学习JavaScript数据结构与算法 第七章
Posted 三槐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习JavaScript数据结构与算法 第七章相关的知识,希望对你有一定的参考价值。
7. 集合
7.4 ESMAScript 2015 --- Set 类
ECMAScript 2015 新增了 Set 类作为 JavaScript API 的一部分。我们可以基于 ES2015 的 Set 开发我们的 Set 类。
const set = new Set()
set.add(1)
console.log(set.values()) // @iterator
console.log(set.has(1))
console.log(set.size)
set.add(2)
set.delete(2)
set.clear()
console.log(set)
ES2015 Set 类的运算
我们的 Set 类实现了并集、交集、差集、子集等数学运算,然而 ES2015 原生的 Set 并没有这些功能。
const setA = new Set();
setA.add(1);
setA.add(2);
setA.add(3);
const setB = new Set();
setB.add(2);
setB.add(3);
setB.add(4);
// 1. 模拟并集运算
function union(setA, setB)
const unionAb = new Set()
setA.forEach(value => unionAb.add(value))
setB.forEach(value => unionAb.add(value))
return unionAb
// 2. 模拟交集运算
function intersection(setA, setB)
const intersectionSet = new Set()
setA.forEach(value =>
if (setB.has(value))
intersectionSet.add(value)
)
return intersectionSet
// 3. 模拟差集运算
function difference(setA, setB)
const differenceSet = new Set()
setA.forEach(value =>
if (!setB.has(value))
differenceSet.add(value)
)
return differenceSet
;
console.log(difference(setA, setB))
// 使用扩展运算符
new Set([...setA, ...setB])
new Set([...setA].filter(x => setB.has(x)))
new Set([...setA].filter(x => !setB.has(x)))
7.5 多重集或袋
拿捏javascript数据结构与算法(中)
下一篇:抽时间补上
知识点:
第七章:集合
第八章:字典和散列表
第九章:递归
第十章:树
第十一章:二叉堆和堆排序
第七章:集合(set)
集合的概念特点
在es6中提出了set()方法,它允许创建唯一值的集合,集合是由一组无序且唯一的项组成,是一种不允许重复的数据结构。集合中的元素可以是简单的数据,也可以是复杂的对象,可以把它理解称为没有重复数据的数组。
特点:
不允许重复的顺序数据结构
语法:
new Set([iterable]);
集合创建
1、声明一个set类
2、add(element):向集合中添加一个新元素
3、delete(element):从集合中删除一个元素
4、has(element):如果元素在集合中,返回true ,否则返回false
5、clear():清除集合中的所有元素
6、size():返回集合中包含元素的数量,与数组中的length属性类似
