Kubernetes 使用 Ingress-nginx 实现灰度发布功能
Posted bigBing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 使用 Ingress-nginx 实现灰度发布功能相关的知识,希望对你有一定的参考价值。
推荐阅读
Helm3(K8S 资源对象管理工具)视频教程:https://edu.csdn.net/course/detail/32506
Helm3(K8S 资源对象管理工具)博客专栏:https://blog.csdn.net/xzk9381/category_10895812.html
本文原文链接:https://blog.csdn.net/xzk9381/article/details/109570832,转载请注明出处。如有发现文章中的任何问题,欢迎评论区留言。
一、Canary 规则说明
Ingress-Nginx 是一个K8S ingress工具,支持配置 Ingress Annotations 来实现不同场景下的灰度发布和测试( Ingress-Nginx 是在0.21.0 版本 中,引入的Canary 功能)。 Nginx Annotations 支持以下 4 种 Canary 规则:
nginx.ingress.kubernetes.io/canary-by-header:基于 Request Header 的流量切分,适用于灰度发布以及 A/B 测试。当 Request Header 设置为 always时,请求将会被一直发送到 Canary 版本;当 Request Header 设置为 never时,请求不会被发送到 Canary 入口;对于任何其他 Header 值,将忽略 Header,并通过优先级将请求与其他金丝雀规则进行优先级的比较。
nginx.ingress.kubernetes.io/canary-by-header-value:要匹配的 Request Header 的值,用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务。当 Request Header 设置为此值时,它将被路由到 Canary 入口。该规则允许用户自定义 Request Header 的值,必须与上一个 annotation (即:canary-by-header)一起使用。
nginx.ingress.kubernetes.io/canary-weight:基于服务权重的流量切分,适用于蓝绿部署,权重范围 0 - 100 按百分比将请求路由到 Canary Ingress 中指定的服务。权重为 0 意味着该金丝雀规则不会向 Canary 入口的服务发送任何请求。权重为 100 意味着所有请求都将被发送到 Canary 入口。
nginx.ingress.kubernetes.io/canary-by-cookie:基于 Cookie 的流量切分,适用于灰度发布与 A/B 测试。用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务的cookie。当 cookie 值设置为 always时,它将被路由到 Canary 入口;当 cookie 值设置为 never时,请求不会被发送到 Canary 入口;对于任何其他值,将忽略 cookie 并将请求与其他金丝雀规则进行优先级的比较。
注意:金丝雀规则按优先顺序进行如下排序:
canary-by-header - > canary-by-cookie - > canary-weight
我们可以把以上的四个 annotation 规则可以总体划分为以下两类:
基于权重的 Canary 规则:
基于用户请求的 Canary 规则:
二、部署测试用例
1. 部署正式版本服务
首先创建一个 deployment 代表正式版本的服务,编写 yaml 内容如下:
---
apiVersion: v1
kind: Namespace
metadata:
name: ns-myapp
labels:
name: ns-myapp
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: production
namespace: ns-myapp
spec:
replicas: 1
selector:
matchLabels:
app: production
template:
metadata:
labels:
app: production
spec:
containers:
- name: production
image: mirrorgooglecontainers/echoserver:1.10
ports:
- containerPort: 8080
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
---
apiVersion: v1
kind: Service
metadata:
name: production
namespace: ns-myapp
labels:
app: production
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: production
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
为这个服务创建 Ingress 路由规则,yaml 文件内容如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: production
namespace: ns-myapp
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: ingress.test.com
http:
paths:
- backend:
serviceName: production
servicePort: 80
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
应用以上 yaml 文件,创建完成后在 k8s 中查看到如下信息:
[k8s-master ~]# kubectl get ingress -n ns-myapp
NAME CLASS HOSTS ADDRESS PORTS AGE
production <none> ingress.test.com 10.16.13.201 80 4m25s
[k8s-master ~]# kubectl get pod -n ns-myapp
NAME READY STATUS RESTARTS AGE
production-5698c4565c-jmjn5 1/1 Running 0 7m11s
1
2
3
4
5
6
7
此时在命令行中访问 ingress.test.com 可以看到如下内容:
# curl ingress.test.com
Hostname: production-5698c4565c-jmjn5
Pod Information:
node name: dumlog013201
pod name: production-5698c4565c-jmjn5
pod namespace: ns-myapp
pod IP: 10.42.0.74
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=10.16.13.201
