C#使用词嵌入向量与向量数据库为大语言模型(LLM)赋能长期记忆实现私域问答机器人落地
Posted a1010
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C#使用词嵌入向量与向量数据库为大语言模型(LLM)赋能长期记忆实现私域问答机器人落地相关的知识,希望对你有一定的参考价值。
本文将探讨如何使用c#开发基于大语言模型的私域聊天机器人落地。大语言模型(Large Language Model,LLM 这里主要以chatgpt为代表的的文本生成式人工智能)是一种利用深度学习方法训练的能够生成人类语言的模型。这种模型可以处理大量的文本数据,并学习从中获得的模式,以预测在给定的文本上下文中最可能出现的下一个词。 在一般场景下LLM可以理解用户提出的问题并生成相应的回答。然而由于其训练时的数据限制LLM无法处理特定领域的问题。因此我们需要探索一种方法让LLM能够获取并利用长期记忆来提高问答机器人的效果。
这里我们主要是用到了词嵌入向量表示以及对应的向量数据库持久化存储,并且通过相似度计算得到长期记忆用于模型对特定领域的特定问题进行作答。词嵌入是自然语言处理(NLP)中的一个重要概念,它是将文本数据转换成数值型的向量,使得机器可以理解和处理。词嵌入向量可以捕获词语的语义信息,如相似的词语会有相似的词嵌入向量。而向量数据库则是一种专门用来存储和检索向量数据的数据库,它可以高效地对大量的向量进行相似性搜索。
目标:如何利用C#,词嵌入技术和向量数据库,使LLM实现长期记忆,以落地私域问答机器人。基于以上目的,我们需要完成以下几个步骤,从而实现将大语言模型与私域知识相结合来落地问答机器人。
一、私域知识的构建与词嵌入向量的转换
首先我们应该收集私域知识的文本语料,通过清洗处理得到高质量的语意文本。接着我们将这些文本通过调用OpenAI的词嵌入向量接口转化为词嵌入向量表示的数组
这里我们以ChatGLM为例,ChatGLM是清华大学开源的文本生成式模型,其模型开源于2023年。所以在ChatGPT的知识库中并不会包含相关的领域知识。当直接使用ChatGPT进行提问时,它的回答是这样的
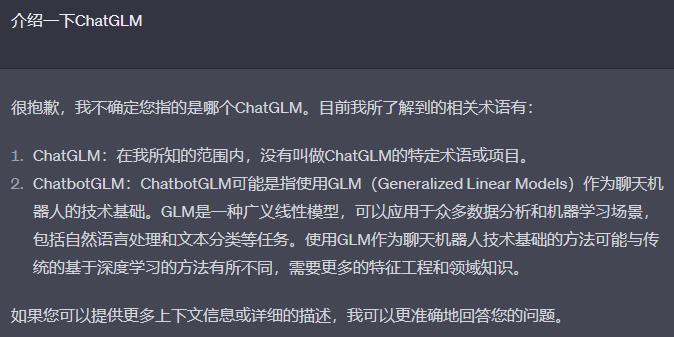
由于只是演示这里我们只准备一条关于chatglm的知识。通过调用openai的接口,将它转化成词嵌入向量
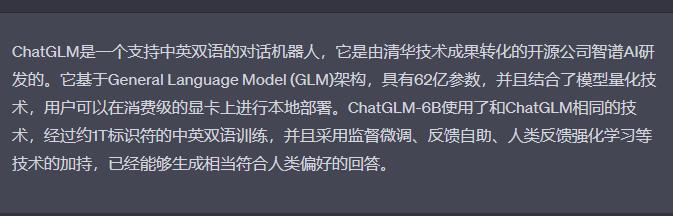
原始语料:ChatGLM是一个开源的清华技术成果转化的公司智谱AI研发的支持中英双语的对话机器人它支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
接着准备好一个openai的开发者key,我们将这段文本转化成词嵌入,这里我使用Betalgo.OpenAI.GPT3这个Nuget包,具体代码如下:
var embeddings = await new OpenAiOptions() ApiKey = key .Embeddings.CreateEmbedding(new EmbeddingCreateRequest()
InputAsList = inputs.ToList(),
Model = OpenAI.GPT3.ObjectModels.Models.TextEmbeddingAdaV2
);
return embeddings.Data.Select(x => x.Embedding).ToList();
这里的inputs就是你的句子数组,由于这个接口可以一次处理多条句子,所以这里可以传入句子数组来实现批处理。
接着这里会返回词嵌入向量结果,类似如下的list<double>:
[-0.0020597207,-0.012355088,0.0037828966,-0.032127112,-0.04815184,0.016633095,-0.01277577,........]