7、values():返回一个包含集合中所有值的(元素)的数组
代码实现:
class Set {
constructor () {
this.items = {};
}
add (value) { // 向集合中添加元素
if (!this.has(value)) {
this.items[value] = value;
return true;
}
return false;
}
delete (value) { // 从集合中删除对应的元素
if (this.has(value)) {
delete this.items[value];
return true;
}
return false;
}
has (value) { // 判断给定的元素在集合中是否存在
return this.items.hasOwnProperty(value);
}
clear() { // 清空集合内容
this.items = {};
}
size () { // 获取集合的长度
return Object.keys(this.items).length;
}
values () { // 返回集合中所有元素的内容
return Object.values(this.items);
}
}
集合运算
集合运算在数学中我们就学习过,在计算机中也同样被重视,查询数据库的SQL语句的基础就是集合运算。查询后的数据库也会返回一个数据集合
并集
对于给定的两个集合,并集返回一个包含两个集合中所有元素的新集合。
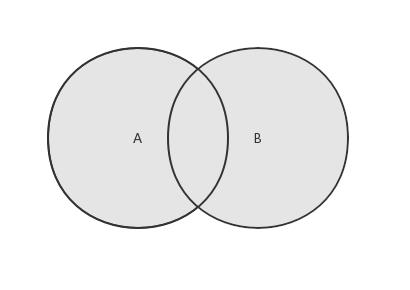
思路:首先遍历第一个集合,将所有的元素添加到新集合中,然后再遍历第二个集合,将所有的元素添加到新集合中。然后返回新集合。不用担心会添加重复的元素,因为集合的add()方法会自动排除掉已添加的元素。
代码实现:
union (otherSet) { // 并集
let unionSet = new Set();
this.values().forEach(value => unionSet.add(value));
otherSet.values().forEach(value => unionSet.add(value));
return unionSet;
}
交集
对于给定的两个集合,交集返回一个包含两个集合中共有元素的新集合
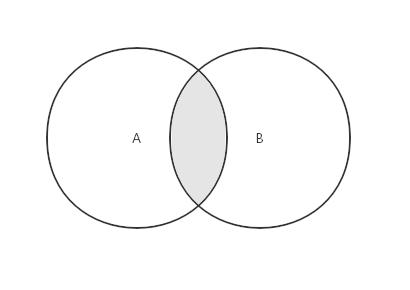
思路:遍历第一个集合,如果元素出现在第二个集合中,则将它添加到新集合。然后返回新集合。
代码实现:
intersection (otherSet) { // 交集
let intersectionSet = new Set();
this.values().forEach(value => {
if (otherSet.has(value)) intersectionSet.add(value);
});
return intersectionSet;
}
差集
对于给定的两个集合,差集返回一个包含所有存在于第一个集合且不存在于第二个集合的元素的新集合
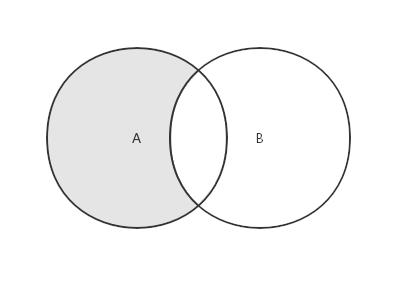
思路:遍历第一个集合,如果元素没有出现在第二个集合中,则将它添加到新集合。然后返回新集合。
代码实现:
difference (otherSet) { // 差集
let differenceSet = new Set();
this.values().forEach(value => {
if (!otherSet.has(value)) differenceSet.add(value);
});
return differenceSet;
}
子集
验证一个给定集合是否是另一个集合的子集,即判断给定的集合中的所有元素是否都存在于另一个集合中,如果是,则这个集合就是另一个集合的子集,反之则不是。