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://ingress.test.com:8080/
Request Headers:
accept=*/*
host=ingress.test.com
user-agent=curl/7.64.1
x-forwarded-for=10.2.130.18
x-forwarded-host=ingress.test.com
x-forwarded-port=80
x-forwarded-proto=http
x-real-ip=10.2.130.18
x-request-id=3019362be59228ee2284f5737fa39eb1
x-scheme=http
Request Body:
-no body in request-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
本文原文链接:https://blog.csdn.net/xzk9381/article/details/109570832,转载请注明出处。如有发现文章中的任何问题,欢迎评论区留言。
2. 部署 Canary 版本服务
接下来创建一个 Canary 版本的服务,用于作为灰度测试。
参考将上述 Production 版本的 production.yaml 文件,再创建一个 Canary 版本的应用,包括一个 Canary 版本的 deployment 和 service (为方便快速演示,仅需将 production.yaml 的 deployment 和 service 中的关键字 production 直接替换为 canary,实际场景中可能涉及业务代码变更)。
三、基于权重的 Canary 规则测试
基于权重的流量切分的典型应用场景就是蓝绿部署,可通过将权重设置为 0 或 100 来实现。例如,可将 Green 版本设置为主要部分,并将 Blue 版本的入口配置为 Canary。最初,将权重设置为 0,因此不会将流量代理到 Blue 版本。一旦新版本测试和验证都成功后,即可将 Blue 版本的权重设置为 100,即所有流量从 Green 版本转向 Blue。
使用以下 canary.ingress 的 yaml 文件再创建一个基于权重的 Canary 版本的应用路由 (Ingress)。
注意:要开启灰度发布机制,首先需设置 nginx.ingress.kubernetes.io/canary: "true" 启用 Canary,以下 Ingress 示例的 Canary 版本使用了基于权重进行流量切分的 annotation 规则,将分配 30% 的流量请求发送至 Canary 版本。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: canary
namespace: ns-myapp
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "30"
spec:
rules:
- host: ingress.test.com
http:
paths:
- backend:
serviceName: canary
servicePort: 80
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
接下来在命令行中使用如下命令访问域名 ingress.test.com 100次,计算每个版本分配流量的占比:
c=0;p=0;for i in $(seq 100); do result=$(curl -s ingress.test.com | grep Hostname | awk -F: \'print $2\'); [[ $result =~ ^[[:space:]]canary ]] && let c++ || let p++; done;echo "production:$p; canary:$c;"
1
可以得到如下结果:
production:73; canary:28;
1
四、基于用户请求的 Canary 规则测试
1. 基于 Resquest Header
基于 Request Header 进行流量切分的典型应用场景即灰度发布或 A/B 测试场景。
给 Canary 版本的 Ingress 新增一条 annotation :nginx.ingress.kubernetes.io/canary-by-header: canary(这里的 annotation 的 value 可以是任意值),使当前的 Ingress 实现基于 Request Header 进行流量切分。
将 Canary 版本 Ingress 的 yaml 文件修改为如下内容:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: canary
namespace: ns-myapp
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "30"
nginx.ingress.kubernetes.io/canary-by-header: "canary"
spec:
rules:
- host: ingress.test.com
http:
paths:
- backend:
serviceName: canary
servicePort: 80
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
说明:金丝雀规则按优先顺序 canary-by-header - > canary-by-cookie - > canary-weight 进行如下排序,因此上面的 ingress 将忽略原有 canary-weight 的规则。
由于上面的 ingress 规则中没有对 canary-by-header: "canary" 提供具体的值,也就是 nginx.ingress.kubernetes.io/canary-by-header-value 规则,所以在访问的时候,只可以为 canary 赋值 never 或 always,当 header 信息为 canary:never 时,请求将不会发送到 canary 版本;当 header 信息为 canary:always 时,请求将会一直发送到 canary 版本。示例如下:
[k8s-master ~ ]# curl -s -H "canary:never" ingress.test.com | grep Hostname
Hostname: production-5698c4565c-jmjn5
[k8s-master ~ ]# curl -s -H "canary:always" ingress.test.com | grep Hostname
Hostname: canary-79c899d85-992nw
1
2
3
4
5
也可以在上一个 annotation (即 canary-by-header)的基础上添加一条 nginx.ingress.kubernetes.io/canary-by-header-value: user-value 。用于通知 Ingress 将匹配到的请求路由到 Canary Ingress 中指定的服务。
