和语法的解析依赖于一定的文法规则,对这些文法规则生成的语法树进行可视化,可以学习查询语言的各个语法成分,加深对查询语言的了解。
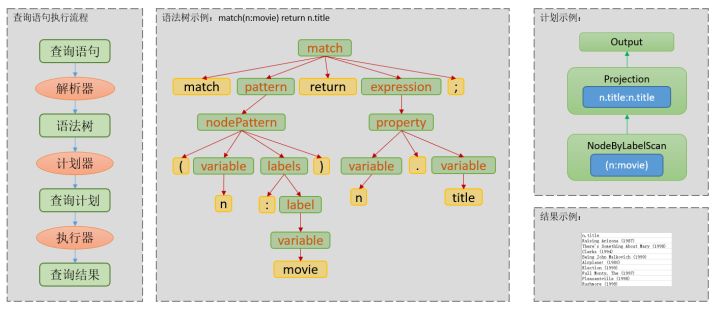
图 1 一条查询语句的执行流程
通常词法&语法解析器可以由一些工具进行生成,例如常见的flex/bison(c/c++), yacc(c/c++), antlr(java)、javacc(java)、Parboiled(scala)等。这些工具往往以规则文件作为输入,输出一个语法解析器。本文的最终目标是:通过一个已生成的语法解析器解析某条查询语句,对解析到的语法成分进行可视化。
在查询语言的选择上,考虑到华为图引擎GES对接了Cypher、Gremlin两大主流图查询语言,其中Cypher查询语言有公开的文法规则,所以以Cypher为例; 在生成工具方面,由于只有少数工具可以生成python的解析代码,这里使用antlr4作为语法解析器生成工具。
环境准备
注:本文对应的notebook链接为:AI Gallery_Notebook详情_开发者_华为云,相关代码可以直接在notebook上运行。
首先从OpenCypher官网下载cypher的文法规则,从Antlr的官网下载antlr工具包。
wget https://s3.amazonaws.com/artifacts.opencypher.org/M18/Cypher.g4
wget https://github.com/antlr/website-antlr4/blob/gh-pages/download/antlr-4.8-complete.jar
pip install antlr4-python3-runtime==4.8这里简单介绍一下语法规则,一条语法规则定义了语句中的各个部分如何被解释,下面展示了Match子句的解释规则:一个Match子句,必须包含一个单词MATCH和一个Pattern(MATCH SP? oC_Pattern),MATCH和Pattern间可能有空格(SP),MATCH和Pattern的前部可能有一个OPTIONAL单词(( OPTIONAL SP )?),后部可能有一个Where语法成分(( SP? oC_Where )?)。关于antlr的细节,可以查看华为云相关博文介绍:Antlr4简明使用教程, 推荐一款优秀的语法解析工具—Antlr4
oC_Match
: ( OPTIONAL SP )? MATCH SP? oC_Pattern ( SP? oC_Where )? ;下面代码可以生成cypher查询语言python版本的语法解析器。
java -cp antlr-4.8-complete.jar org.antlr.v4.Tool -visitor -package cypher -Dlanguage=Python3 Cypher.g4如果你正在使用notebook,且notebook环境中没有java,也可以通过下列代码下载已经生成好的语法解析器。
import moxing as mox
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/cypher-generated-parser.zip', 'cypher-generated-parser.zip')
!unzip cypher-generated-parser.zip语法树生成 & 可视化
对文法规则的可视化,网上已有诸多案例,例如OpenCypher官网提供了Cypher文法的可视化结果,可以进入查看。另外网上也有一部分网站,可以输入文法规则,返回可视化结果。例如在网站https://www.bottlecaps.de/convert/上, 可以输入包括antlr、bison、javacc在内的诸多文法规则,而后生成文法规则的可视化图表。例如将Cypher.g4文法文件输入这个网站,可以获得的文法规则截选如下。
