完结撒花MySQL(二十三)主从复制
Posted Tod4の代码零碎
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了完结撒花MySQL(二十三)主从复制相关的知识,希望对你有一定的参考价值。
MySQL(二十三)主从复制
1 主从复制概述
1.1 如何提高数据库并发能力
- 在实际工作中,常将
Redis和MySQL配合使用,如果有请求的时候,首先在缓存中查找,如果存在就直接取出,不存在再访问数据库,这样就提升了读取的效率,减少了对后端数据库的访问压力,Redis缓存是高并发架构非常重要的一环
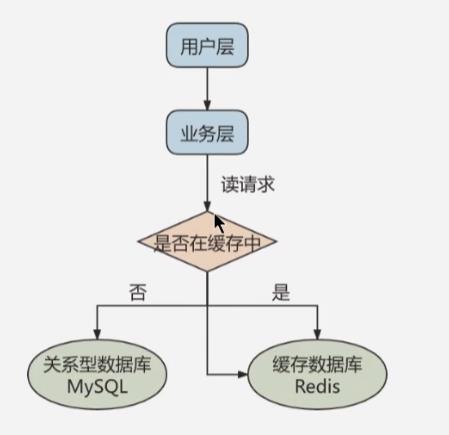
-
一般应用对于数据库而言都是
读多写少,也就是说对数据库读取数据的压力比较大,因此可以采用数据库集群的方法,做主从架构、进行读写分离,以提升数据库的并发处理能力。但并不是所有的应用都需要进行主从架构的设计,毕竟设置架构本身是需要成本的 -
如果目的是为了提高数据库的高并发访问效率,那么首先考虑到的应该是
优化SQL和索引,这种方式简单有效,其次是redis缓存,最后才是主从架构进行读写分离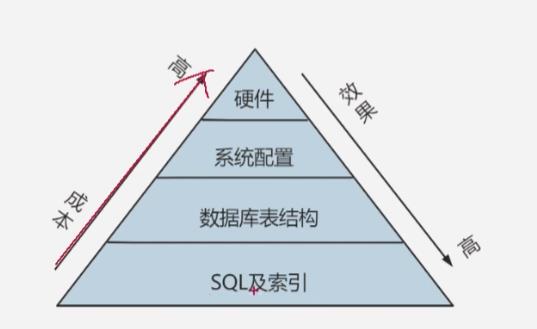
1.2 主从复制的作用
-
提高数据库的吞吐量
-
实现读写分离:通过主从复制的方式来同步数据,通过读写分离来提高数据库的并发处理能力
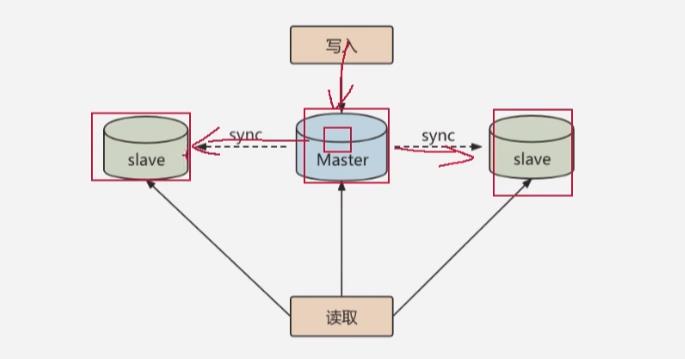
其中Master是主库,负责写入数据,也称作是写库;Slave是从库,负责读取数据,也称作是读库;在主库更新数据的时候,会自动将数据复制到读库中。读写分离除了能使数据库提高并发处理能力之外,还能对服务器进行
负载均衡,-
能够让不同的读请求按照分配策略分布到不同的从服务器上
-
减少了锁表的影响,主库出现写锁的时候,不会影响从库的读操作
如上原因使得读操作更加流畅
-
-
数据备份:通过主从复制将主库上的数据复制到从库上,相当于一种
热备份机制,也就是主库在正常运行的情况下进行的备份,不会影响到正在运行的服务 -
高可用性:数据备份其实是一种冗余的机制,通过这种冗余的方式可以换取数据库的高可用性,也就是服务器在出现故障或者宕机的情况下,可以切换到从服务器上,保证服务的正常运行
2 主从复制的原理
- 主从复制的原理就是Slave从机从Master主机读取
bin log到relay log进行数据同步 - 具体来说,就是
从库I/O线程会连接主库,向主库发送请求更新bin log,主库的二进制日志存储线程会将二进制日志发送给从库(并且在主库在读取事件(Event)的时候,会对bin log加锁,读取完成之后再释放掉);这时从库I/O线程就可以读取到主库线程发送的bin log更新部分,并且拷贝到本地的中继日志中;最后从库SQL线程会读取从库的中继日志,并且执行日志中的事件,将从库的数据与主库保持同步
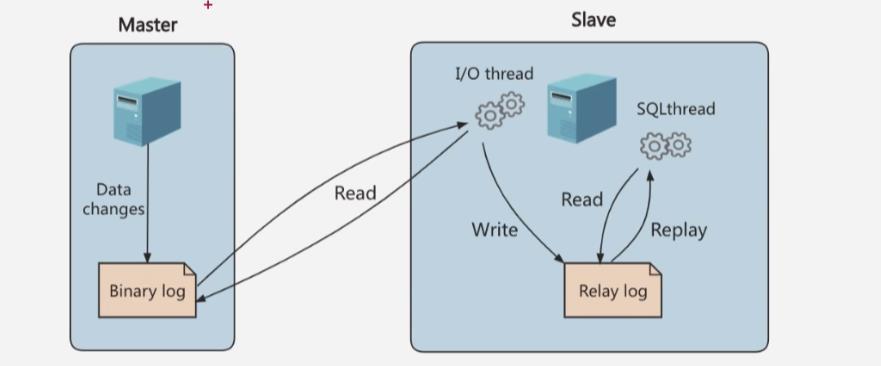