将 Canary 版本 Ingress 的 yaml 文件修改为如下内容:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: canary
namespace: ns-myapp
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "30"
nginx.ingress.kubernetes.io/canary-by-header: "canary"
nginx.ingress.kubernetes.io/canary-by-header-value: "true"
spec:
rules:
- host: ingress.test.com
http:
paths:
- backend:
serviceName: canary
servicePort: 80
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
上面的 ingress 规则设置了 header 信息为 canary:true,也就是只有满足这个 header 值时才会路由到 canary 版本。示例如下:
[k8s-master ~ ]# curl -s ingress.test.com | grep Hostname
Hostname: production-5698c4565c-jmjn5
[k8s-master ~ ]# curl -s -H "canary:test" ingress.test.com | grep Hostname
Hostname: production-5698c4565c-jmjn5
[k8s-master ~ ]# curl -s -H "canary:true" ingress.test.com | grep Hostname
Hostname: canary-79c899d85-992nw
1
2
3
4
5
6
7
8
五、基于 Cookie 的 Canary 规则测试
与基于 Request Header 的 annotation 用法规则类似。例如在 A/B 测试场景 下,需要让地域为北京的用户访问 Canary 版本。那么当 cookie 的 annotation 设置为 nginx.ingress.kubernetes.io/canary-by-cookie: "users_from_Beijing",此时后台可对登录的用户请求进行检查,如果该用户访问源来自北京则设置 cookieusers_from_Beijing 的值为 always,这样就可以确保北京的用户仅访问 Canary 版本。
将 Canary 版本 Ingress 的 yaml 文件修改为如下内容:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: canary
namespace: ns-myapp
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-cookie: "user_from_beijing"
spec:
rules:
- host: ingress.test.com
http:
paths:
- backend:
serviceName: canary
servicePort: 80
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
访问示例如下:
[k8s-master ~ ]# curl -s -b "user_from_beijing=always" ingress.test.com | grep Hostname
Hostname: canary-79c899d85-992nw
[k8s-master ~ ]# curl -s -b "user_from_beijing=no" ingress.test.com | grep Hostname
Hostname: production-5698c4565c-jmjn5
1
2
3
4
5
本文原文链接:https://blog.csdn.net/xzk9381/article/details/109570832,转载请注明出处。如有发现文章中的任何问题,欢迎评论区留言。
————————————————
版权声明:本文为CSDN博主「店伙计」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xzk9381/article/details/109570832
Kubernetes In Action :2开始使用Kubernetes和Docker
2、开始使用Kubernetes和Docker
说明
本章内容涵盖
- 使用Docker创建、运行及共享容器镜像
- 在本地部署单节点的Kubernetes集群
- 在Google Kubernetes Engine上部署Kubernetes集群
- 配置和使用命令行客户端 —— kubectl
- 在Kubernetes上部署应用并进行水平伸缩
在深入学习Kubernetes的概念之前,先来看看如何创建一个简单的应用,把它打包成容器镜像并在远端的Kubernetes集群(如托管在Google Kubernetes Engine中)或本地单节点集群中运行。这会对整个Kubernetes体系有较好的了解,并且会让接下来几个章节对Kubernetes基本概念的学习变得简单。
2.1 创建、运行及共享容器镜像
正如在之前章节所介绍的,在Kubernetes中运行应用需要打包好的容器镜像。本节将会对Docker的使用做简单的介绍。接下来的几节中将会介绍:
- 安装Docker并运行第一个 “Hello world” 容器
- 创建一个简单的Node.js应用并部署在Kubernetes中
- 把应用打包成可以独立运行的容器镜像
- 基于镜像运行容器
- 把镜像推送到Docker Hub,这样任何人在任何地方都可以使用
2.1.1 安装Docker并运行Hello World容器
首先,需要在Linux主机上安装Docker。如果使用的不是Linux操作系统,就需要启动Linux虚拟机(VM)并在虚拟机中运行Docker。如果使用的是Mac或Windows系统,Docker将会自己启动一个虚拟机并在虚拟机中运行Docker守护进程。Docker客户端可执行文件可以在宿主操作系统中使用,并可以与虚拟机中的守护进程通信。
根据操作系统的不同,按照http://docs.docker.com/engine/installation/上的指南安装Docker。安装完成后,可以通过运行Docker客户端可执行文件来执行各种Docker命令。例如,可以试着从Docker Hub的公共镜像仓库拉取、运行镜像,Docker hub中有许多随时可用的常见镜像,其中就包括 busybox,可以用来运行简单的 echo "Hello world" 命令。
运行Hello World容器
busybox是一个单一可执行文件,包含多种标准UNIX命令行工具,如:echo、ls、gzip 等。除了包含 echo 命令的 busybox 命令,也可以使用如Fedora、Ubuntu等功能完备的镜像。
如何才能运行 busybox 镜像呢?无须下载或者安装任何东西。使用 docker run 命令然后指定需要运行的镜像的名字,以及需要执行的命令(可选),如下面这段代码。
代码清单2.1 使用Docker运行一个Hello world容器
$ docker run busybox echo "Hello world"