二、对词嵌入向量的理解和使用
接着我们需要使用一个向量数据库,这里由于只是演示,我就是用elasticsearch这样的支持向量存储的搜索引擎来保存。这里我使用NEST作为操作ES的包
首先我们构建一个对应的实体用于读写ES,这里的向量维度1536是openai的词嵌入向量接口的数组长度,如果是其他词嵌入技术,则需要按需定义维度
public class ChatGlmVector
public ChatGlmVector()
Id = Id ?? Guid.NewGuid().ToString();
[Keyword]
public string Id get; set;
[Text]
public string Text get; set;
[DenseVector(Dimensions = 1536)]
public IList<double> Vector get; set;
接着我们使用NEST创建一个索引名(IndexName)并存储刚才得到的文本和向量表示,这里的item就是上文的ChatGlmVector实例。
if (!elasticClient.Indices.Exists(IndexName).Exists) elasticClient.Indices.Create(IndexName, c => c.Map<ChatGlmVector>(m => m.AutoMap())); await elasticClient.IndexAsync(item, idx => idx.Index(IndexName));
三、用户问题的处理与相似度计算
用户问题的处理和知识处理相似,将用户问题转化成词嵌入向量。这里主要讲一下如何基于ES做相似度搜索,以下是原始的请求es的json表示
POST /my_index/_search
"size": 3, // 返回前3个最相似的文档
"query":
"function_score":
"query":
"match_all":
,
"functions": [
"script_score":
"script":
"source": "def cosineSim = cosineSimilarity(params.queryVector, \'vector\'); if (cosineSim > 0.8) return cosineSim; else return 0;",
"params":
"queryVector": [1.0, 2.0, 3.0] // 要查询的向量
],
"boost_mode": "replace"
我们在c#中使用NEST的表示可以通过如下代码来完成,这里我们以0.8作为一个阈值来判断相似度最低必须高于这个数字,否则可以判断用户问题与知识没有关联性。当然这个值可以根据实际情况调整。
var scriptParams = new Dictionary<string, object>
"queryVector", new double[]1.0, 2.0, 3.0
;
var script = new InlineScript("def cosineSim = cosineSimilarity(params.queryVector, \'vector\'); if (cosineSim > 0.8) return cosineSim; else return 0;")
Params = scriptParams
;
var searchResponse = client.Search<object>(s => s
.Size(3)
.Query(q => q
.FunctionScore(fs => fs
.Query(qq => qq
.MatchAll()
)
.Functions(fu => fu
.ScriptScore(ss => ss
.Script(sc => script)
)
)
.BoostMode(FunctionBoostMode.Replace)
)
)
);
四、构建精巧的prompt与OpenAI的chat接口的使用
这里我们就可以通过一些混合一些提示+长记忆+用户问题作为完整的prompt喂给chatgpt得到回答
return (await GetOpenAIService().ChatCompletion.CreateCompletion(new ChatCompletionCreateRequest()
Messages=new List<ChatMessage>()
ChatMessage.FromUser("你是一个智能助手,你需要根据下面的事实依据回答问题。如果用户输入不在事实依据范围内,请说\\"抱歉,这个问题我不知道。\\""),
ChatMessage.FromUser($"事实依据:这里需要从ES查询出相似度最高的文本作为LLM的长期记忆"),
ChatMessage.FromUser($"用户输入:这里是用户的原始问题")
,
Model = OpenAI.GPT3.ObjectModels.Models.ChatGpt3_5Turbo
)).Choices.FirstOrDefault().Message;
当我们使用新的提示词提问后,chatgpt就可以准确的告诉你相关的回答:
写在最后
ChatGPT的出现已经彻底改变了这个世界,作为一个开发人员,我们能做的只能尽量跟上技术的脚步。在这个结合C#、词嵌入技术和向量数据库将大语言模型成功应用到私域问答机器人的案例中只是大语言模型落地的冰山一角,这仅仅是开始,我们还有许多可能性等待探索........