注意:
- 并不是所有版本的MySQL都默认开启了服务器的二进制日志,在进行主从复制的时候,首先应该检查服务器是否开启了二进制日志
- 除非特殊指定,默认情况下从服务器会执行主服务器上保存的所有的事件,可以通过配置让从服务器只执行特定的事件
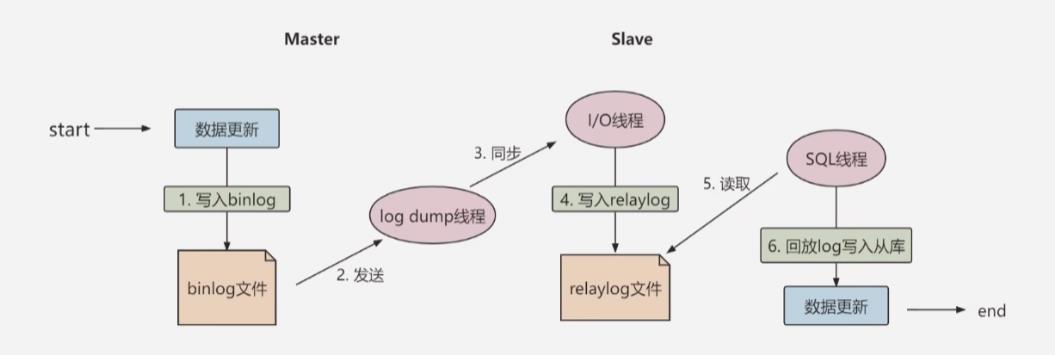
复制的三步骤:
- Master将写操作记录到bin log,这些记录叫做二进制日志事件
- Slave将Master的bin log记录拷贝到中继日志中
- Slave重做中继日志中的事件,将改变应用到自己的数据库。MySQL的复制是异步且可串行化的,并且重启后从接入点开始复制
2.1 复制的基本原则
- 每个slave只有一个master
- 每个slave只拥有一个惟一的server id
- 每个master可以拥有多个slave
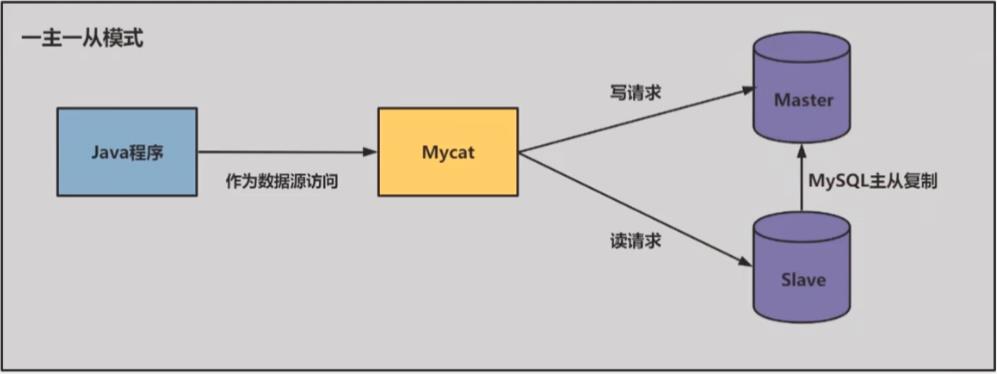
3 一主一从架构搭建
一台主机用于处理写请求,一台从机负责读请求,这部分听一下不实践了
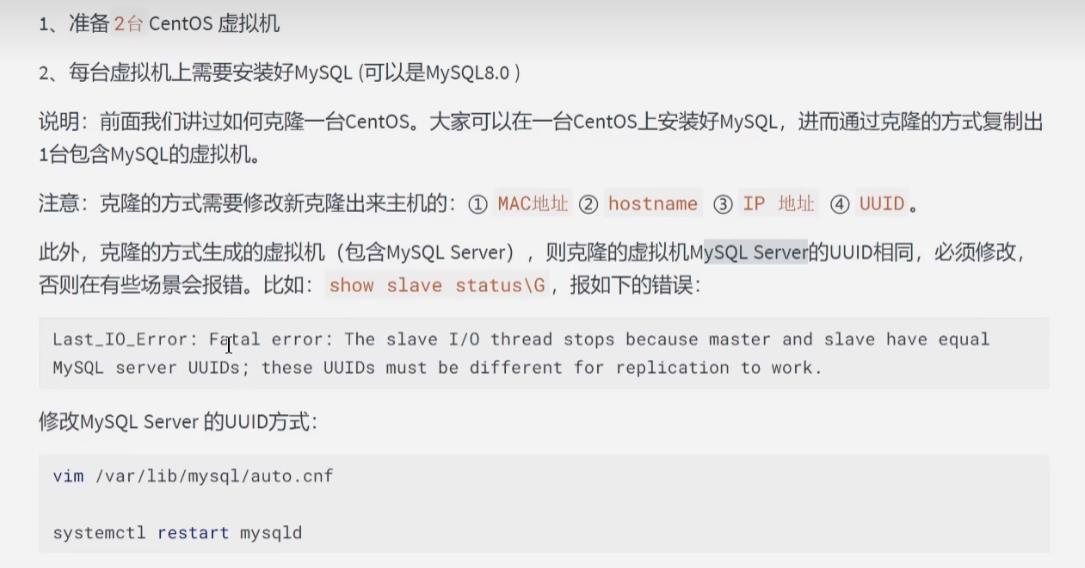
3.1 准备工作
3.2 主机:配置文件
#[必须] 主机唯一id
server-id=1
#[必须] 启用二进制日志,指明路径
log-bin=xxxx
#[可选] 0(默认)表示读写,1表示只读
read-only=0
#[可选] 设置日志文件保留时间,单位是s
binlog_expire_logs_seconds=6000
#[可选] 设置不要复制的数据库
binlog-ignore-db=test
#[可选] 设置需要复制的数据库,默认全部记录
binlog-do-db=xxx
#[可选] 设置binlog格式
binlog_format=STATEMENT
注意:
- 先搭建完主从复制,再创建数据库,如果主机先创建数据库,bin log没有创建的语句进而导致从机无法创建相同的数据库
- MySQL主从复制开始的时候,从机并不继承主机参数
3.3 主机:建立账户并授权
MySQL5.7之前的版本:
# 在主机MySQL执行授权主从复制的命令
GRANT REPLICATION SLAVE ON *.* TO \'slave1\'@\'slave ip\' IDENTIFIED BY \'master pwd\';
MySQL8需要如下方式建立账户并授权slave
CREATE USER \'slave1\'@\'%\' IDENTIFIED BY \'master pwd\';
GRANT REPLICATION SLAVE ON *.* TO \'slave1\'@\'%\';
# 这条语句必须执行
ALTER USER \'slave1\'@\'%\' INENTIFIED WITH mysql_native_password BY \'master pwd\';
flush prilvileges;
第三条不执行会报错:
也可以在