Unable to find image 'busybox:latest' locally
latest: Pulling from docker.io/busybox
9al63e0b8d13: Pull complete
fef924a0204a: Pull complete
Digest: sha256:97473e34e31le6c1b3f61f2a721d038dle5eef17d98d1353a513007cf46ca6bd
Status: Downloaded newer image for docker.io/busybox:latest
Hello world这或许看起来并不那么令人印象深刻,但非常棒的是仅仅使用一个简单的命令就下载、运行一个完整的“应用”,而不用安装应用或是做其他的事情。目前的应用是单一可执行文件(busybox),但也可以是一个有许多依赖的复杂应用。整个配置运行应用的过程是完全一致的。同样重要的是应用是在容器内部被执行的,完全独立于其他所有主机上运行的进程。
背后的原理
图 2.1 展示了执行 docker run 命令之后发生的事情。首先,Docker会检查busybox:latest 镜像是否已经存在于本机。如果没有,Docker会从http://docker.io的Docker镜像中心拉取镜像。镜像下载到本机之后,Docker基于这个镜像创建一个容器并在容器中运行命令。echo 命令打印文字到标准输出流,然后进程终止,容器停止运行。
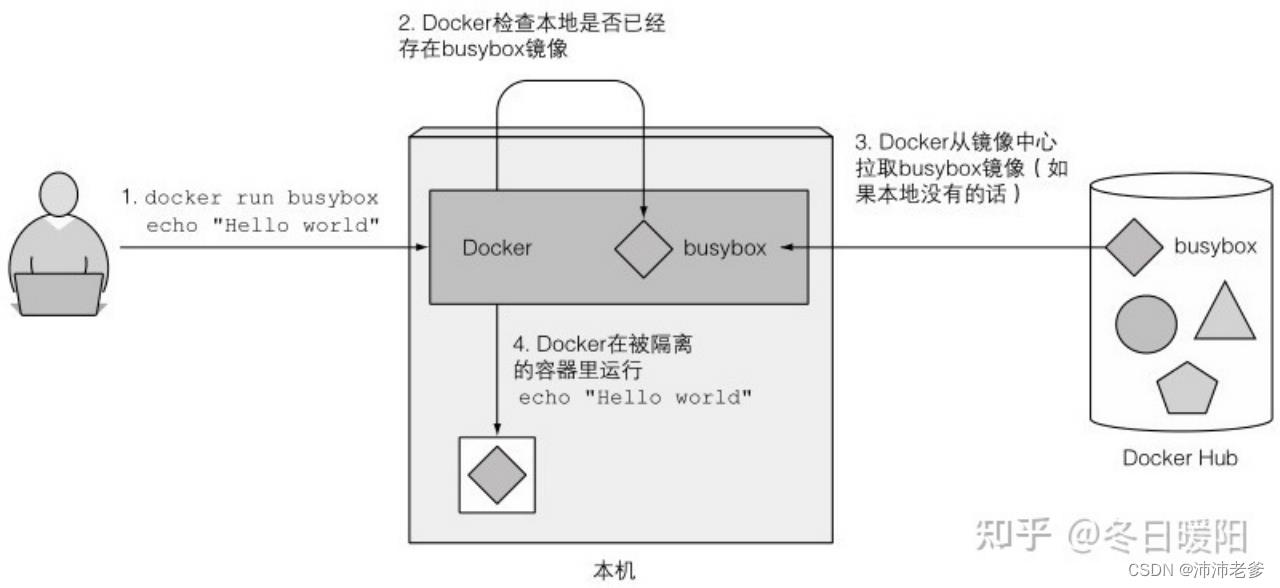 图2.1 在一个基于busybox镜像的容器中运行echo "Hello world"
图2.1 在一个基于busybox镜像的容器中运行echo "Hello world"
运行其他镜像
运行其他的容器镜像和运行busybox镜像是一样的,甚至可能更简单,因为你可以不需要指定执行命令。就像例子中的 echo "Hello world",被执行的命令通常都会被包含在镜像中,但也可以根据需要进行覆盖。在浏览器中搜索http://hub.docker.com或其他公开的镜像中心的可用镜像之后,可以像这样在Docker中运行镜像:
$ docker run <image>容器镜像的版本管理
当然,所有的软件包都会更新,所以通常每个包都不止一个版本。Docker支持同一镜像的多个版本。每一个版本必须有唯一的tag名。当引用镜像没有显式地指定tag时,Docker会默认指定tag为latest。如果想要运行别的版本的镜像,需要像这样指定镜像的版本:
$ docker run <image>:<tag>2.1.2 创建一个简单的 Node.js 应用
现在有了一个可以工作的Docker环境来创建应用。接下来会构建一个简单的Node.js Web应用,并把它打包到容器镜像中。这个应用会接收HTTP请求并响应应用运行的主机名。这样,应用运行在容器中,看到的是自己的主机名而不是宿主机名,即使它也像其他进程一样运行在宿主机上。这在后面会非常有用,当应用部署在Kubernetes上并进行伸缩时(水平伸缩,复制应用到多个节点),你会发现HTTP请求切换到了应用的不同实例上。
应用包含一个名为app.js的文件,详见下面的代码清单。
代码清单2.2 一个简单的Node.js应用:app.js
const http = require('http');const os = require('os');
console.log("Kubia server starting...");
var handler = function(request, response)
console.log("Received request from " + request.connection.remoteAddress);
response.writeHead(200);
response.end("You've hit " + os.hostname() + "\\n");
;
var www = http.createServer(handler);
www.listen(8080);代码清晰地说明了实现的功能。这里在8080端口启动了一个HTTP服务器。服务器会以状态码 200 OK 和文字 "You've hit <hostname>" 来响应每个请求。请求handler会把客户端的IP打印到标准输出,以便日后查看。注意 返回的主机名是服务器真实的主机名,不是客户端发出的HTTP请求中头的 Host 字段。
现在可以直接下载安装Node.js来测试代码了,但是这不是必需的,因为可以直接用Docker把应用打包成镜像,这样在需要运行的主机上就无须下载和安装其他的东西(当然不包括安装Docker来运行镜像)。
2.1.3 为镜像创建Dockerfile
为了把应用打包成镜像,首先需要创建一个叫Dockerfile的文件,它包含了一系列构建镜像时会执行的指令。Dockerfile文件需要和app.js文件在同一目录,并包含下面代码清单中的命令。
代码清单2.3 构建应用容器镜像的Dockerfile
FROM node:7
ADD app.js /app.js
ENTRYPOINT ["node", "app.js"]From 行定义了镜像的起始内容(构建所基于的基础镜像)。这个例子中使用的是 node 镜像的tag 7 版本。第二行中把app.js文件从本地文件夹添加到镜像的根目录,保持app.js这个文件名。最后一行定义了当镜像被运行时需要被执行的命令,这个例子中,命令是 node app.js。
选择基础镜像
你或许在想,为什么要选择这个镜像作为基础镜像。因为这个应用是Node.js应用,镜像需要包含可执行的 node 二进制文件来运行应用。你也可以使用任何包含这个二进制文件的镜像,或者甚至可以使用Linux发行版的基础镜像,如 fedora或ubuntu,然后在镜像构建的时候安装Node.js。但是由于 node镜像是专门用来运行Node.js应用的,并且包含了运行应用所需的一切,所以把它当作基础镜像。
2.1.4 构建容器镜像
现在有了Dockerfile和app.js文件,这是用来构建镜像的所有文件。运行下面的Docker命令来构建镜像:
$ docker build -t kubia 图2.2展示了镜像构建的过程。用户告诉Docker需要基于当前目录(注意命令结尾的点)构建一个叫kubia的镜像,Docker会在目录中寻找Dockerfile,然后基于其中的指令构建镜像。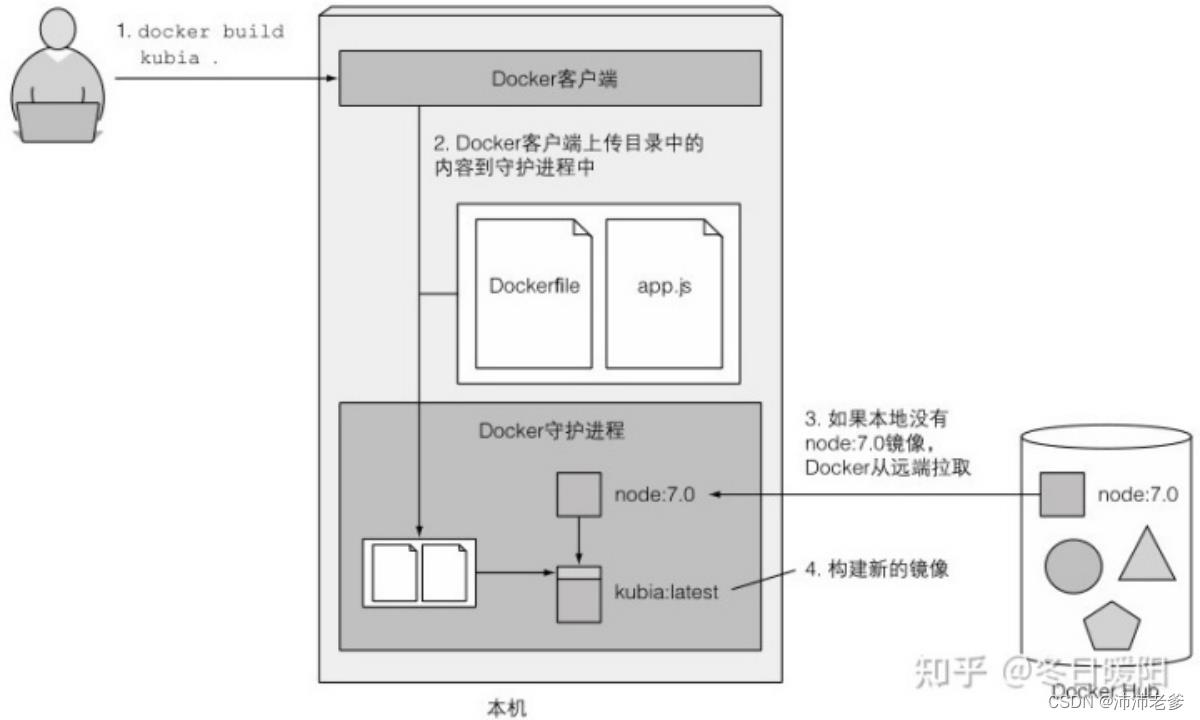
图2.2 基于Dockerfile构建一个新的容器镜像
镜像是如何构建的
构建过程不是由Docker客户端进行的,而是将整个目录的文件上传到Docker守护进程并在那里进行的。Docker客户端和守护进程不要求在同一台机器上。如果你在一台非Linux操作系统中使用Docker,客户端就运行在你的宿主操作系统上,但是守护进程运行在一个虚拟机内。由于构建目录中的文件都被上传到了守护进程中,如果包含了大量的大文件而且守护进程不在本地运行,上传过程会花费更多的时间。
提示 不要在构建目录中包含任何不需要的文件,这样会减慢构建的速度——尤其当Docker守护进程运行在一个远端机器的时候。
在构建过程中,Docker首次会从公开的镜像仓库(Docker Hub)拉取基础镜像(node:7),除非已经拉取过镜像并存储在本机上了。
镜像分层