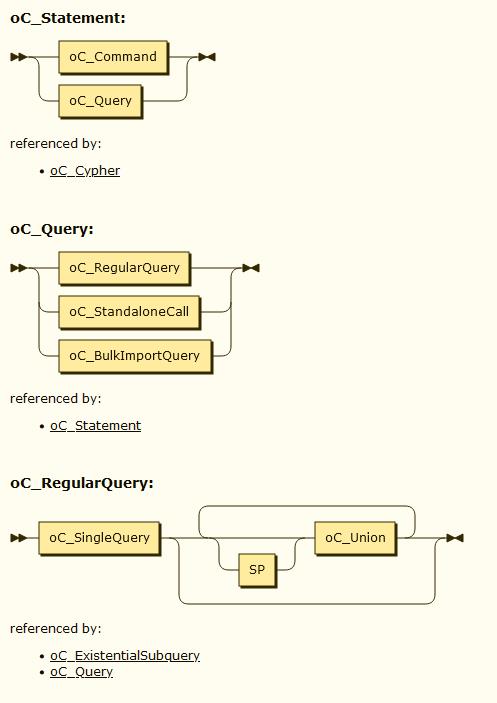
这里给出了oC_Statement、oC_Query、oC_RegularQuery三条规则的解释,例如对oC_Statement而言,其可以由一个oC_Command或者一个oC_Query构成;而一个oC_RegularQuery,则可以由一个oC_SingleQuery,以及0到多个oC_Union构成。这些文法规则的可视化给出了文法的定义,却未提供可视化某条语句解析结果的能力。可视化语句的解析结果目前只能依赖antlr的插件,但是antlr未提供jupyter侧的可视化工具。下面本文试图在jupyter侧可视化一条查询语句的语法解析路径。
首先我们写一个解析查询语句的函数,用来生成语法解析器的解析结果。下列代码是一个经典的antlr解析语句的流程,通过构造词法解析器(lexer)、单词流(stream)、语法解析器(parser)来完成整个初始化过程,最终parser只需要调用文法中的规则名,即可使用规则来生成语法树结构。
from CypherLexer import CypherLexer
from CypherParser import CypherParser
from antlr4 import *
def get_ast(statement):
reader = InputStream(statement)
lexer = CypherLexer(reader)
stream = CommonTokenStream(lexer)
parser = CypherParser(stream)
return parser.oC_Statement()而后输入一条查询语句,并调用ast函数,代码会返回解析后的对象。
ast_tree = get_ast('match (n) return n limit 10')在获得语法树之后,可以从语法树中提取关键语法成分,而后进行可视化。相关代码已经封装为了工具包,可以直接下载使用。其中可视化工具使用的是vis.js。
import moxing as mox
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/viz_ast_parser.py', 'viz_ast_parser.py')
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/viz_ast_parser.html', 'viz_ast_parser.html')from viz_ast_parser import *
def beautify_name(name):
return name.replace('OC_', '').replace('Context', '').replace('Impl', '')
vizAstParser = VizAstParser(beautify_name)
vizAstParser.vis_ast(get_ast('match (n) return n limit 10'))
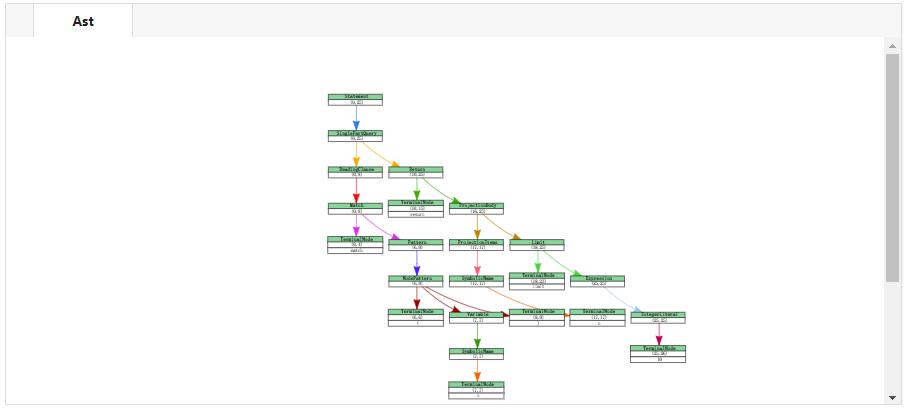
通过可视化可以看到:即使是一条简单的语句也有丰富的语法结构,这样的层次结构,计算机也更容易理解和解析。
备注:
1.工具中的相关代码不仅可以用来可视化cypher语言的语法成分, 其他可以用antlr生成python解析器的语言,该工具也可以提供JupyterLab上的可视化支持。
2. 本文对应的notebook链接为:AI Gallery_Notebook详情_开发者_华为云,相关代码可以直接在notebook上运行。
以上是关于基于华为云图引擎GES,使用Cypher子查询进行图探索的主要内容,如果未能解决你的问题,请参考以下文章