my.cnf中设置default_authentication_plugin=mysql_native_password

3.4 从机:配置文件
#[必须] 从服务器唯一id
server-id=2
#[可选] 启用中继日志
relay-log=xxx
主从机都需要关闭防火墙或者开启防火墙特定端口
3.5 从机:配置需要复制的主机
-
show master status查看主机状态:
-
从机上复制主机的命令:
CHANGE MASTER TO MASTER_HOST=\'master id + host(3306)\', MASTER_USER=\'xxxx\', MASTER_PASSWORD=\'xxxx\', MASTER_LOG_FILE=\'binlogxxxx\', MASTER_LOG_POS=\'xxx\'; # 上面`show master status`查看到的Position
3.6 从机:开启主从复制
START SLAVE;
3.7 从机:停止主从复制
STOP SLAVE;
如果停止主从复制,需要重新配置主从:
STOP SLAVE;
RESET MASTER; # 即删除master上的bin log日志,并将日志索引文件清空,重新开始所有新的日志文件
4 bin log的format设置问题
4.1 STATEMENT格式
STATEMENT格式即基于SQL语句的复制(statement-based replication,SBR),会使得每一条执行的修改数据的SQL语句都写入到binlog中,是默认的binlog格式。
binlog_format=STATEMENT
-
SBR的优点:
- 历史悠久,技术成熟
- 不需要记录每一行数据的变化,减少了bin log日志量
- 包含数据库更改信息(能记录执行过的每条SQL),可以据此来审核数据库的安全情况
- bin log可以进行实时的还原,而不仅仅用于主从复制
- 主从版本可以不一样,从服务器的版本可以比主服务器的版本要高(从机执行过的SQL都是主机执行过的因此从比主高就没问题)
-
SBR的缺点:
-
不是所有的update语句都能被复制,尤其是包含不确定操作的时候。比如使用下面函数的时候:LOAD_FILE()、UUID()、USER()、FOUND_ROWS()、SYSDATE()
-
INSERT ... SELECT会产生比RBR更多的行级锁
SELECT会将扫描过的记录全部添加排它锁(本身是insert操作)
-
复制需要进行全表扫描(Where语句没有使用到索引)的Update时,需要比RBR请求更多的
行级锁 -
对于有AUTO_INCREMENT的插入语句来说,会堵塞其他的插入语句
-
数据表必须和主服务器保持一致,否则可能会导致复制出错
-
4.2 ROW格式
ROW格式即基于行的复制(Row-based replication, RBR)
bin_format = row;
- RBR的优点:
- 任何情况都可以被复制,对复制来说是安全可靠的(不会出现特定情况下无法被复制的情况如存储过程、触发器的调用和触发等情况)