镜像不是一个大的二进制块,而是由多层组成的,在运行busybox例子时你可能已经注意到(每一层有一行Pull complete),不同镜像可能会共享分层,这会让存储和传输变得更加高效。比如,如果创建了多个基于相同基础镜像(比如例子中的 node:7)的镜像,所有组成基础镜像的分层只会被存储一次。拉取镜像的时候,Docker会独立下载每一层。一些分层可能已经存储在机器上了,所以Docker只会下载未被存储的分层。
你或许会认为每个Dockerfile只创建一个新层,但是并不是这样的。构建镜像时,Dockerfile中每一条单独的指令都会创建一个新层。镜像构建的过程中,拉取基础镜像所有分层之后,Docker在它们上面创建一个新层并且添加app.js。然后会创建另一层来指定镜像被运行时所执行的命令。最后一层会被标记为kubia:latest。图2.3 展示了这个过程,同时也展示另外一个叫 other:latest 的镜像如何与我们构建的镜像共享同一层Node.js镜像。
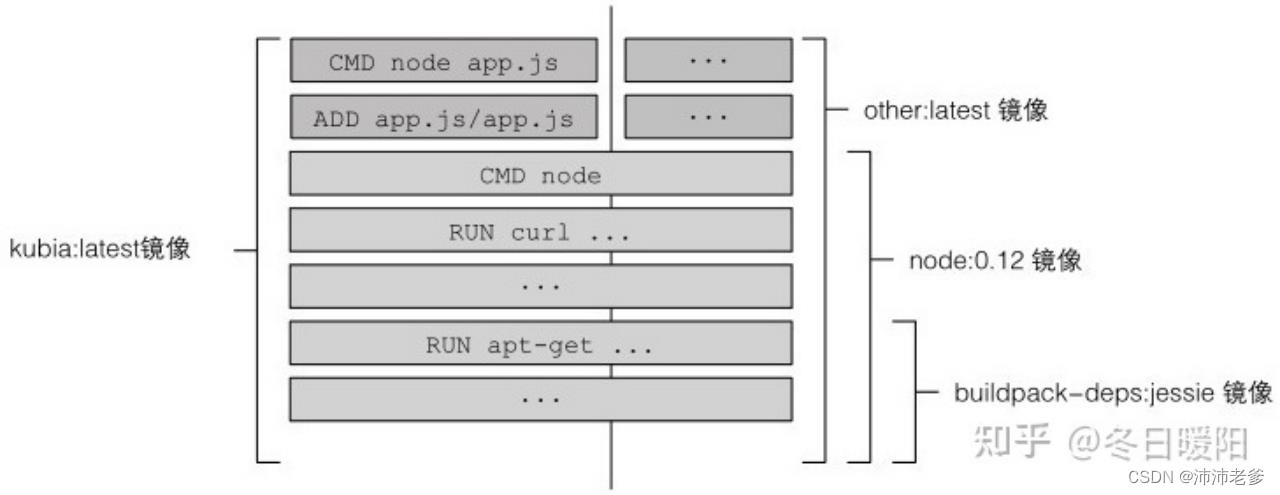 图2.3 容器镜像是由多层组成的,每一层可以被不同镜像复用
图2.3 容器镜像是由多层组成的,每一层可以被不同镜像复用
构建完成时,新的镜像会存储在本地。下面的代码展示了如何通过Docker列出本地存储的镜像:
代码清单2.4 列出本地存储的镜像
s docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
kubia latest d30ecc7419e7 1 minute ago 637.1 MB比较使用Dockerfile和手动构建镜像
Dockerfile是使用Docker构建容器镜像的常用方式,但也可以通过运行已有镜像容器来手动构建镜像,在容器中运行命令,退出容器,然后把最终状态作为新镜像。用Dockerfile构建镜像是与此相同的,但是是自动化且可重复的,随时可以通过修改Dockerfile重新构建镜像而无须手动重新输入命令。
2.1.5 运行容器镜像
以下的命令可以用来运行镜像:
$ docker run --name kubia-container -p 8080:8080 -d kubia这条命令告知Docker基于 kubia 镜像创建一个叫 kubia-container 的新容器。这个容器与命令行分离(-d 标志),这意味着在后台运行。本机上的8080端口会被映射到容器内的8080端口(-p 8080:8080 选项),所以可以通过http://localhost:8080 访问这个应用。
如果没有在本机上运行Docker守护进程(比如使用的是Mac或Windows系统,守护进程会运行在VM中),需要使用VM的主机名或IP来代替localhost运行守护进程。可以通过 DOCKER_HOST 这个环境变量查看主机名。
访问应用
现在试着通过 http://localhost:8080 访问你的应用(确保使用Docker主机名或IP替换localhost):
$ curl localhost:8080
You've hit 44d76963e8e1这是应用的响应。现在应用运行在容器中,与其他东西隔离。可以看到,应用把 44d76963e8e1 作为主机名返回,这并不是宿主机的主机名。这个十六进制数是Docker容器的ID。
列出所有运行中的容器
下面的代码清单列出了所有的运行中的容器,可以查看列表(为了更好的可读性,列表被分成了两行显示)。
代码清单2.5 列出运行中的容器
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9d3e6e24ab3c kubia "node app.js" 4 minutes ago Up 4 minutes 0.0.0.0:8080->8080/tcp kubia-container有一个容器在运行。Docker会打印出每一个容器的ID和名称、容器运行所使用的镜像,以及容器中执行的命令。
获取更多的容器信息
docker ps 只会展示容器的大部分基础信息。可以使用 docker inspect查看更多的信息:
$ docker inspect kubia-containerDocker会打印出包含容器底层信息的长JSON。
2.1.6 探索运行容器的内部
我们来看看容器内部的环境。由于一个容器里可以运行多个进程,所以总是可以运行新的进程去看看里面发生了什么。如果镜像里有可用的shell二进制可执行文件,也可以运行一个shell。
在已有的容器内部运行shell
镜像基于的Node.js镜像包含了bash shell,所以可以像这样在容器内运行shell:
$ docker exec -it kubia-container bash这会在已有的kubia-container容器内部运行bash。bash 进程会和主容器进程拥有相同的命名空间。这样可以从内部探索容器,查看Node.js和应用是如何在容器里运行的。-it 选项是下面两个选项的简写:
- -i,确保标准输入流保持开放。需要在shell中输入命令。
- -t,分配一个伪终端(TTY)。
如果希望像平常一样使用shell,需要同时使用这两个选项(如果缺少第一个选项就无法输入任何命令。如果缺少第二个选项,那么命令提示符不会显示,并且一些命令会提示 TERM 变量没有设置)。
从内部探索容器
下面的代码展示了如何使用shell查看容器内运行的进程。
代码清单2.6 从容器内列出进程
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 1.4 614436 26376 ? Ssl 08:55 0:00 node app.js
root 12 0.1 0.1 20248 3196 pts/0 Ss 09:01 0:00 bash
root 19 0.0 0.1 17504 2000 pts/0 R+ 09:02 0:00 ps aux只看到了三个进程,宿主机上没有看到其他进程。
容器内的进程运行在主机操作系统上
如果现在打开另一个终端,然后列出主机操作系统上的进程,连同其他的主机进程依然会发现容器内的进程,如代码清单2.7所示。
注意 如果使用的是Mac或者Windows系统,需要登录到Docker守护进程运行的VM查看这些进程。
代码清单2.7 运行在主机操作系统上的容器进程
$ ps aux | grep app.js
USER PID CPU MEM vsz RSS TTY STAT START TIME COMMAND
root 382 0.0 0.1 676380 16504 ? S1 12:31 0:00 node app.js这证明了运行在容器中的进程是运行在主机操作系统上的。如果你足够敏锐,会发现进程的ID在容器中与主机上不同。容器使用独立的PID Linux命名空间并且有着独立的系列号,完全独立于进程树。
容器的文件系统也是独立的
正如拥有独立的进程树一样,每个容器也拥有独立的文件系统。在容器内列出根目录的内容,只会展示容器内的文件,包括镜像内的所有文件,再加上容器运行时创建的任何文件(类似日志文件),如下面的代码清单所示。
代码清单2.8 容器拥有完整的文件系统
root@44d76963e8el:/# 1s
app.js boot etc lib mediabin dev home 1ib64 mnt
opt root sbin sys usrpros run srv tmp var其中包含app.js文件和其他系统目录,这些目录是正在使用的 node:7 基础镜像的一部分。可以使用 exit 命令来退出容器返回宿主机(类似于登出ssh session)。
