intel等处理器 介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了intel等处理器 介绍相关的知识,希望对你有一定的参考价值。
参考技术A 分类: 无分类问题描述:
求intel等处理器的介绍,比如Intel的首颗64位处理器是什么之类的问题答案,最好还有其他Intel、Microsoft……等等新产品等的介绍,谢谢!
解析:
Intel CPU产品介绍- -
Intel CPU产品介绍
从大的命名规则来看,Intel的CPU产品主要分为Pentium奔腾系列和Celeron赛扬系列处理器。而从架构上区分,目前市面上的Intel CPU产品既有最常见的Socket 478架构,也有老一代的Socket 370架构,还有极少量的Socket 423架构。
(Intel的Pentium 4和Celeron处理器)
一、早期的Socket 370架构:
这是Intel的早期产品,当前二手市场上能见到的有Coppermine铜矿核心的PentiumⅢ和CeleronⅡ,以及Tualatin图拉丁核心的CeleronⅢ。虽然看起来稍显过时,但其实这里面也有着性价比较高的产品。例如Tualatin图拉丁核心的CeleronⅢ,因为拥有32KB的一级缓存和256KB的二级缓存,所以性能与同频的PentiumⅢ都有得一拼。并且由于采用了0.13微米制程,所以Tualatin图拉丁赛扬的超频潜力也不错。不过由于Intel的市场策略,Socket 370架构现已被彻底抛弃,基于该架构的主板和CPU产品也因此失去了任何升级潜力。所以这些CPU只适合老用户升级使用,并不推荐新装机的用户购买。
二、过渡型Socket 423架构:
这主要见于Intel第一批推出的Willamette核心Pentium 4产品。但它只不过是昙花一现,上市不久便立即被Socket 478架构所取代。其相应的处理器和主板产品也迅速被品牌机等市场消化,现在市场上已经几乎见不到它们了。所以如果您在逛市场时见到这样的CPU,估计都是不知道从哪翻出的仓底货或是二手产品,笔者奉劝大家尽量少碰为妙。
三、主流的Socket 478架构:
这是当前Intel的主流产品,产品线中既包括有高端的Pentium 4处理器,也包括了低端的Celeron处理器。可就是同属Socket 478架构的Intel处理器,也有许多不同类型。这就是我们下面将要讲述的内容。
“ABCDE”含义释疑
我们知道,Intel的不少Pentium 4处理器在频率后面还带有一个字母后缀,不同的字母也代表了不同的含义。
一、“A”的含义:
Pentium 4处理器有Willamette、Northwood和Prescott三种不同核心。其中Willamette核心属于最早期的产品,采用0.18微米工艺制造。因为它发热较大、频率提升困难,而且二级缓存只有256KB,所以性能颇不理想。于是Intel很快用Northwood核心取代了它的位置。Northwood核心Pentium 4采用0.13微米制程,主频有了很大的飞跃,二级缓存容量也翻了一番达到了512KB。为了与频率相同但只有256KB二级缓存的Pentium 4产品区别,Intel在其型号后面加了一个大写字母“A”,例如“P4 1.8A”,代表产品拥有512KB二级缓存。这些产品均只有400MHz的前端总线(Front Side Bus,简称FSB)。
二、“B”的含义:
同样频率的产品,在更高的外频下可具备更高的前端总线,因此性能也更高。为此Intel在提升CPU频率的同时,也在不断提高产品的前端总线。于是从可以支持533MHz FSB的845E等主板上市开始,市场上又出现了533MHz FSB的Pentium 4处理器。为了与主频相同但是只有400MHz FSB的Pentium 4产品区别开来,Intel又给它们加上了字母“B”作为后缀,例如“P4 2.4B”。
三、“C”的含义:
继533MHz FSB的产品之后,Intel再接再厉,继续推出了800MHz FSB的Pentium 4处理器,同样为了与早期产品相区别,Intel在其命名上用上了字母“C”,例如“P4 2.4C”。
四、“E”的含义:
继生命周期超长的Northwood核心处理器之后,Intel开始转向了90纳米制造工艺。Prescott核心Pentium 4也就应运而生。它采用了31级流水线设计,配备16KB的一级数据缓存和多达1MB的二级缓存。不知道出于什么考虑,针对800MHz FSB的Prescott核心P4处理器,Intel这次并没有按部就班地将字母“D”派给它,而是用了一个更靠后的字母“E”,例如“P4 2.8E”。这也许是“Prescott”里本身包含字母“E”的缘故。
需要特别关注的是,Prescott核心Pentium 4也有533MHz FSB的产品,该产品取消了对Hyper-Threading超线程技术的支持,并以大写字母“A”做为后缀,例如“P4 2.4A”。许多人一见这命名,就想当然地以为它是400MHz FSB的Northwood核心P4,切记这是错误的!