13.深度学习(词嵌入)与自然语言处理
笔记转载于GitHub项目:
https://github.com/NLP-LOVE/Introduction-NLP
13. 深度学习与自然语言处理
13.1 传统方法的局限
前面已经讲过了隐马尔可夫模型、感知机、条件随机场、朴素贝叶斯模型、支持向量机等传统机器学习模型,同时,为了将这些机器学习模型应用于 NLP,我们掌握了特征模板、TF-IDF、词袋向量等特征提取方法。而这些方法的局限性表现为如下:
1.数据稀疏
首先,传统的机器学习方法不善于处理数据稀疏问题,这在自然语言处理领域显得尤为突出,语言是离散的符号系统,每个字符、单词都是离散型随机变量。我们通常使用独热向量(one-hot)来将文本转化为向量表示,指的是只有一个元素为1,其他元素全部为 0 的二进制向量。例如:
祖国特征: ["中国","美国","法国"] (这里 N=3)
中国 => 100
美国 => 010
法国 => 001
上面的祖国特征只有 3 个还好,那如果是成千上万个呢?就会有很多的 0 出现,表现为数据的稀疏性。
2.特征模板
语言具有高度的复合型。对于中文而言,偏旁部首构成汉字,汉字构成单词,单词构成短语,短语构成句子,句子构成段落,段落构成文章,随着层级的递进与颗粒度的增大,所表达的含义越来越复杂。
这样的特征模板同样带来数据稀疏的困扰: 一个特定单词很常见,但两个单词的特定组合则很少见,三个单词更是如此。许多特征在训练集中仅仅出现一次,仅仅出现一次的特征在统计学上毫无意义。
3.误差传播
现实世界中的项目,往往涉及多个自然语言处理模块的组合。比如在情感分析中,需要先进行分词,然后进行词性标注,根据词性标注过滤掉一些不重要的词,最后送入到朴素贝叶斯或者支持向量机等机器学习模块进行分类预测。
这种流水线式的作业方式存在严重的误差传播问题,亦即前一个模块产生的错误被输入到下一个模块中产生更大的错误,最终导致了整个系统的脆弱性。
13.2 深度学习与优势
为了解决传统机器学习与自然语言处理中的数据稀疏、人工特征模板和误差传播等问题,人们将注意力转向了另一种机器学习潮流的研究--深度学习。
1.深度学习
深度学习(Deep Leaming, DL )属于表示学习( Representation Learning )的范畴,指的是利用具有一定“深度”的模型来自动学习事物的向量表示(vectorial rpresenation)的一种学习范式。目前,深度学习所采用的模型主要是层数在一层以上的神经网络。如果说在传统机器学习中,事物的向量表示是利用手工特征模板来提取稀疏的二进制向量的话,那么在深度学习中,特征模板被多层感知机替代。而一旦问题被表达为向量,接下来的分类器一样可以使用单层感知机等模型,此刻深度学习与传统手法毫无二致,殊途同归。所以说深度学习并不神秘,通过多层感知机提取向量才是深度学习的精髓。
对于深度学习原理,在之前我的博客中已经介绍了,详细请点击:
http://mantchs.com/2019/08/04/DL/Neural%20Network/
2.用稠密向量解决数据稀疏
神经网络的输出为样本 x 的一个特征向量 h。由于我们可以自由控制神经网络隐藏层的大小,所以在隐藏层得到的 h 的长度也可以控制。即便输人层是词表大小的独热向量、维度高达数十万,隐藏层得到的特征向量依然可以控制在很小的体积,比如100维。
这样的 100 维向量是对词语乃至其他样本的抽象表示,含有高度浓缩的信息。正因为这些向量位于同一个低维空间,我们可以很轻松地训练分类器去学习单词与单词、文档与文档、图片与图片之间的相似度,甚至可以训练分类器来学习图片与文档之间的相似度。由表示学习带来的这一切, 都是传统机器学习方法难以实现的。
3.用多层网络自动提取特征表示
神经网络两层之间一般全部连接(全连接层),并不需要人们根据具体问题具体设计连接方式。这些隐藏层会根据损失函数的梯度自动调整多层感知机的权重矩阵,从而自动学习到隐陬层的特征表示。
该过程完全不需要人工干预,也就是说深度学习从理论上剥夺了特征模板的用武之地。
4.端到端的设计
由于神经网络各层之间、各个神经网络之间的“交流语言”为向量,所以深度学习工程师可以轻松地将多个神经网络组合起来,形成一种端到端的设计。比如之前谈到的情感分析案例中,一种最简单的方案是将文档的每个字符的独热向量按顺序输入到神经网络中,得到整个文档的特征向量。然后将该特征向量输入到多项逻辑斯谛回归分类器中,就可以分类出文档的情感极性了。
整个过程既不需要中文分词,也不需要停用词过滤。因为神经网络按照字符顺序模拟了人类阅读整篇文章的过程,已经获取到了全部的输人。
13.3 word2vec
作为连接传统机器学习与深度学习的桥梁,词向量一直是入门深度学习的第一站。词向量的训练方法有很多种,word2vec 是其中最著名的一种,还有 fastText、Glove、BERT和最近很流行的 XLNet 等。
1.word2vec 的原理在我博客里已经讲解过了,详细介绍见:
http://mantchs.com/2019/08/22/NLP/Word%20Embeddings/
2.训练词向量
