Python3爬虫网易云音乐歌单下载
Posted TM0831
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3爬虫网易云音乐歌单下载相关的知识,希望对你有一定的参考价值。
一、目标:
下载网易云音乐热门歌单
二、用到的模块:
requests,multiprocessing,re。
三、步骤:
(1)页面分析:首先打开网易云音乐,选择热门歌单,可以看到以下歌单列表,然后打开开发者工具
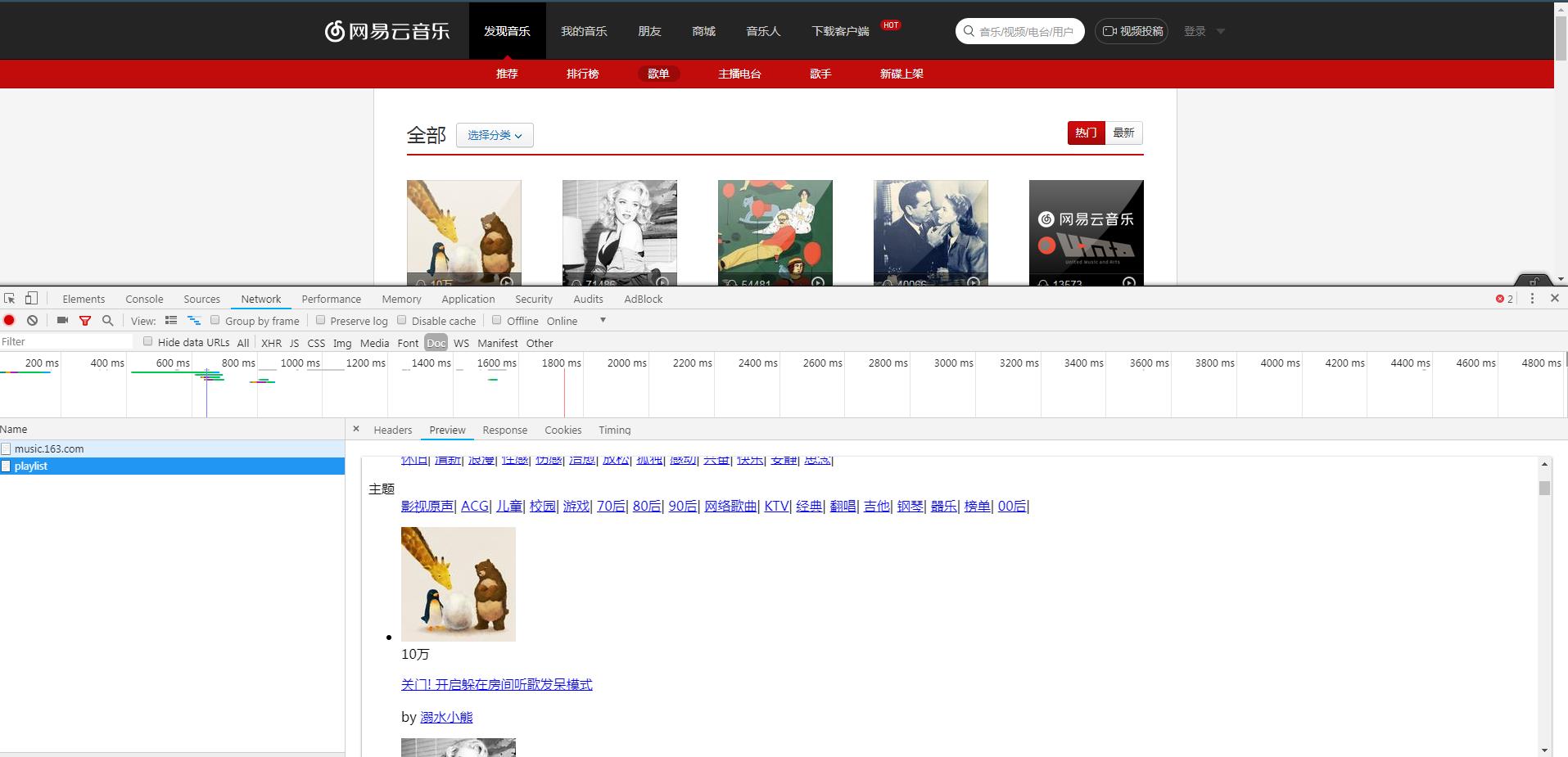

因此我们需要请求的url就是https://music.163.com/discover/playlist,然后用requests.get()方法请求页面,对于返回的结果,用正则表达式进行解析,得到歌单名字和歌单id,解析的正则表达式如下:
res = requests.get(url, headers=headers)
data = re.findall(\'<a title="(.*?)" href="/playlist\\?id=(\\d+)" class="msk"></a>\', res.text)
(2)得到歌单名字和歌单id后,构造歌单的url,然后模仿步骤(1)可以得到歌曲名字和歌曲id,解析的正则表达式如下:
re.findall(r\'<a href="/song\\?id=(\\d+)">(.*?)</a>\', res.text)
再得到歌曲id后,构造歌曲的url,然后用requests.get().content方法下载歌曲,歌曲的url构造方法如下:
"http://music.163.com/song/media/outer/url?id=%s" %(歌曲id)
(3)由于部分歌曲的名字并不能作为文件名保存下来,所以用到了try...except,对于不能保存为文件名的歌曲,我选择pass掉==
(4)因为要下载多个歌单,一个歌单里又有很多歌曲,所以用到了multiprocessing模块的Pool方法,提高程序运行的效率。
四、具体代码
因为下载所有歌单会需要很长时间,所以我们先下载前三个歌单试试==