五、“D”的含义:
“A”、“B”、“C”、“E”都有了,中间惟独缺了个“D”,难免显得不够完美。也许正是基于这种考虑,最近网上传出消息称Intel将Prescott核心Celeron处理器正式命名为“Celeron-D”。
(Celeron赛扬系列处理器的LOGO)
Celeron-D同样采用90纳米工艺制造,但它只拥有533MHz FSB和256KB二级缓存,且不支持超线程技术。最早推出的产品有2.53GHz/2.66GHz/2.8GHz三款,后期还会推出3.2GHz的产品。
未来的数字命名
我们以前已经有文章对Intel处理器的最新命名方式进行了报道。从今年下半年开始,以频率为基准的传统命名方式将被“3XX”、“5XX”和“7XX”的数字命名所取代。这无论是对Intel还是广大消费者来说都是一个挑战。就连笔者这整天跟硬件打交道的人,看着这些数字都会觉得头晕。下面我们就来看一看最新的Intel处理器命名规则速查表。需要注意的是,表格中的“LV”代表Low Voltage低电压,而“ULV”则是Ultra Low Voltage超低电压的缩写。
Celeron系列处理器命名(3XX系列):
CPU
制造工艺
前端总线
L2缓存
产品命名
Celeron M 1.5GHz
90纳米
400MHz
1MB
370
Celeron M 1.4GHz
90纳米
400MHz
1MB
360
Celeron M ULV 1.0GHz
90纳米
400MHz
512KB
358
Celeron M 1.3GHz
90纳米
400MHz
1MB
350
Celeron D 3.2GHz
90纳米
533MHz
256KB
350
Celeron D 3.06GHz
90纳米
533MHz
256KB
345
Celeron M 1.5GHz
130纳米
400MHz
512KB
340
Celeron D 2.93GHz
90纳米
533MHz
256KB
340
Celeron M ULV 900MHz
90纳米
400MHz
512KB
338
Celeron D 2.8GHz
90纳米
533MHz
256KB
335
Celeron M 1.4GHz
130纳米
400MHz
512KB
330
Celeron D 2.66GHz
90纳米
533MHz
256KB
330
Celeron D 2.53GHz
90纳米
533MHz
256KB
325
Celeron M 1.3GHz
130纳米
400MHz
256KB
320
Pentium 4系列处理器命名(5XX系列):
CPU
制造工艺
前端总线
L2缓存
产品命名
Pentium 4 XE 3.4GHz
130纳米
800MHz
512KB
?
Pentium 4 XE 3.2GHz
130纳米
800MHz
512KB
?