了解了词向量的基本原理之后,本节介绍如何调用 HanLP 中实现的词向量模块,该模块接受的训练语料格式为以空格分词的纯文本格式,此处以 MSR 语料库为例。训练代码如下(自动下载语料库):
from pyhanlp import *
import zipfile
import os
from pyhanlp.static import download, remove_file, HANLP_DATA_PATH
def test_data_path():
"""
获取测试数据路径,位于$root/data/test,根目录由配置文件指定。
:return:
"""
data_path = os.path.join(HANLP_DATA_PATH, 'test')
if not os.path.isdir(data_path):
os.mkdir(data_path)
return data_path
## 验证是否存在语料库,如果没有自动下载
def ensure_data(data_name, data_url):
root_path = test_data_path()
dest_path = os.path.join(root_path, data_name)
if os.path.exists(dest_path):
return dest_path
if data_url.endswith('.zip'):
dest_path += '.zip'
download(data_url, dest_path)
if data_url.endswith('.zip'):
with zipfile.ZipFile(dest_path, "r") as archive:
archive.extractall(root_path)
remove_file(dest_path)
dest_path = dest_path[:-len('.zip')]
return dest_path
sighan05 = ensure_data('icwb2-data', 'http://sighan.cs.uchicago.edu/bakeoff2005/data/icwb2-data.zip')
msr_train = os.path.join(sighan05, 'training', 'msr_training.utf8')
## ===============================================
## 以下开始 word2vec
IOUtil = JClass('com.hankcs.hanlp.corpus.io.IOUtil')
DocVectorModel = JClass('com.hankcs.hanlp.mining.word2vec.DocVectorModel')
Word2VecTrainer = JClass('com.hankcs.hanlp.mining.word2vec.Word2VecTrainer')
WordVectorModel = JClass('com.hankcs.hanlp.mining.word2vec.WordVectorModel')
# 演示词向量的训练与应用
TRAIN_FILE_NAME = msr_train
MODEL_FILE_NAME = os.path.join(test_data_path(), "word2vec.txt")
def train_or_load_model():
if not IOUtil.isFileExisted(MODEL_FILE_NAME):
if not IOUtil.isFileExisted(TRAIN_FILE_NAME):
raise RuntimeError("语料不存在,请阅读文档了解语料获取与格式:https://github.com/hankcs/HanLP/wiki/word2vec")
trainerBuilder = Word2VecTrainer();
return trainerBuilder.train(TRAIN_FILE_NAME, MODEL_FILE_NAME)
return load_model()
def load_model():
return WordVectorModel(MODEL_FILE_NAME)
wordVectorModel = train_or_load_model() # 调用函数训练 word2vec
3.单词语义相似度
有了词向量之后,最基本的应用就是查找与给定单词意义最相近的前 N 个单词。
# 打印 单词语义相似度
def print_nearest(word, model):
print(
"\n Word "
"Cosine\n------------------------------------------------------------------------")
for entry in model.nearest(word):
print("%50s\t\t%f" % (entry.getKey(), entry.getValue()))