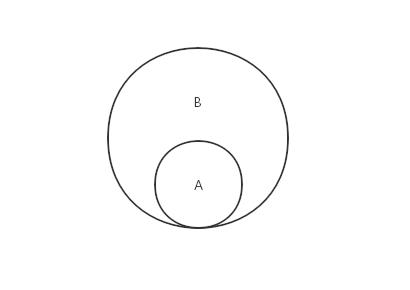
思路:
如果集合A比集合B的长度大,则直接返回false,因为这种情况A不可能是B的子集。然后使用every()函数遍历集合A的所有元素,一旦碰到其中的元素没有在集合B中出现,则直接返回false,并终止遍历
代码实现:
subset (otherSet) { // 子集
if (this.size() > otherSet.size()) return false;
let isSubset = true;
this.values().every(value => {
if (!otherSet.has(value)) {
isSubset = false;
return false;
}
return true;
});
return isSubset;
}
第八章:字典和散列表(Dictionary)
字典的概念和特点
在上一章中我们讲到集合:表示一组不重复的数据,字典和集合的主要区别就在于,集合中数据是以[值,值]的形式保存的,我们只关心值本身;而在字典和散列表中数据是以[键,值]的形式保存的,键不能重复,我们不仅关心键,也关心键所对应的值
字典也被称为:映射,符号表,关联数组。
字典创建
创建方法:
set(key,value ):向字典中添加新元素。如果key存在,那么已经存在的value值也会被新值覆盖
remove(key):通过使用键值作为参数来从字典中移除对应的数据值
hasKey(key):如果某个键值存在于字典中,返回true,否则返回false
get(key):通过以键值作为参数查找特定的数值并返回
clear():删除该字典中的所有值
size():返回字典中所有值的数量,与数组中的length类似
isEmpty():在size等于零的时候返回true,其他时候返回false
keys():将字典中所有的键名以数组的形式返回
values():将字典中所有的键值以数组的形式返回
keyValues():将字典中所有的【键,值】返回
forEach(callbackFn):迭代字典中的所有键值对,有两个参数:key和value
代码实现:
class Dictionary {
constructor () {
this.items = {};
}
set (key, value) { // 向字典中添加或修改元素
this.items[key] = value;
}
get (key) { // 通过键值查找字典中的值
return this.items[key];
}
delete (key) { // 通过使用键值来从字典中删除对应的元素
if (this.has(key)) {
delete this.items[key];
return true;
}
return false;
}
has (key) { // 判断给定的键值是否存在于字典中
return this.items.hasOwnProperty(key);
}
clear() { // 清空字典内容
this.items = {};
}
size () { // 返回字典中所有元素的数量
return Object.keys(this.items).length;
}
keys () { // 返回字典中所有的键值
return Object.keys(this.items);
}
values () { // 返回字典中所有的值
return Object.values(this.items);
}
getItems () { // 返回字典中的所有元素
return this.items;
}
}
散列表的概念和特点
散列表(或者叫哈希表),是一种改进的dictionary,它将key通过一个固定的算法(散列函数或哈希函数)得出一个数字,然后将dictionary中key所对应的value存放到这个数字所对应的数组下标所包含的存储空间中。在原始的dictionary中,如果要查找某个key所对应的value,我们需要遍历整个字典。为了提高查询的效率,我们将key对应的value保存到数组里,只要key不变,使用相同的散列函数计算出来的数字就是固定的,于是就可以很快地在数组中找到你想要查找的value。下面是散列表的数据结构示意图:
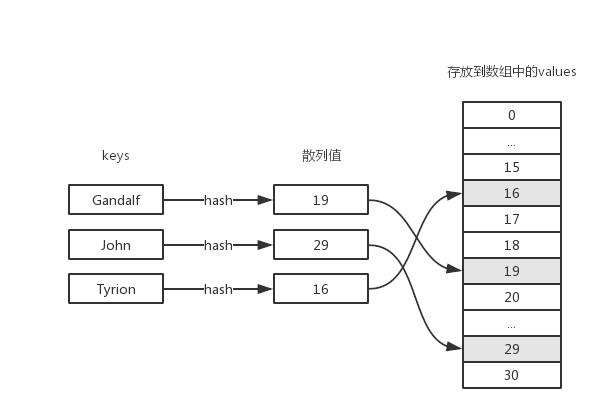
散列表的实现
lose lose 散列函数是比较简单的一种:把每个键值对中的每个字母的ASCII值相加
下面是散列函数loseloseHashCode()的实现代码:
loseloseHashCode (key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % 37;
}
这个散列函数的实现很简单,我们将传入的key中的每一个字符使用charCodeAt()函数(有关该函数的详细内容可以查看这里)将其转换成ASCII码,然后将这些ASCII码相加,最后用37求余,得到一个数字,这个数字就是这个key所对应的hash值。接下来要做的就是将value存放到hash值所对应的数组的存储空间内。下面是我们的HashTable类的主要实现代码:
class HashTable {
constructor () {
this.table = [];
}
loseloseHashCode (key) { // 散列函数
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % 37;
}
put (key, value) { // 将键值对存放到哈希表中
let position = this.loseloseHashCode(key);
console.log(`${position} - ${key}`);
this.table[position] = value;
}
get (key) { // 通过key查找哈希表中的值
return this.table[this.loseloseHashCode(key)];
}
remove (key) { // 通过key从哈希表中删除对应的值
this.table[this.loseloseHashCode(key)] = undefined;
}
isEmpty () { // 判断哈希表是否为空
return this.size() === 0;
}
size () { // 返回哈希表的长度
let count = 0;
this.table.forEach(item => {
if (item !== undefined) count++;
});
return count;
}
clear () { // 清空哈希表
this.table = [];
}
}
第九章: 递归
理解递归
一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。
简单来说就是自己调用自己,把大的问题切分成小的模块解决
计算一个n的阶乘
1、使用循环的方法计算n的阶乘
function xunhuan (number) {
if (number<0,) return underfind;
let tatal = 1;
for (let n = 1, n> 1,n++){
total = total *n;
}
return total ;
}
console.xunhuan(10)
//计算10的阶乘
2、使用递归的方法计算n的阶乘
function factorial (n) {
if ( n === 1 || n === 0){
return 1;}
return n*factorial(n-1);
}
console.log(factorial(10))
//计算10的阶乘
斐波那契数列
斐波那契数列指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N)*
总结来说就是第一第二个数是1 ,后面每个数是前两个数之和