- 多数情况下,从服务器的表上有主键的话,复制就快很多
- 复制以下几种语句的时候行锁更少:INSERT ... SELECT、对于有AUTO_INCREMENT的插入语句、没有附带条件或者没有修改很多记录的Update或Delete操作
- 执行insert、update、delete时锁更少
- 从服务器能够采用多线程来进行赋值
- 缺点:
- bin log日志大了很多
- 回滚的时候bin log中包含大量的数据
- 主服务器上执行update的时候,所有的数据变化都会写到bin log中,而SBR只会写一次sql,这会导致频繁发生bin log的并发写问题
- 无法从bin log中查看执行了哪些语句
4.3 MIXED格式
即混合模式复制(Mixed Based Replication, MBR)
- Mixed格式实际就是Statement和Row格式的结合
- 一般语句使用Statement格式进行保存bin log,statement无法完成主从复制操作的语句如一些函数,则使用Row格式保存
bin_format = mixed;
5 同步数据一致性问题
主从同步的要求:
- 读库和写库的数据一致(最终一致)
- 写数据必须写到写库
- 读数据必须读到读库(不一定,可能会出现主从、主备的切换)
5.1 理解主从延迟问题
5.2 主从延迟原因
5.3 如何减少主从延迟
5.4 如何解决一致性问题
如果读和写操作的数据在同一个数据库中,那么对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况,但是这样从库的作用就只剩下备份了,起不到读写分离的作用以分担主库压力。
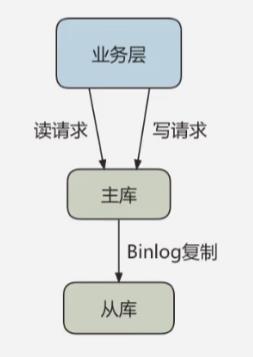
读写分离情况下,解决主从同步中数据不一致的问题,就是解决主从之间数据复制方式的问题,按照数据一致性由弱到强有以下三种解决方案:
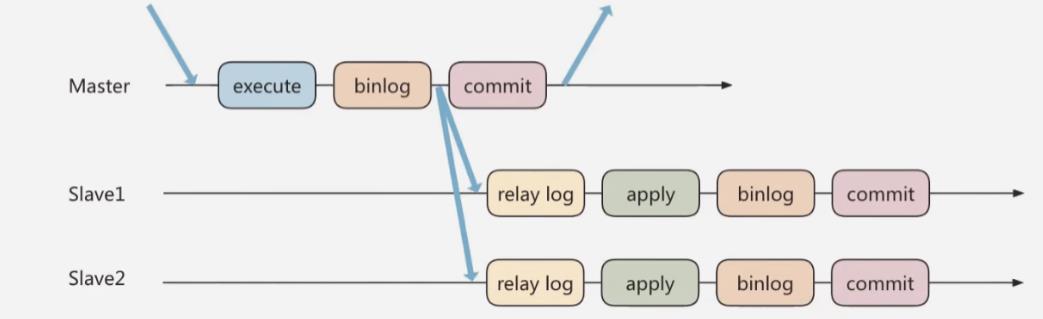
方法一:异步复制
- 异步复制就是主机提交事务之后不需要等待从库返回任何的结果,而是直接将结果返回给客户端
- 这样做的好处就是不会影响主机的写的效率,当时可能会存在主库宕机,而bin log还没有同步到从库的情况,造成主从数据不一致
- 如果这时候从从机中选择一个作为主机,那么这个主机就可能缺少原来主机已经提交的事务,所以这种模式下的数据一致性是最差的
方法二:半同步复制
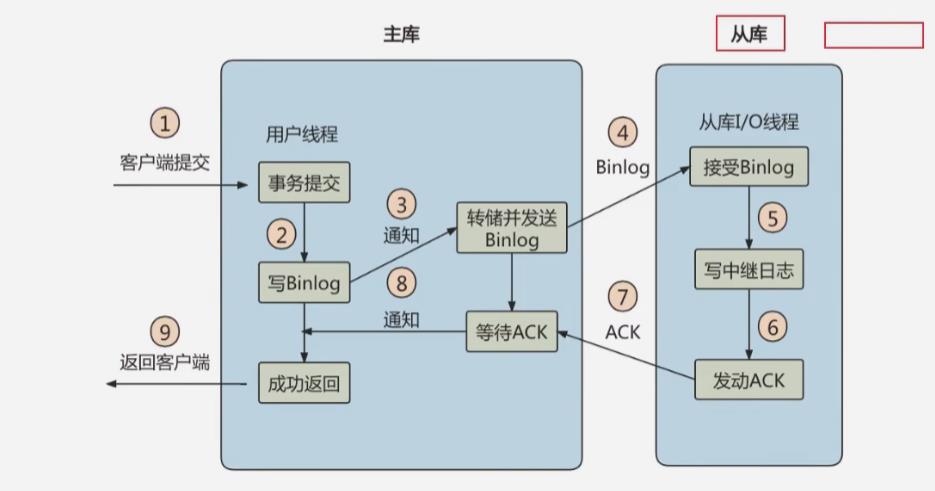
MySQL5.5之后开始采用半同步复制的方式:
- 主机在提交事务之后不会立即向客户端返回结果,而是等待至少有一个从库收到bin log并写入relay log返回成功通知后,才将结果返回给客户端
- 好处是增加了数据的一致性,但是相对于异步来说至少增加了一个网络连接的延迟,降低了主库写的效率
- 5.7版本后新增参数
rpl_semi_sync_master_wait_for_slave_count可以设置应答从库的数量