Pentium 4 4.0GHz
90纳米
800MHz
1MB
580
Pentium 4 3.8GHz
90纳米
800MHz
1MB
570
Pentium 4 3.6GHz
90纳米
800MHz
1MB
560
Pentium 4 M 3.6GHz
90纳米
533MHz
1MB
558
Pentium 4 M 3.46GHz
90纳米
533MHz
1MB
552
Pentium 4 3.4GHz
90纳米
800MHz
1MB
550
Pentium 4 3.2GHz
90纳米
800MHz
1MB
540
Pentium 4 M 3.2GHz
90纳米
533MHz
1MB
538
Pentium 4 M 3.06GHz
90纳米
533MHz
1MB
532
Pentium 4 3.0GHz
90纳米
800MHz
1MB
530
Pentium 4 2.8GHz
90纳米
800MHz
1MB
520
Pentium 4 M 2.8GHz
90纳米
533MHz
1MB
518
Pentium M系列处理器命名(7XX系列):
CPU
制造工艺
前端总线
L2缓存
产品命名
Pentium M 2.13GHz
90纳米
533MHz
2MB
770
Pentium M 2.0GHz
90纳米
533MHz
2MB
760
Pentium M ULV 1.2GHz
90纳米
400MHz
2MB
758
Pentium M 2.0GHz
90纳米
400MHz
2MB
755
Pentium M LV 1.5GHz
90纳米
400MHz
2MB
753
Pentium M 1.86GHz
90纳米
533MHz
2MB
750
Pentium M 1.8GHz
90纳米
400MHz
2MB
745
Pentium M 1.73GHz
90纳米
533MHz
2MB
740
Pentium M ULV 1.1GHz
90纳米
400MHz
2MB
738
Pentium M 1.7GHz
90纳米
400MHz
2MB
735
Pentium M LV 1.4GHz
90纳米
400MHz
2MB
733
Pentium M 1.6GHz
90纳米
533MHz
2MB
730
Pentium M 1.6GHz
90纳米
400MHz
2MB
725
Pentium M ULV 1.1GHz
130纳米
400MHz
1MB
718
Pentium M 1.5GHz
90纳米
400MHz
2MB
715
Pentium M 1.3GHz
90纳米
400MHz
2MB
713
Intel® QAT 助力Nginx压缩处理
什么是Intel® QAT?
QuickAssist Technology是Intel®公司提供的一种高性能数据安全和压缩的加速方案。该方案利用QAT芯片分担对称/非对称加密计算,Deflate无损压缩等大计算量的任务,来降低CPU使用率并提高整体平台性能。该方案可以以主板芯片,独立的PCI-E加速卡或者SoC三种方式部署。
QAT支持硬件加速Deflate无损压缩算法,在处理海量数据时,QAT在不增加CPU开销的前提下,通过压缩来减少需要传输和存盘的数据量,从而减少了网络带宽和磁盘读写的开销,最终提高了整体的系统性能。 例如,在Web Server上使用QAT硬件加速压缩处理,可将CPU从繁重的压缩计算中解放出来,以处理更多的连接请求。
什么是Nginx Web Server
Nginx(发音同engine x)是一款使用异步框架的高性能Web服务器,与Apache、lighttpd等其他Web Server相较,Nginx具有占有内存少,稳定性高等优势。根据Netcraft 2018年一月的Web Server市场调查报告,Nginx的装机率达25.39%,位列Web Server市场第三,并在持续增长中[1]。