提示 进入容器对于调试容器内运行的应用来说是非常有用的。出错时,需要做的第一件事是查看应用运行的系统的真实状态。需要记住的是,应用不仅拥有独立的文件系统,还有进程、用户、主机名和网络接口。
2.1.7 停止和删除容器
可以通过告知Docker停止 kubia-container 容器来停止应用:
$ docker stop kubia-container因为没有其他的进程在容器内运行,这会停止容器内运行的主进程。容器本身仍然存在并且可以通过 docker ps-a 来查看。-a 选项打印出所有的容器,包括运行中的和已经停止的。想要真正地删除一个容器,需要运行 docker rm :
$ docker rm kubia-container这会删除容器,所有的内容会被删除并且无法再次启动。
2.1.8 向镜像仓库推送镜像
现在构建的镜像只可以在本机使用。为了在任何机器上都可以使用,可以把镜像推送到一个外部的镜像仓库。为了简单起见,不需要搭建一个私有的镜像仓库,而是可以推送镜像到公开可用的Docker Hub(http://hub.docker.com)镜像中心。另外还有其他广泛使用的镜像中心,如http://Quay.io和Google Container Registry。
在推送之前,需要重新根据Docker Hub的规则标注镜像。Docker Hub允许向以你的Docker Hub ID开头的镜像仓库推送镜像。可以在http://hub.docker.com上注册Docker Hub ID。下面的例子中会使用笔者自己的ID(luksa),请在每次出现时替换自己的ID。
使用附加标签标注镜像
一旦知道了自己的ID,就可以重命名镜像,现在镜像由 kubia 改为luksa/kubia(用自己的Docker Hub ID代替 luksa):
$ docker tag kubia luksa/kubia这不会重命名标签,而是给同一个镜像创建一个额外的标签。可以通过docker images 命令列出本机存储的镜像来加以确认,如下面的代码清单所示。
代码清单2.9 一个容器镜像可以有多个标签
# docker images | head
REPOSITORY TAG IMAGE ID CREATED SIZE
kubia v2 8af4d2d1750a 2 minutes ago 82.7MB正如所看到的,kubia 和 luksa/kubia 指向同一个镜像ID,所以实际上是同一个镜像的两个标签。
向Docker Hub推送镜像
在向Docker Hub推送镜像之前,先需要使用 docker login 命令和自己的用户ID登录,然后就可以像这样向Docker Hub推送 yourid/kubia 镜像:
$ docker push luksa/kubia在不同机器上运行镜像
在推送完成之后,镜像便可以给任何人使用。可以在任何机器上运行下面的命令来运行镜像:
$ docker run -p 8080:8080 luksa/kubia这非常简单。最棒的是应用每次都运行在完全一致的环境中。如果在你的机器上正常运行,也会在所有的Linux机器上正常运行。无须担心主机是否安装了Node.js。事实上,就算安装了,应用也并不会使用,因为它使用的是镜像内部安装的。
2.2 配置Kubernetes集群
现在,应用被打包在一个容器镜像中,并通过Docker Hub给大家使用,可以将它部署到Kubernetes集群中,而不是直接在Docker中运行。但是需要先设置集群。
设置一个完整的、多节点的Kubernetes集群并不是一项简单的工作,特别是如果你不精通Linux和网络管理的话。一个适当的Kubernetes安装需要包含多个物理或虚拟机,并需要正确地设置网络,以便在Kubernetes集群内运行的所有容器都可以在相同的扁平网络环境内相互连通。
安装Kubernetes集群的方法有许多。这些方法在http://kubernetes.io的文档中有详细描述。我们不会在这里列出所有,因为内容在不断变化,但Kubernetes可以在本地的开发机器、自己组织的机器集群或是虚拟机提供商(Google Compute Engine、Amazon EC2、Microsoft Azure等)上运行,或者使用托管的Kubernetes集群,如Google Kubernetes Engine(以前称为Google Container Engine)。
在这一章中,将介绍用两种简单的方法构建可运行的Kubernetes集群,你将会看到如何在本地机器上运行单节点Kubernetes集群,以及如何访问运行在Google Kubernetes Engine(GKE)上的托管集群。
第三个选项是使用 kubeadm 工具安装一个集群,这会在附录B中介绍,这里的说明向你展示了如何使用虚拟机建立一个三节点的Kubernetes集群,但是建议你在阅读本书的前11章之后再尝试。
另一个选择是在亚马逊的AWS(Amazon Web Services)上安装Kubernetes。为此,可以查看 kops 工具,它是在前面一段提到的 kubeadm 基础之上构建的,可以在http://github.com/kubernetes/kops中找到。它帮助你在AWS上部署生产级、高可用的Kubernetes集群,并最终会支持其他平台(Google Kubernetes Engine、VMware、vSphere等)。
2.2.1 用Minikube运行一个本地单节点Kubernetes集群
使用Minikube是运行Kubernetes集群最简单、最快捷的途径。Minikube是一个构建单节点集群的工具,对于测试Kubernetes和本地开发应用都非常有用。
虽然我们不能展示与管理多节点应用相关的一些Kubernetes特性,但是单节点集群足以探索本书中讨论的大多数主题。
安装Minikube
Minikube是一个需要下载并放到路径中的二进制文件。它适用于OSX、Linux和Windows系统。最好访问GitHub上的Minikube代码仓库(http://github.com/kubernetes/minikube),按照说明来安装它。
例如,在OSX和Linux系统上,可以使用一个命令下载Minikube并进行设置。对于OSX系统,命令是这样的:
$ curl -Lo minikube https://storage.googleapis.com/minikube/releases/v0.23.0/minikube-darwin-amd64 && chmod +x minikube && sudo mv minikube/usr/local/bin/在Linux系统中,可以下载另一个版本(将URL中的 “darwin” 替换为“linux”)。在Windows系统中,可以手动下载文件,将其重命名为minikube.exe,并把它加到路径中。Minikube在VM中通过VirtualBox或KVM运行Kubernetes,所以在启动Minikube集群之前,还需要安装VM。
使用Minikue启动一个Kubernetes集群
当你在本地安装了Minikube之后,可以立即使用下面的命令启动Kubernetes集群。
代码清单2.10 启动一个Minikube虚拟机
$ minikube start
starting local Kubernetes cluster...
starting vM...
SSH-ing files into vM....