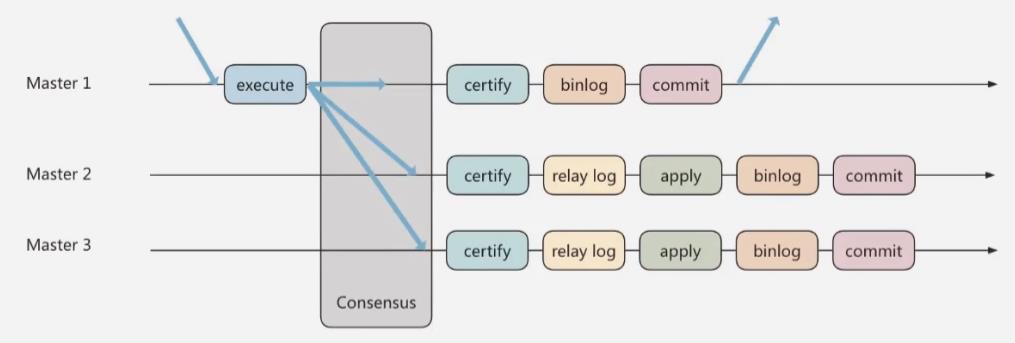
方法三:组复制(MySQL Group Replication)
对于数据一致性要求比较高的场景,MGR很好地解决了以上两种模式的不足。
- 首先将多个节点共同组成一个复制组,在执行读写(RW)事务的时候,需要经过
一致性协议层(Consensus)的半数以上节点同意才可以进行提交,并且只读事务不需要组内同意直接提交即可 - 在一个复制组内有多个节点组成,他们各自维护自己的数据副本,并且在
一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性
MySQL学习(二十四)主从同步-半同步
概述
MySQL 默认是异步复制,半复制是为了数据一致性,防止异步同步数据过程中,事务丢失。同步复制的话可以保证数据的一致性,数据不丢失可以回滚,但是响应慢,master 必须等待 slave 返回的ack响应才算完整地完成事务,而异步复制则有可能出现数据不一致的问题,半复制处于异步复制和同步复制的中间。
半复制只需要等待(默认)一台 slave 完成了写入就算完成事务请求了。
半复制过程
Semisynchronous replication can be used as an alternative to asynchronous replication:
- A slave indicates whether it is semisynchronous-capable when it connects to the master.
- If semisynchronous replication is enabled on the master side and there is at least one semisynchronous slave, a thread that performs a transaction commit on the master blocks and waits until at least one semisynchronous slave acknowledges that it has received all events for the transaction, or until a timeout occurs.
- The slave acknowledges receipt of a transaction‘s events only after the events have been written to its relay log and flushed to disk.
- If a timeout occurs without any slave having acknowledged the transaction, the master reverts to asynchronous replication. When at least one semisynchronous slave catches up, the master returns to semisynchronous replication.
- Semisynchronous replication must be enabled on both the master and slave sides. If semisynchronous replication is disabled on the master, or enabled on the master but on no slaves, the master uses asynchronous replication.
为了理解,以下列出和同步复制和异步复制的对比。
To understand what the “semi” in “semisynchronous replication” means, compare it with asynchronous and fully synchronous replication:
With asynchronous replication, the master writes events to its binary log and slaves request them when they are ready. There is no guarantee that any event will ever reach any slave.
With fully synchronous replication, when a master commits a transaction, all slaves also will have committed the transaction before the master returns to the session that performed the transaction. The drawback of this is that there might be a lot of delay to complete a transaction.
Semisynchronous replication falls between asynchronous and fully synchronous replication. The master waits only until at least one slave has received and logged the events. It does not wait for all slaves to acknowledge receipt, and it requires only receipt, not that the events have been fully executed and committed on the slave side.
参考资料 :
以上是关于完结撒花MySQL(二十三)主从复制的主要内容,如果未能解决你的问题,请参考以下文章