Python全栈__字符串初识及操作
Posted 芒果不盲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python全栈__字符串初识及操作相关的知识,希望对你有一定的参考价值。
字符串初识及操作
str
\'alex\'、\'1235443543\'、\'[1,2,3]\'。可存放少量数据。
索引、切片、步长
索引编号
正向索引
\'python\'
012345
\'p\'的正向索引编号为0,\'y\'的正向索引编号为1,\'t\'的正向索引编号为2,\'h\'的正向索引编号为3,\'o\'的正向索引编号为4,\'n\'的正向索引编号为5。
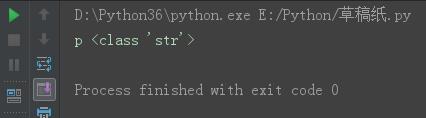
s = \'python\' s1 = s[0] print(s1,type(s1))
结果:
反向索引
python
-6-5-4-3-2-1
n 的反向索引编号为-1,o 的反向索引编号为-2,h 的反向索引编号为-3,t 的反向索引编号为-4,y 的反向索引编号为-5,p 的反向索引编号为-6。
s = \'python\' s4 = s[-1] print(s4)
结果:

切片
格式
字符串[索引起始位编号:索引结束位编号]
切片有个特性,就是顾头不顾尾。
s = \'python3\' s5 = s[0:6] print(s5)
结果:

中括号中的切片起始位索引为为0时,可省略不写。
s = \'python3\' s6 = s[:6] print(s6)
结果:

当中括号中索引位结束编号省略时,默认切片达到字符串结束。
s = \'python3\' s8 = s[1:] print(s8)
结果:

当中括号中索引起始位编号与索引结束位编号都省略时,默认对整个字符串切片,但是切片处的结果与原字符串本质上不是同一个内容(不同的存储位置)。即切片相当于深copy。
s = \'python12期\' s9 = s[:] print(s9)
结果:

步长
在中括号中,索引的结束位后边加上 :(英文冒号)数字 表示截取的步长,即每几位截取一位。只能等距截取。
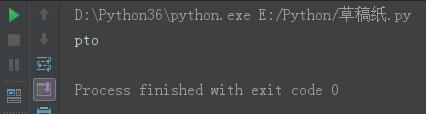
s = \'python3\' s10 = s[:5:2] print(s10)
结果:
当步长为负数时,表示倒序截取。
s = \'python3\' s12 = s[-1:-5:-1] print(s12)
结果:

s = \'python3\' s12 = s[-3:-1] print(s12)
结果:

常用操作方法
.capitalize()
首字母大写,其余字母小写。
s = \'laoNANhai\' s1 = s.capitalize() print(s1)
结果:

.center()
居中
center(a,b)
- a 为设定字符串的总位数,当设定的总位数小于字符串的位数时,不变。
- b 为在空位数上填充的字符。
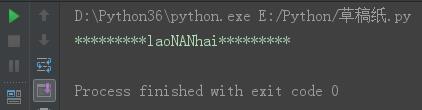
s = \'laoNANhai\' s2 = s.center(27,"*") print(s2)
结果:
.upper()
字符串中的字母全部转换为大写字母,含有数字或者汉字或者特殊符号不会报错,这些字符也不会发生变化。
s = \'laoNANhai\' s3 = s.upper() print(s3)
结果:

.lower()
字符串中的字母全部转换为小写字母,含有数字或者汉字或者特殊符号不会报错,这些字符也不会发生变化。
s = \'laoNANhai\' s4 = s.lower() print(s4)
结果:

通常验证码中会使用这两个方法,例如:
code = \'QAdr\'.upper()
your_code = input("请输入验证码,不分大小写:").upper()
if your_code == code:
print("验证成功")
结果:

.startswith()
判断以什么内容开头,返回值为bool值。判断是以什么内容开头返回值True;不是以什么内容返回值为False。
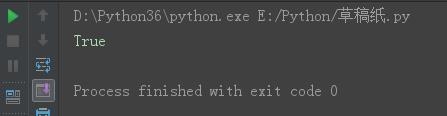
s = \'laoNANhai\' s5 = s.startswith(\'l\') print(s5)
结果:
s = \'laoNANhai\' s6 = s.startswith(\'ao\') print(s6)
结果:

可以传入索引号进行切片,然后判断切片的结果是否以指定的内容为开头。
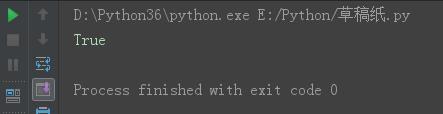
s = \'laoNANhai\' s7 = s.startswith(\'N\',3,6) print(s7)
结果:
.swapcase()
大小写翻转。将字符串中的字母进行大小写翻转,对于字符串中的数字、汉字、特殊符号不进行处理。
s = \'laoNANhai\' s8 = s.swapcase() print(s8)
结果:

.title()
非字母隔开的每个单词首字母大写。
s = \'gdsj wusir6taibai*ritian\' s9 = s.title() print(s9)
结果:

.strip()
去除前后端的空格、换行符、制表符。
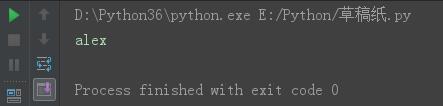
s = \'\\talex\\n\' s16 = s.strip() print(s16)
结果:
通常会在input函数之后搭配使用。例如:
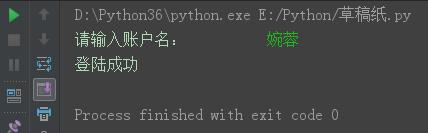
username = input("请输入账户名:").strip() if username == "婉蓉": print("登陆成功")
结果:
.strip(\'a\')
去除字符串两端的指定的字符,某一端当遇到第一个非a字符时,该端停止操作,另一端也遇到非a时完成操作。
s = \' ablabsexsba\' s17 = s.strip(\'a\') print(s17)
结果:

.strip(\'abc\')
当括号内的字符不只一个时,将括号内的内容拆分成单个的最小单元,然后从两端不分顺序的去除,当遇到非括号内的组成单元时,操作结束。
s = \' ablabsexsba\' s18 = s.strip(\'abc\') print(s18)
结果:

.lstrip(\'a\')
去除左端的a字符。
s = \'ablabsexsba\' s19 = s.lstrip(\'a\') print(s19)
结果:

.rstrip(\'a\')
去除右端的a字符。
s = \'ablabsexsba\' s20 = s.rstrip(\'a\') print(s20)
结果:

.split()
str ---> list。默认以空格隔开。
s = \'wusir alex taibai\' s21 = s.split() print(s21)
结果:

也可以指定分割依据。
s = \'wusir,alex,taibai\' s22 = s.split(\',\') print(s22)
结果:

.split(\'a\',b)
b为数字,也可以设定以a隔开,然后设定隔开前b个a,后边如果再有a,不考虑。
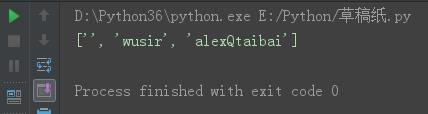
s = \'QwusirQalexQtaibai\' s23 = s.split(\'Q\', 2) print(s23)
结果:
.join()
加入,拼接。
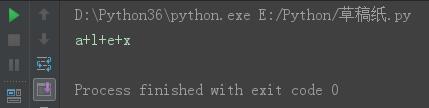
s = \'alex\' s24 = \'+\'.join(s) print(s24)
结果:
当S为列表时,list ---> str 。
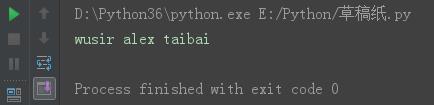
s = [\'wusir\', \'alex\', \'taibai\'] s25 = \' \'.join(s) print(s25)
结果:
.replace(\'a\',\'b\')
a为被替换的内容,b为替换后的内容。
s = \'小粉嫩小粉嫩ghlasdfg小粉嫩\' s26 = s.replace(\'小粉嫩\', \'大铁锤\') print(s26)
结果:

replace(\'a\',\'b\',c)
a为被替换的内容,b为替换后的内容,c为数字,意为从左至右将前c个a替换为b。
s = \'小粉嫩小粉嫩ghlasdfg小粉嫩\' s27 = s.replace(\'小粉嫩\', \'大铁锤\', 2) print(s27)
结果:

通过元素找索引
.index()
通过元素找索引,可切片,找不到报错。
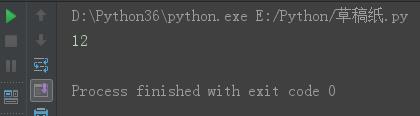
s = \'gdsj wusir6taibai*ritian\' s10 = s.index(\'a\') print(s10)
结果:
找不到报错。
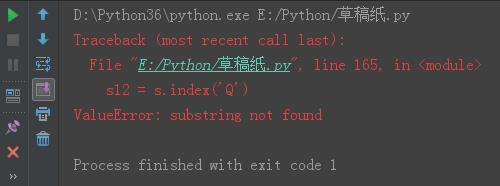
s = \'gdsj wusir6taibai*ritian\' s12 = s.index(\'Q\') print(s12)
结果:
.find()
通过元素找索引,可切片,找不到返回-1。
源码:
def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.find(sub[, start[, end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0
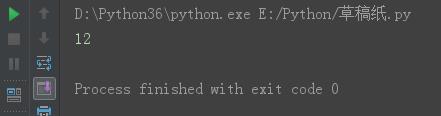
s = \'gdsj wusir6taibai*ritian\' s13 = s.find(\'a\') print(s13)
结果:
找不到返回-1,可以设置匹配的起始位置,传入索引即可。
s = \'gdsj wusir6taibai*ritian\' s14 = s.find(\'A\',2) print(s14)
结果:
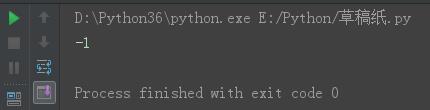
s = \'gdsj wusir6taibai*ritian\' s15 = s.find(\'Q\') print(s15)
结果:

\\t
缩进符,缩进一个Tab键的距离。
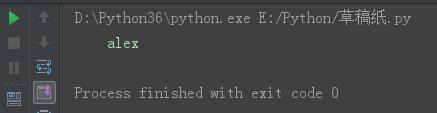
s = \'\\talex\' print(s)
结果:
\\n
换行符
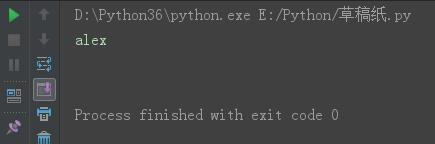
ss = \'alex\\n\' print(ss)
结果:
s = \'\\talex\\n\' print(s)
结果:

公共方法
len()
统计字符串的总个数。
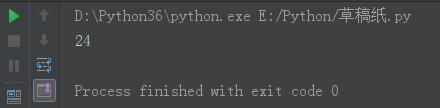
s = \'fdsajlskgjdsaf;jdskfsdaf\' print(len(s))
结果:
.count()
计算某些元素出现的个数,可切片。
s = \'fdsajlskgjdsaf;jdskfsdaf\' s28 = s.count(\'f\') print(s28)
结果:

format
格式化输出
{} 占位符
msg = \'我是{},今年{},喜欢{}\'.format(\'太白\', \'20\',\'girl\')
print(msg)
结果:

{} 占位符,大括号中指定参数
msg = \'我是{0},今年{1},喜欢{2},我依然叫{0}\'.format(\'太白\', \'20\',\'girl\')
print(msg)
结果:

关键字传参
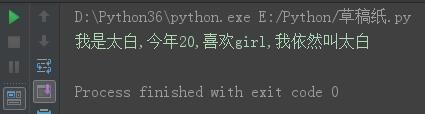
msg = \'我是{name},今年{age},喜欢{hobby},我依然叫{name}\'\\
.format(name = \'太白\', age = \'20\',hobby = \'girl\')
print(msg)
结果:
.isalnum()
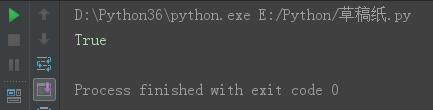
判断字符串由字母、数字组成,返回值为布尔值。是则返回True,否则返回False。
name = \'jinxin123\' print(name.isalnum())
.isalpha()
判断字符串只由字母组成,是则返回True,否则返回False。
name = \'jinxin123\' print(name.isalpha())
结果:
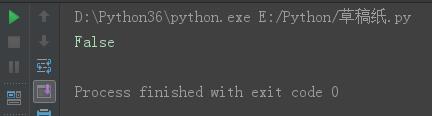
.isdigit()
判断字符串只由数字组成,是则返回True,否则返回False。
name = \'jinxin123\' print(name.isdigit())
结果:

字符串运算
字符串:可加、可乘。
+
加(拼接)
str + str 字符串的拼接
msg1 = \'一去紫台连朔漠,\' msg2 = \'独留青冢向黄昏。\' print(msg1 + msg2)
结果:

*
相乘
str * int
msg = \'哈哈\' print(msg * 8)
结果:

以上是关于Python全栈__字符串初识及操作的主要内容,如果未能解决你的问题,请参考以下文章