...
kubectl is now configured to use the cluster.启动集群需要花费超过一分钟的时间,所以在命令完成之前不要中断它。
安装Kubernetes客户端(kubectl)
要与Kubernetes进行交互,还需要 kubectl CLI客户端。同样,需要做的就是下载它,并放在路径中。例如,OSX系统的最新稳定版本可以通过以下命令下载并安装:
$ /$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt) /bin/darwin/amd64/kubectl
&& chmod +x kubectl
&& sudo mv kubectl /usr/local/bin/要下载用于Linux或Windows系统的kubectl,用 linux 或 windows 替换URL中的 darwin。
注意 如果你需要使用多个Kubernetes集群(例如,Minikube和GKE),请参考附录A,了解如何在不同的 kubectl 上下文中设置和切换。
使用kubectl查看集群是否正常工作
要验证集群是否正常工作,可以使用以下所示的 kubectl cluster-info命令。
代码清单2.11 展示集群信息
$ kubectl cluster-info
Kubernetes master is running at https://192.168.99.100:8443
KubeDNS is running at https://192.168.99.100:8443/api/v1/proxy/...
kubernetes-dashboard is running at https://192.168.99.100:8443/api/v1/.....这里显示集群已经启动。它显示了各种Kubernetes组件的URL,包括API服务器和Web控制台。
提示 可以运行 minikube ssh 登录到Minikube VM并从内部探索它。例如,可以查看在节点上运行的进程。
2.2.2 使用Google Kubernetes Engine托管Kubernetes集群
如果你想探索一个完善的多节点Kubernetes集群,可以使用托管的Google Kubernetes Engine(GKE)集群。这样,无须手动设置所有的集群节点和网络,因为这对于刚开始使用Kubernetes的人来说太复杂了。使用例如GKE这样的托管解决方案可以确保不会出现配置错误、不工作或部分工作的集群。
配置一个Google Cloud项目并且下载必需的客户端二进制
在设置新的Kubernetes集群之前,需要设置GKE环境。因为这个过程可能会改变,所以不在这里列出具体的说明。阅读https://cloud.google.com/containerengine/docs/before-begin中的说明后就可以开始了。
整个过程大致包括:
- 注册谷歌账户,如果你还没有注册过。
- 在Google Cloud Platform控制台中创建一个项目。
- 开启账单。这会需要你的信用卡信息,但是谷歌提供了为期12个月的免费试用。而且在免费试用结束后不会自动续费。
- 开启Kubernetes Engine API。
- 下载安装Google Cloud SDK(这包含 gcloud 命令行工具,需要创建一个Kubernetes集群)。
- 使用 gcloud components install kubectl 安装 kubectl 命令行工具。
注意 某些操作(例如步骤2中的操作)可能需要几分钟才能完成,所以在此期间可以喝杯咖啡放松一下。
创建一个三节点Kubernetes集群
完成安装后,可以使用下面代码清单中的命令创建一个包含三个工作节点的Kubernetes集群。
代码清单2.12 在GKE上创建一个三节点集群
$ gcloud container clusters create kubia --num-nodes 3 --machine-tvpe fl-micro
Creating cluster kubia... done
Created [https://container.googleapis.com/y1/proiects/kubial-1227/zones/europe-west1-d/clusters/kubia]
kubeconfig entry generated for kubia.
NAME ZONE MST VER MASTER IP TYPE NODE VER NUM NODES STATUSkubia eu-wld 1.5.3 104.155.92.30 fl-micro 1.5.3: RUNNING
现在已经有一个正在运行的Kubernetes集群,包含了三个工作节点,如图 2.4所示。你在使用三个节点来更好地演示适用于多节点的特性,如果需要的话可以使用较少数量的节点。
获取集群概览
图 2.4 能够让你对集群,以及如何与集群交互有一个初步的认识。每个节点运行着Docker、Kubelet和kube-proxy。可以通过 kubectl 命令行客户端向运行在主节点上的Kubernetes API服务器发出REST请求以与集群交互。
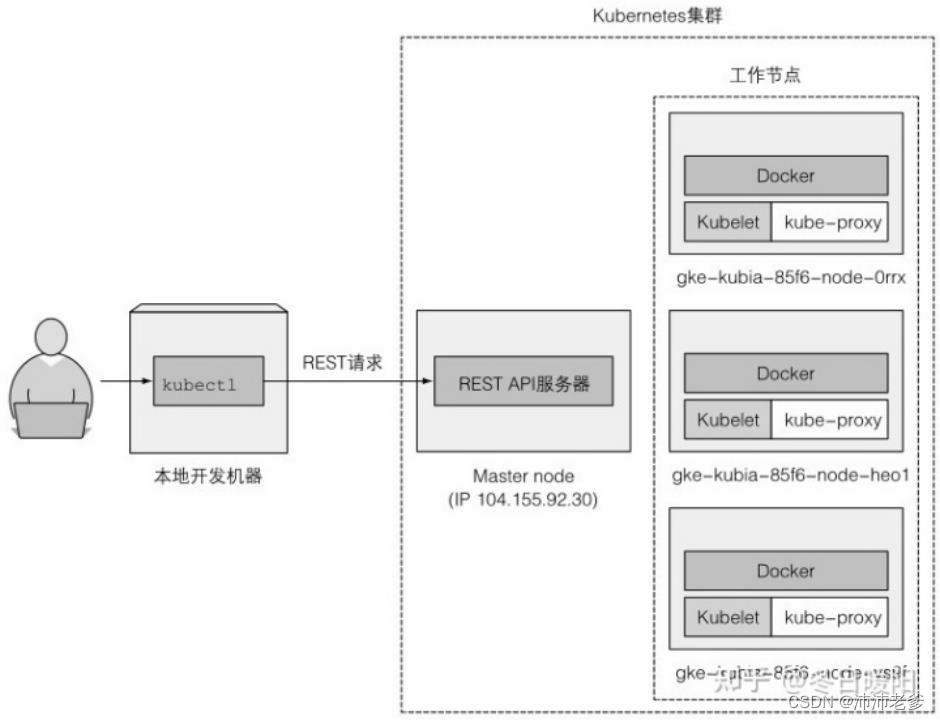
图2.4 如何与三节点Kubernetes集群进行交互
通过列出集群节点查看集群是否在运行
现在可以使用kubectl命令列出集群中的所有节点,如下面的代码清单所示。
代码清单2.13 使用kubectl列出集群节点
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane,master 10h v1.20.2
k8s-node1 NotReady <none> 9h v1.20.2
k8s-node2 NotReady <none> 9h v1.20.2kubectl get 命令可以列出各种Kubernetes对象。你将会经常使用到它,但它通常只会显示对象最基本的信息。
提示 可以使用 gcloud compute ssh <node-name> 登录到其中一个节点,查看节点上运行了什么。
查看对象的更多信息
要查看关于对象的更详细的信息,可以使用 kubectl describe 命令,它显示了更多信息:
# kubectl describe node k8s-master
Name: k8s-master
Roles: control-plane,master
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=k8s-master
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node-role.kubernetes.io/master=
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 12 Feb 2021 21:32:22 +0800
Taints: node-role.kubernetes.io/master:NoSchedule
node.kubernetes.io/not-ready:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: k8s-master
AcquireTime: <unset>
RenewTime: Sat, 13 Feb 2021 07:41:25 +0800
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Sat, 13 Feb 2021 07:38:24 +0800 Fri, 12 Feb 2021 21:32:19 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Sat, 13 Feb 2021 07:38:24 +0800 Fri, 12 Feb 2021 21:32:19 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Sat, 13 Feb 2021 07:38:24 +0800 Fri, 12 Feb 2021 21:32:19 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready False Sat, 13 Feb 2021 07:38:24 +0800 Fri, 12 Feb 2021 21:32:19 +0800 KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
Addresses:
InternalIP: 192.168.137.100
Hostname: k8s-master
Capacity:
cpu: 2
ephemeral-storage: 38770180Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3880576Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 35730597829
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3778176Ki
pods: 110
System Info:
Machine ID: 4eec0f78eb7f4eb8b33480fe97fca874
System UUID: 5A5A9919-F309-7748-9C28-CB280C32FD39
Boot ID: dc707f60-c19b-4883-889a-81cac673950c
Kernel Version: 3.10.0-1160.15.2.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://20.10.3
Kubelet Version: v1.20.2
Kube-Proxy Version: v1.20.2
PodCIDR: 10.244.0.0/24
PodCIDRs: 10.244.0.0/24
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system etcd-k8s-master 100m (5%) 0 (0%) 100Mi (2%) 0 (0%) 10h
kube-system kube-apiserver-k8s-master 250m (12%) 0 (0%) 0 (0%) 0 (0%) 10h
kube-system kube-controller-manager-k8s-master 200m (10%) 0 (0%) 0 (0%) 0 (0%) 10h
kube-system kube-proxy-mskzh 0 (0%) 0 (0%) 0 (0%) 0 (0%) 10h
kube-system kube-scheduler-k8s-master 100m (5%) 0 (0%) 0 (0%) 0 (0%) 10h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 650m (32%) 0 (0%)
memory 100Mi (2%) 0 (0%)
ephemeral-storage 100Mi (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeHasSufficientMemory 10h (x5 over 10h) kubelet Node k8s-master status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 10h (x5 over 10h) kubelet Node k8s-master status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 10h (x4 over 10h) kubelet Node k8s-master status is now: NodeHasSufficientPID
Normal Starting 10h kubelet Starting kubelet.