print_nearest("上海", wordVectorModel)
print_nearest("美丽", wordVectorModel)
print_nearest("购买", wordVectorModel)
print(wordVectorModel.similarity("上海", "广州"))
结果如下:
Word Cosine
------------------------------------------------------------------------
广州 0.616240
天津 0.564681
西安 0.500929
抚顺 0.456107
深圳 0.454190
浙江 0.446069
杭州 0.434974
江苏 0.429291
广东 0.407300
南京 0.404509
Word Cosine
------------------------------------------------------------------------
装点 0.652887
迷人 0.648911
恬静 0.634712
绚丽 0.634530
憧憬 0.616118
葱翠 0.612149
宁静 0.599068
清新 0.592581
纯真 0.589360
景色 0.585169
Word Cosine
------------------------------------------------------------------------
购 0.521070
购得 0.500480
选购 0.483097
购置 0.480335
采购 0.469803
出售 0.469185
低收入 0.461131
分期付款 0.458573
代销 0.456689
高价 0.456320
0.6162400245666504
其中 Cosine 一栏即为两个单词之间的余弦相似度,是一个介于 -1 和 1 之间的值。
4.词语类比
将两个词语的词向量相减,会产生一个新向量。通过与该向量做点积,可以得出一个单词与这两个单词的差值之间的相似度。在英文中,一个常见的例子是 king - man + woman = queen,也就是说词向量的某些维度可能保存着当前词语与皇室的关联程度,另一些维度可能保存着性别信息。
# param A: 做加法的词语
# param B:做减法的词语
# param C:做加法的词语
# return:与(A-B+C) 语义距离最近的词语及其相似度列表
print(wordVectorModel.analogy("日本", "自民党", "共和党"))
结果如下:
[美国=0.71801066, 德米雷尔=0.6803682, 美国国会=0.65392816, 布什=0.6503047, 华尔街日报=0.62903535, 国务卿=0.6280117, 舆论界=0.6277531, 白宫=0.6175594, 驳斥=0.6155998, 最惠国待遇=0.6062231]
5.短文本相似度
我们将短文本中的所有词向量求平均,就能将这段短文本表达为一个稠密向量。于是我们就可以衡量任意两端短文本之间鹅相似度了。
# 文档向量
docVectorModel = DocVectorModel(wordVectorModel)
documents = ["山东苹果丰收",
"农民在江苏种水稻",
"奥运会女排夺冠",
"世界锦标赛胜出",
"中国足球失败", ]
print(docVectorModel.similarity("山东苹果丰收", "农民在江苏种水稻"))
print(docVectorModel.similarity("山东苹果丰收", "世界锦标赛胜出"))
print(docVectorModel.similarity(documents[0], documents[1]))
print(docVectorModel.similarity(documents[0], documents[4]))
结果如下:
0.6743720769882202
0.018603254109621048
0.6743720769882202
-0.11777809262275696
类似的,可以通过调用 nearest 接口查询与给定单词最相似的文档
def print_nearest_document(document, documents, model):
print_header(document)
for entry in model.nearest(document):
print("%50s\t\t%f" % (documents[entry.getKey()], entry.getValue()))
def print_header(query):
print(
"\n%50s Cosine\n------------------------------------------------------------------------" % (query))
for i, d in enumerate(documents):