三种计算方法
迭代
递归
记忆求解(缓存出现过两次的计算值 把之前求的值都记录下来)
迭代:
function Fibo(n) {
if(n <= 0) {
return -1;
}
if(n <= 2) {
return 1;
}
let pre = 1; //第一次循环pre是f(1)也就是1
let next = 1; //第一次循环next是f(2)也就是1
let n_value = 0; // 保存f(n)的值
for(let i = 3; i <= n; i++) {
n_value = pre + next; //每一次循环n_value就是前两个数的和
pre = next; // 然后把next赋值给pre
next = n_value; //把新的n_value的值赋值给next
}
return n_value;
}
递归:
function Fibo(n) {
if(n <= 0) {
return -1; //输入的n不合法,返回-1
}
if(n <= 2) {
return 1; // 第一项和第二项为1
} else {
return Fibo(n-2) + Fibo(n-1); // 从第三项开始等于前两项的和
}
}
记忆化:
const fibonacci = (( cache = {} ) => n => {
if( cache[ n ] ){
return cache[ n ];
}
if( n < 2 ){
return cache[ n ] = n;
}
return cache[ n ] = fibonacci( n - 1 ) + fibonacci( n - 2 );
})();
第十章:树
本节参考文章:
JavaScript数据结构——树的实现
树的基本概念和类型
在计算机科学中,树是一种十分重要的数据结构。树被描述为一种分层数据抽象模型,常用来描述数据间的层级关系和组织结构。树也是一种非顺序的数据结构。下图展示了树的定义:
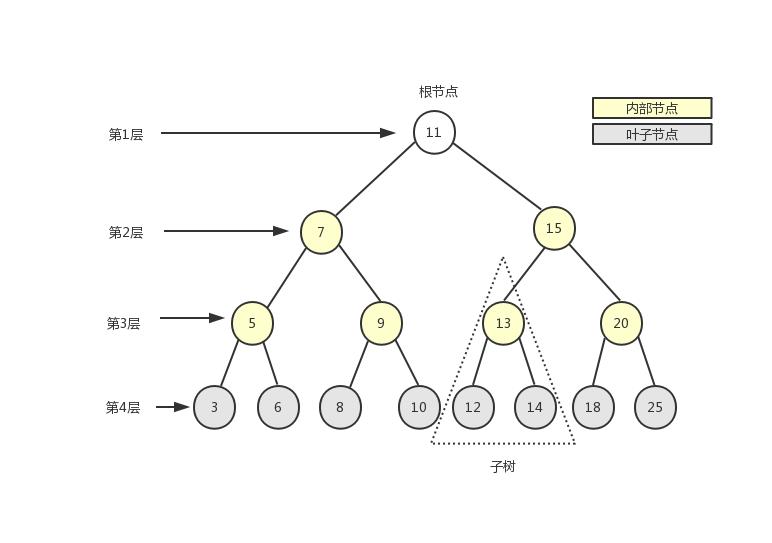
如上图所示,一棵完整的树包含一个位于树顶部的节点,称之为根节点(11),它没有父节点。树中的每一个元素都叫做一个节点,节点分为内部节点(图中显示为黄色的节点)和外部节点(图中显示为灰色的节点),至少有一个子节点的节点称为内部节点,没有子元素的节点称为外部节点或叶子节点。一个节点可以有祖先(根节点除外)和后代。子树由节点本身和它的后代组成,如上图中三角虚框中的部分就是一棵子树。节点拥有的子树的个数称之为节点的度,如上图中除叶子节点的度为0外,其余节点的度都为2。从根节点开始,根为第1层,第一级子节点为第2层,第二级子节点为第3层,以此类推。树的高度(深度)由树中节点的最大层级决定(上图中树的高度为4)。
在一棵树中,具有相同父节点的一组节点称为兄弟节点,如上图中的3和6、5和9等都是兄弟节点。
树的分类:
二叉树,二叉搜索树,自平衡树,红黑树,完全树
在后面的内容中都会详细讲到
本章重点讲二叉搜索树
二叉树和二叉搜索树
二叉树
二叉树中的节点最多只能有两个子节点,一个是左子节点,一个是右子节点。左右子节点的顺序不能颠倒。因此,二叉树中不存在度大于2的节点。
二叉搜索树(BST——Binary Search Tree)是二叉树的一种,它规定在左子节点上存储小(比父节点)的值,在右子节点上(比父节点)存储大(或等于)的值。上图就是一个二叉搜索树。
根据二叉树的描述,一个节点最多只有两个子节点,我们可以使用《JavaScript数据结构——链表的实现与应用》一文中的双向链表来实现二叉搜索树中的每一个节点。下面是二叉搜索树的数据结构示意图:

代码实现:
class BinarySearchTree {
constructor () {
this.root = null;
}
// 向树中插入一个节点
insert (key) {}
// 在树中查找一个节点
search (key) {}
