手把手教你利用Python自动下载CL社区图片
Posted zhongfengshan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你利用Python自动下载CL社区图片相关的知识,希望对你有一定的参考价值。
需求描述:
最近发现CL社区上好多精华的帖子分享的图片非常棒,好想好想保存下来,但是一张一张地保存太费时间了,因此,造物者思想主义的我就想动手写个工具,实现只要输入帖子的链接,就能把所有的精华图片下载下来。
程序分析思路:
Python是一个很好的工具,使用起来非常方便。因此我决定用Python去实现。
思路大概就是,我先输入链接,然后每一张图片的链接,然后去下载它。需求很明确,逻辑应该很清晰,开始干吧。
环境说明:本人使用的是win7+Python3
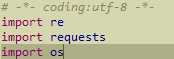
首先导入re、requests、os三个包,用于爬虫,os包用于目录的创建
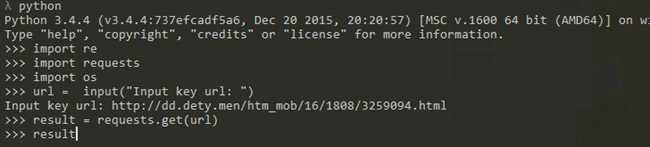
输入你要保存图片的的链接url = input("Input key url: ")
这里以http://dd.dety.men/htm_mob/16/1808/32xxxxx.html为例,在浏览器打开是这样的,由于不可描述,我只能放这么一点东西
这里用获得网页的内容result = requests.get(url)

result.text是获取到的网页源码,为了避免有编码问题的困扰,我们现在前面做一下转码

然后我们需要在源码中找到标题,一会用作保存文件的文件名,标题的寻找的实现代码是,这样返回的是一个list,我们用的时候直接取第0个就好(程序猿数数都是从零开始的)。
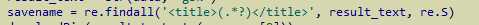
这里要说一下这个寻找标题的实现代码的正则表达式,我们看到网页链接中的源码是

实现代码的正则表达式就是要找<title>和</title>中间的那一部分,找到的标题如下

下面来干正事了,从网页中找图片的链接,首先先看浏览器上,按F12打开开发者模式,点击一下"从页面中选中一个元素",选中图片,看到图片的源码
<input data-src="http://www.79img.com/u/20180829/13435782.jpg"
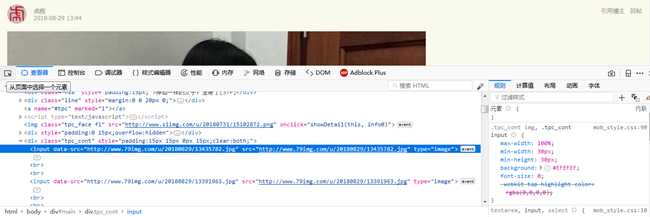
但是我们需要在Python中看看re获取到的源码是什么样的,

获取到的图片链接是这样的data-src=‘http://www.79img.com/u/20180829/13392462.jpg‘,因此我们用下面这个代码来找到所有的图片链接
pic_url = re.findall(‘data-src=‘(.*?)‘‘, result_text, re.S)

找到链接之后就是下载了,这是下载的方法,keyword是刚才找到的标题名
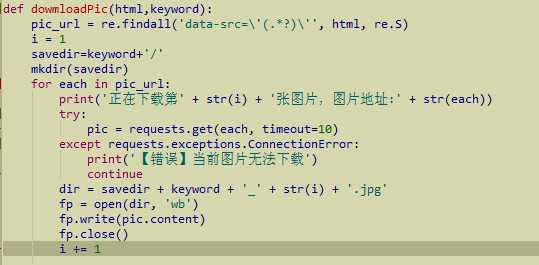
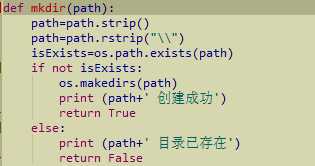
加入了创建目录的操作
源码和如何使用:
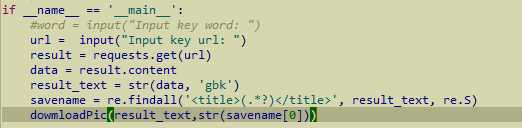
最终的源码如下图所示:
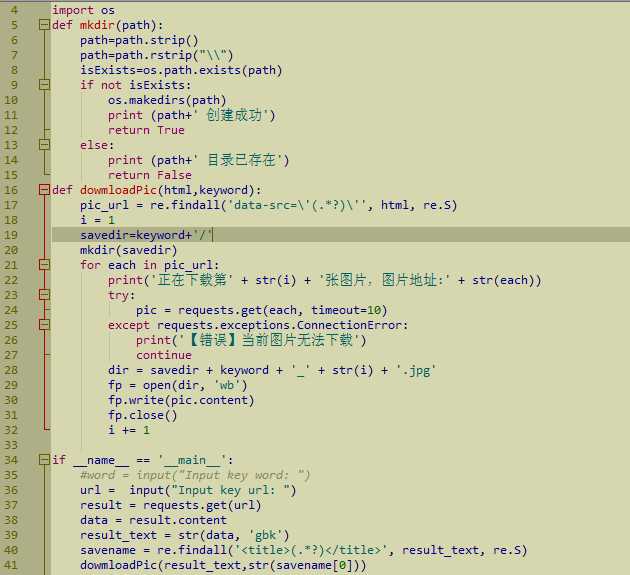
源码已经上传至github,欢迎下载,欢迎各种star,fork
https://github.com/rootzhongfengshan/python_practical/tree/master/DownPictureFromCL
按如图使用
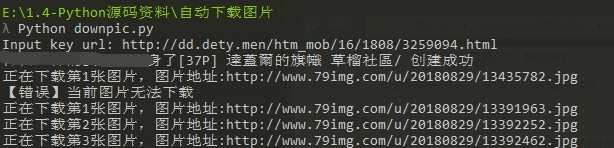
就可以看到在当前目录产生了一个目录,给你们看看最后的成果图吧,很黄很暴力。

以上是关于手把手教你利用Python自动下载CL社区图片的主要内容,如果未能解决你的问题,请参考以下文章