Normal NodeHasSufficientMemory 10h kubelet Node k8s-master status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 10h kubelet Node k8s-master status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 10h kubelet Node k8s-master status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 10h kubelet Updated Node Allocatable limit across pods
Normal Starting 10h kube-proxy Starting kube-proxy.
Normal Starting 18m kubelet Starting kubelet.
Normal NodeHasSufficientMemory 18m (x8 over 18m) kubelet Node k8s-master status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 18m (x8 over 18m) kubelet Node k8s-master status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 18m (x7 over 18m) kubelet Node k8s-master status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 18m kubelet Updated Node Allocatable limit across pods
Normal Starting 18m kube-proxy Starting kube-proxy.这里省略了 describe 命令的实际输出,因为内容非常多且在书中是完全不可读的。输出显示了节点的状态、CPU和内存数据、系统信息、运行容器的节点等。
在前面的 kubectl describe 示例中,显式地指定了节点的名称,但也可以执行一个简单的 kubectl describe node 命令,而无须指定节点名,它将打印出所有节点的描述信息。
提示 当只有一个给定类型的对象存在时,不指定对象名就运行 description和 get 命令是很提倡的,这样不会浪费时间输入或复制、粘贴对象的名称。
当我们讨论减少输入的时候,开始在Kubernetes运行第一个应用程序之前,先学习如何让 kubectl 命令的使用变得更容易。
2.2.3 为kubectl配置别名和命令行补齐
kubectl 会被经常使用。很快你就会发现每次不得不打全命令是非常痛苦的。在继续之前,花一分钟为kubectl 设置别名和tab命令补全可让使用变得简单。
创建别名
在整本书中,一直会使用 kubectl 可执行文件的全名,但是你可以添加一个较短的别名,如 k,这样就不用每次都输入 kubectl 了。如果还没有设置别名,这里会告诉你如何定义。将下面的代码添加到 ~/.bashrc 或类似的文件中:
alias k=kubectl注意 如果你已经在用 gcloud 配置集群,就已经有可执行文件 k 了。
为kuebctl配置tab补全
即使使用短别名k,仍然需要输入许多内容。幸运的是,kubectl命令还可以配置bash和zsh shell的代码补全。tab补全不仅可以补全命令名,还能补全对象名。例如,无须在前面的示例中输入整个节点名,只需输入
$ kubectl desc<TAB> no<TAB> gke-ku<TAB>需要先安装一个叫作 bashcompletion 的包来启用bash中的tab命令补全,然后可以运行接下来的命令(也需要加到 ~/.bashrc 或类似的文件中):
$ source <(kubectl completion bash)但是需要注意的是,tab命令行补全只在使用完整的 kubectl 命令时会起作用(当使用别名 k 时不会起作用)。需要改变 kubectl completion 的输出来修复:
$ source <(kubectl completion bash | sed s/kubectl/k/g)注意 不幸的是,在写作本书之时,别名的shell命令补全在MacOS系统上并不起作用。如果需要使用命令行补全,就需要使用完整的 kubectl 命令。
现在你已经准备好无须输入太多就可以与集群进行交互。现在终于可以在Kubernetes上运行第一个应用了。
2.3 在Kubernetes上运行第一个应用
因为这可能是第一次,所以会使用最简单的方法在Kubernetes上运行应用程序。通常,需要准备一个JSON或YAML,包含想要部署的所有组件描述的配置文件,但是因为还没有介绍可以在Kubernetes中创建的组件类型,所以这里将使用一个简单的单行命令来运行应用。
2.3.1 部署Node.js应用
部署应用程序最简单的方式是使用 kubectl run 命令,该命令可以创建所有必要的组件而无需JSON或YAML文件。这样的话,我们就不需要深入了解每个组件对象的结构。试着运行之前创建、推送到Docker Hub的镜像。下面是在Kubernetes中运行的代码:
kubectl run kubia --image=luksa/kubia:v1 --port=8080 --generator=run/v1--image=luksa/kubia 显示的是指定要运行的容器镜像,
--port=8080 选项告诉Kubernetes应用正在监听8080端口。
最后一个标志(--generator)需要解释一下,通常并不会使用到它,它让Kubernetes创建一个ReplicationController,而不是Deployment。稍后你将在本章中了解到什么是ReplicationController,但是直到第9章才会介绍Deployment,所以不会在这里创建Deployment。
正如前面命令的输出所示,已经创建了一个名为kubia的ReplicationController。如前所述,我们将在本章的后面看到。从底层开始,把注意力放在创建的容器上(可以假设已经创建了一个容器,因为在 run 命令中指定了一个容器镜像)。
冬日暖阳的笔记(新版本中已
以上是关于Kubernetes 使用 Ingress-nginx 实现灰度发布功能的主要内容,如果未能解决你的问题,请参考以下文章