1 import requests 2 import re 3 from multiprocessing import Pool 4 5 headers = { 6 \'Referer\': \'https://music.163.com/\', 7 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 " 8 "Safari/537.36" 9 } 10 11 12 def get_page(url): 13 res = requests.get(url, headers=headers) 14 data = re.findall(\'<a title="(.*?)" href="/playlist\\?id=(\\d+)" class="msk"></a>\', res.text) 15 16 pool = Pool(processes=4) 17 pool.map(get_songs, data[:3]) 18 print("下载完毕!") 19 20 21 def get_songs(data): 22 playlist_url = "https://music.163.com/playlist?id=%s" % data[1] 23 res = requests.get(playlist_url, headers=headers) 24 for i in re.findall(r\'<a href="/song\\?id=(\\d+)">(.*?)</a>\', res.text): 25 download_url = "http://music.163.com/song/media/outer/url?id=%s" % i[0] 26 try: 27 with open(\'music/\' + i[1]+\'.mp3\', \'wb\') as f: 28 f.write(requests.get(download_url, headers=headers).content) 29 except FileNotFoundError: 30 pass 31 except OSError: 32 pass 33 34 35 if __name__ == \'__main__\': 36 hot_url = "https://music.163.com/discover/playlist/?order=hot" 37 get_page(hot_url)
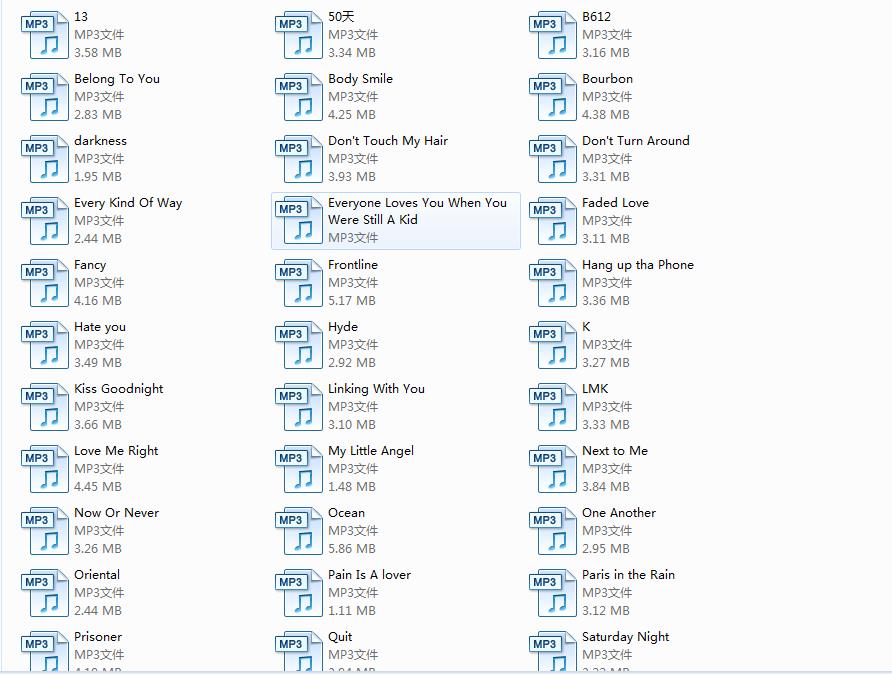
五、运行结果
以上是关于Python3爬虫网易云音乐歌单下载的主要内容,如果未能解决你的问题,请参考以下文章