docVectorModel.addDocument(i, documents[i])
print_nearest_document("体育", documents, docVectorModel)
print_nearest_document("农业", documents, docVectorModel)
print_nearest_document("我要看比赛", documents, docVectorModel)
print_nearest_document("要不做饭吧", documents, docVectorModel)
结果如下:
体育 Cosine
------------------------------------------------------------------------
世界锦标赛胜出 0.256444
奥运会女排夺冠 0.206812
中国足球失败 0.165934
山东苹果丰收 -0.037693
农民在江苏种水稻 -0.047260
农业 Cosine
------------------------------------------------------------------------
农民在江苏种水稻 0.393115
山东苹果丰收 0.259620
中国足球失败 -0.008700
世界锦标赛胜出 -0.063113
奥运会女排夺冠 -0.137968
我要看比赛 Cosine
------------------------------------------------------------------------
奥运会女排夺冠 0.531833
世界锦标赛胜出 0.357246
中国足球失败 0.268507
山东苹果丰收 0.000207
农民在江苏种水稻 -0.022467
要不做饭吧 Cosine
------------------------------------------------------------------------
农民在江苏种水稻 0.232754
山东苹果丰收 0.199197
奥运会女排夺冠 -0.166378
世界锦标赛胜出 -0.179484
中国足球失败 -0.229308
13.4 基于神经网络的高性能依存句法分析器
1.Arc-Standard转移系统
不同之前介绍的 Arc-Eager,该依存句法器基于 Arc-Standard 转移系统,具体动作如下:
两个转移系统的逻辑不同,Arc-Eager 自顶而下地构建,而 Arc-Standard 要求右子树自底而上地构建。虽然两者的复杂度都是 O(n),然而可能由于 Arc-Standard 的简洁性(转移动作更少),它更受欢迎。
2.特征提取
虽然神经网络理论上可以自动提取特征,然而这篇论文作为开山之作,依然未能脱离特征模板。所有的特征分为三大类,即:
-
单词特征。 -
词性特征。 -
已经确定的子树中的依存标签特征。
接着,句法分析器对当前的状态提取上述三大类特征,分别记作 w、t 和 l。不同于传统方法,此处为每个特征分配一个向量,于是得到三个稠密向量 Xw、Xt 和 Xl。接着,将这三个向量拼接起来输人到含有一个隐藏层的神经网络,并且使用立方函数激活,亦即得到隐藏层的特征向量:
接着,对于 k 种标签而言,Arc-Standard 一共存在 2k +1 种可能的转移动作。此时只需将特征向量 h 输人到多元逻辑斯谛回归分类器(可以看作神经网络中的输出层)中即可得到转移动作的概率分布:
最后选取 p 中最大概率所对应的转移动作并执行即可。训练时,采用 softmax 交叉熵损失函数并且以随机梯度下降法优化。
3.实现代码
from pyhanlp import *
CoNLLSentence = JClass('com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLSentence')
CoNLLWord = JClass('com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLWord')
IDependencyParser = JClass('com.hankcs.hanlp.dependency.IDependencyParser')
NeuralNetworkDependencyParser = JClass('com.hankcs.hanlp.dependency.nnparser.NeuralNetworkDependencyParser')
parser = NeuralNetworkDependencyParser()
sentence = parser.parse("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。")
print(sentence)
for word in sentence.iterator(): # 通过dir()可以查看sentence的方法
print("%s --(%s)--> %s" % (word.LEMMA, word.DEPREL, word.HEAD.LEMMA))