Nginx中的Gzip模块实现了对HTTP压缩的支持,该模块通过调用Zlib库实现对网页内容进行Deflate压缩。由于使用软件实现无损压缩,需要消耗大量CPU运算时间进行压缩运算。
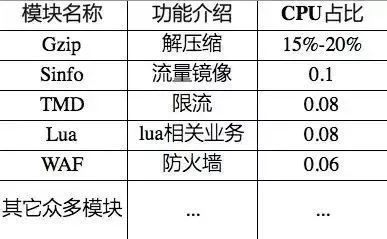
然而,在大并发流量的网站接入层的Nginx需要处理相当多的业务,包括HTTPS连接建立、安防攻击、流量镜像、链路追踪等等。使得CPU进行HTTP压缩处理成为Web Server最主要的CPU开销,进而限制了网站支持最大并发连接数。根据客户提供的接入层流量模型分析来看,Gzip单个模块 CPU 消耗占比达到 15%-20% 左右,且占比呈上升趋势。所以,若能使用加速Nginx的网页压缩处理,可以极大的提高网站性能。
表1:Web Server中CPU占用率[2]
Zlib-SHIM API
Zlib作为广泛部署的软件压缩库,提供Deflate压缩的软件实现,被包括Nginx在内的广大应用程序所采用。QAT提供了与Zlib类似接口的Zlib-SHIM 软件库来适配上层应用,减少了应用迁移的开发量。该库提供了与Zlib一致的Deflate API,只需对源代码做少量修改,并将原有应用与Zlib-SHIM编译链接,就能使用QuickAssit提供的硬件加速功能。
Zlib-SHIM库实现了DeflateInit,DeflateInit2,Deflate,DeflateEnd等常用API并支持Stateful和Stateless压缩,可以替代Zlib的绝大部分功能。
Zlib-SHIM提供了Deflate API同步模式接口(调用程序阻塞在Deflate API上,直到压缩任务完成),而其内部实现调用了异步模式API,即在CPU上运行的QAT驱动程序向QAT协处理器提交了一个数据压缩请求后即返回,期间使用Polling 接口定期检查压缩请求是否完成,等到QAT硬件完成压缩处理后通过回调函数通知CPU端的应用程序进行下一步操作。这样的设计, 在不影响上层应用程序原有设计的前提下,实现了高并发场景中CPU和QAT的协同工作:CPU专注于网络连接处理而QAT处理复杂的压缩计算, 各司其职,最终提高了系统整体性能。
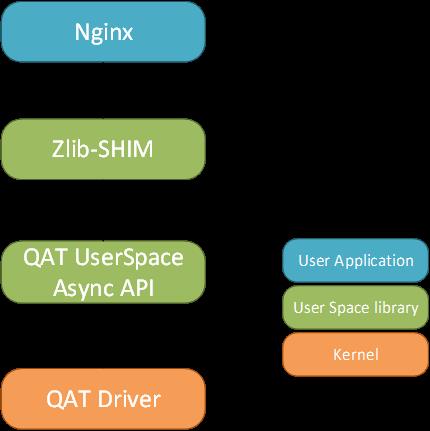
图1: Zlib-SHIM 层次图
Zlib-SHIM工作原理
采用这种异步模式API实现对外的同步接口,在实现上有三种方法:Direct Polling,Indirect Polling Spinning和Indirect Polling Semaphore模式。
使用Direct Polling模式时,Deflate调用者会在当前线程直接调用Polling接口,若压缩结果还没有返回则休眠一段时间后再检查,直到压缩成功后Deflate调用才返回。Direct Polling模式下CPU开销小,但是单个Request从发出到返回结果延迟较长,只有在多进程多线程高并发模式下才能充分发挥QAT的压缩性能。

图2:Direct polling 模式流程图
Indirect Polling模式,是通过创建一个轮询线程定期调用Polling接口来检查压缩请求在QAT协处理器中的执行状态,轮询线程一旦发现有请求执行完毕就通过回调函数(Callback Function)通知CPU端程序进行后续处理。
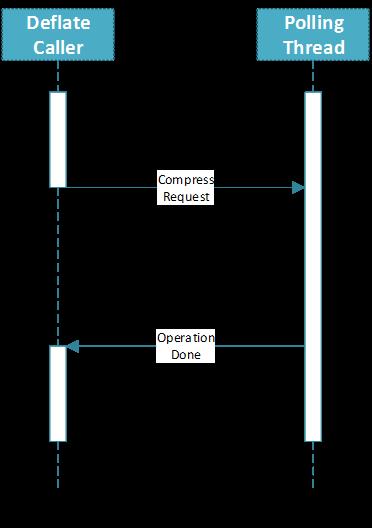
图3:Indirect pooling模式时序图
根据回调通知方式的不同,Indirect Polling模式又可细分为Spinning模式和Semaphore模式:
Spinning模式中,Deflate函数调用线程定期轮询与回调函数共享的任务完成标志,若尚未完成则主动休眠,若已完成则进行后续处理。
Semaphore模式中,Deflate调用线程通过互斥锁来隔离与轮询线程共享的任务完成标志的访问操作,若任务尚未完成则Deflate调用线程休眠,一旦任务完成,轮询线程中的回调函数会通过信号量唤醒调用线程进行后续处理。
采用Indirect Polling模式无论Deflate调用数目多少都需要启动轮询线程,在压缩请求数不大的情况下增加了CPU的Polling开销,但是当压缩任务作为CPU的主要任务时可以减少不必要的Polling调用,提高CPU的使用率。
Nginx为了实现高性能的高并发处理能采用了单进程单线程异步工作模式,如果使用Indirect Polling模式,就需要在每个Nginx Worker进程中创建一个轮询线程 (Polling Thread), 从而增加了线程间切换的开销和共享数据的互斥的操作, 所以在Nginx和Zlib-SHIM集成中,我们使用了Direct Polling Mode。
USDM优化
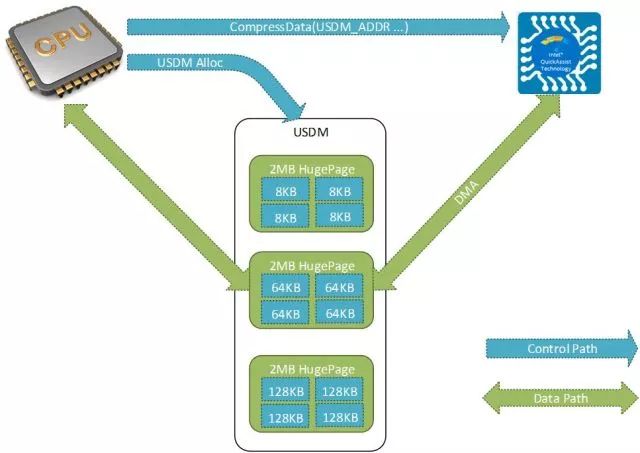
图4: USDM DMA传输
测试结果
基于以上设计的Zlib-SHIM可以很方便的替换原有Zlib库,使得调用者可以方便的利用QAT进行压缩加速。在实际应用中,客户就是将Zlib-SHIM与基于Nginx定制的Web Server进行集成,在接入层的性能优化上取得了理想的效果。
客户的Web Server运行在Intel® Xeon® CPU上(CPU型号:Intel® Xeon® CPU E5-2650 v2 @ 2.60GHz 32核 内核:2.6.32 Zlib版本:zlib-1.2.8 QAT驱动版本:intel-qatOOT40052 ),在相同网络流量条件下,未开启QAT加速的CPU平均使用率为48%左右,而开启QAT加速后CPU平均使用率为41%左右。
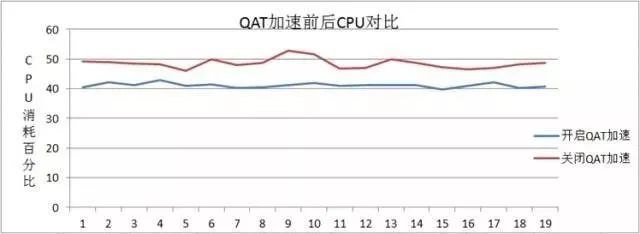
图5:CPU使用率对比[2]
相同条件下,开启QAT加速后系统load平均值为12.09,关闭QAT加速时系统load平均值为14.22,如下图所示:
图6:系统load对比[2]
综合以上数据,Web Server在QPS 10K的压力下,使用QAT加速后可以节省CPU 15%左右,且Gzip基本上完全卸载,随着其占比变高,优化效果将更好。
总结
拥有和Zlib相同API接口的Zlib-SHIM可以很方便的与上层应用集成,利用QAT的硬件加速性能。此外,为了最大限度的发挥QAT的新能,Intel还提供了使用专有API的QATzip软件库,相应的Nginx module也在开发中,相信不久的将来集成QATzip的Web Server能够提供更好的性能。
*性能测试中使用的软件和工作负荷可能仅在英特尔微处理器上进行了性能优化。诸如SYSmark和MobileMark等测试均系基于特定计算机系统、硬件、软件、操作系统及功能。上述任何要素的变动都有可能导致测试结果的变化。请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
参考文献
[1] January 2018 Web Server Survey, netcraft
https://news.netcraft.com/archives/2018/01/19/january-2018-web-server-survey.html
- 责任编辑:-王鹏-
- END -
Linux宝库
为开源爱好者和从业者点亮人生!
以上是关于intel等处理器 介绍的主要内容,如果未能解决你的问题,请参考以下文章
苹果M1可吞噬Intel,但其他ARM芯片相比Intel却太垃圾