// 通过中序遍历方式遍历树中的所有节点
inOrderTraverse () {}
// 通过先序遍历方式遍历树中的所有节点
preOrderTraverse () {}
// 通过后序遍历方式遍历树中的所有节点
postOrderTraverse () {}
// 返回树中的最小节点
min () {}
// 返回树中的最大节点
max () {}
// 从树中移除一个节点
remove (key) {}
}
在DoubleLinkedList类中,每一个节点有三个属性:element、next和prev。我们在这里用element表示树中节点的key,用next表示树中节点的右子节点(right),用prev表示树中节点的左子节点(left)。
insert (key) {
let newNode = new Node(key);
if (this.root === null) this.root = newNode;
else insertNode(this.root, newNode);
}
当树的root为null时,表示树为空,这时直接将新添加的节点作为树的根节点。否则,我们需要借助于私有函数insertNode()来完成节点的添加。在insertNode()函数中,我们需要根据新添加节点的key的大小来递归查找树的左侧子节点或者右侧子节点,因为根据我们的二叉搜索树的定义,值小的节点永远保存在左侧子节点上,值大的节点(包括值相等的情况)永远保存在右侧子节点上。下面是insertNode()函数的实现代码:
let insertNode = function (node, newNode) {
if (newNode.element < node.element) {
if (node.prev === null) node.prev = newNode;
else insertNode(node.prev, newNode);
}
else {
if (node.next === null) node.next = newNode;
else insertNode(node.next, newNode);
}
};
自平衡树(ALV树)
上面的BST树(二叉搜索树)存在一个问题,树的一条边可能会非常深,而其它边却只有几层,这会在这条很深的分支上添加、移除和搜索节点时引起一些性能问题。如下图所示:
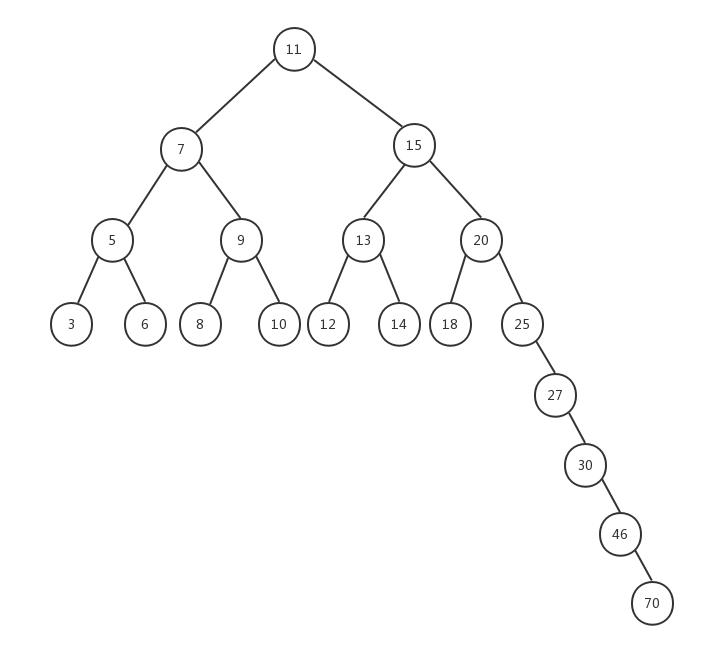
为了解决这个问题,我们引入了自平衡二叉搜索树(AVL——Adelson-Velskii-Landi)。在AVL中,任何一个节点左右两棵子树的高度之差最多为1,添加或移除节点时,AVL树会尝试自平衡。对AVL树的操作和对BST树的操作一样,不同点在于我们还需要重新平衡AVL树,在讲解对AVL树的平衡操作之前,我们先看一下什么是AVL树的平衡因子。
前面我们介绍过什么是树(子树)的高度,对于AVL树来说,每一个节点都保存一个平衡因子。
节点的平衡因子 = 左子树的高度 - 右子树的高度
观察下面这棵树,我们在上面标注了每个节点的平衡因子的值:
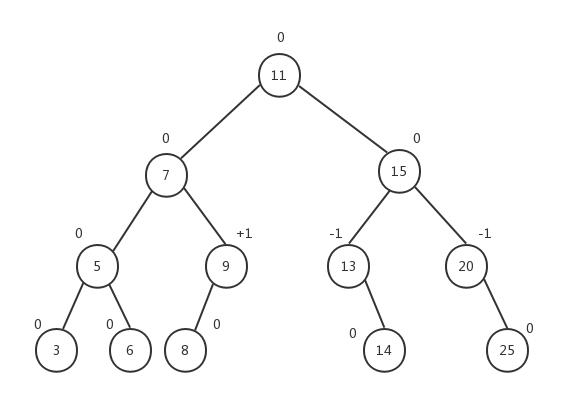
所有子节点的平衡因子都为0,因为子节点没有子树。节点5的左右子树的高度都为1,所以节点5的平衡因子是0。节点9的左子树高度为1,右子树高度为0,所以节点9的平衡因子是+1。节点13的左子树高度为0,右子树高度为1,所以节点13的平衡因子是-1…AVL树的所有节点的平衡因子保持三个值:0、+1或-1。同时,我们也注意到,当某个节点的平衡因子为+1时,它的子树是向左倾斜的(left-heavy);而当某个节点的平衡因子为-1时,它的子树是向右倾斜的(right-heavy);当节点的平衡因子为0时,该节点是平衡的。一颗子树的根节点的平衡因子代表了该子树的平衡性。
以上是关于学习JavaScript数据结构与算法 第七章的主要内容,如果未能解决你的问题,请参考以下文章