print()
# 也可以直接拿到数组,任意顺序或逆序遍历
word_array = sentence.getWordArray()
for word in word_array:
print("%s --(%s)--> %s" % (word.LEMMA, word.DEPREL, word.HEAD.LEMMA))
print()
# 还可以直接遍历子树,从某棵子树的某个节点一路遍历到虚根
CoNLLWord = JClass("com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLWord")
head = word_array[12]
while head.HEAD:
head = head.HEAD
if (head == CoNLLWord.ROOT):
print(head.LEMMA)
else:
print("%s --(%s)--> " % (head.LEMMA, head.DEPREL))
依存关系详细见 Chinese Dependency Treebank 1.0 的定义。
13.5 结语
1.自然语言处理是一门日新月异的学科,在深度学习的时代更是如此。在学术界,即便是当前最先进的研究,在仅仅两个月后很快就会被突破。本系列文章所提供的知识只不过是那些入门级的基础知识而已。
2.神经网络中两个常用的特征提取器: 用于时序数据的递归神经网络 RNN 以及用于空间数据的卷积神经网络 CNN。其中,RNN 在自然语言处理领域应用得最为广泛。RNN 可以处理变长的输入,这正好适用于文本。特别是 RNN 家族中的 LSTM 网络,可以记忆大约 200 左右的单词,为建模句子中单词之间的长距离依存创造了条件。然而,RNN 的缺陷在于难以并行化。如果需要捕捉文本中的 n 元语法的话,CNN 反而更胜一筹,并且在并行化方面具备天然优势。考虑到文档一般较长, 许多文档分类模型都使用 CNN 来构建。而句子相对较短,所以在句子颗粒度上进行的基础 NLP 任务(中文分词、词性标注、命名实体识别和句法分析等)经常采用 RNN 来实现。
-
RNN 原理详见:
http://mantchs.com/2019/08/15/DL/RNN/
-
CNN 原理详见:
http://mantchs.com/2019/08/11/DL/CNN/
-
LSTM 原理详见:
http://mantchs.com/2019/08/17/DL/LSTM/
3.在词嵌入的预训练方面,word2vec 早已是明日黄花。Facebook 通过将词语内部的构词信息引人 Skip-Gram 模型,得到的 fastText 可以为任意词语构造词向量,而不要求该词语一定得出现在语料库中。但是,无论是 word2vec 还是 fastText,都无法解决一词多义的问题。因为多义词的消歧必须根据给定句子的上下文才能进行,这催生了一系列能够感知上下文的词语表示方法。
其中,华盛顿大学提出了 ELMO,即一个在大规模纯文本上训练的双向 LSTM 语言模型。ELMo 通过读人上文来预测当前单词的方式为词嵌人引入了上下文信息。Zalando Research 的研究人员则将这一方法应用到了字符级别,得到了上下文字符串嵌入,其标注器取得了目前最先进的准确率。而 Google 的 BERT 模型则通过一种高效的双向Transformer网络同时对上文和下文建模,在许多NLP任务上取得了惊人的成绩。
-
fastText 原理详见:
http://mantchs.com/2019/08/23/NLP/fastText/
-
ELMO 原理详见:
http://mantchs.com/2019/09/28/NLP/BERT/
-
BERT 原理详见:
http://mantchs.com/2019/09/28/NLP/BERT/
4.另一些以前认为很难的 NLP 任务,比如自动问答和文档摘要等,在深度学习时代反而显得非常简单。许多 QA 任务归结为衡量问题和备选答案之间的文本相似度,这恰好是具备注意力机制的神经网络所擅长的。而文档摘要涉及的文本生成技术,又恰好是 RNN 语言模型所擅长的。在机器翻译领域,Google 早已利用基于神经网络的机器翻译技术淘汰了基于短语的机器翻译技术。目前,学术界的流行趋势是利用 Transformer 和注意力机制提取特征。
-
Transformer 原理详见:
http://mantchs.com/2019/09/26/NLP/Transformer/
-
注意力机制 原理详见:
http://mantchs.com/2019/08/31/NLP/Attention/
总之,自然语言处理的未来图景宏伟而广阔。自然语言处理入门系列文章就作为这条漫漫长路上的一块垫脚石,希望给予读者一些必备的入门概念。至于接下来的修行,前路漫漫,与君共勉。
系列文章
-
-
-
-
-
-
-
-
-
-
-
-
-
深度学习与自然语言处理
以上是关于C#使用词嵌入向量与向量数据库为大语言模型(LLM)赋能长期记忆实现私域问答机器人落地的主要内容,如果未能解决你的问题,请参考以下文章