记一次爬取组装音乐的过程(使用 requests, eyed3)
Posted violeshnv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次爬取组装音乐的过程(使用 requests, eyed3)相关的知识,希望对你有一定的参考价值。
好久没写爬虫,试着将音乐通过直链爬下来,然后在本地组装成完整的音乐。
也可以作为主要用到的三个库 requests、pandas、eyed3 的一次实践。
本文的 headers 将会被省略
import time
import requests
import os
import eyed3
import pandas as pd
from collections import defaultdict
from bs4 import BeautifulSoup
def process_headers(raw: str) -> dict:
"""
将从 F12 里复制的头信息转为字典形式
"""
headers = raw.strip().split(\'\\n\')
result =
for row in headers:
row = row.strip()
if not row:
continue
for method in [\'GET\', \'POST\']:
if row.startswith(method):
break
else:
sep = row.index(\':\')
result[row[:sep]] = row[sep+2:]
return result
爬取信息
import requests
import time
import pandas as pd
from collections import defaultdict
推荐使用这个直链搜索工具来减小工作量,音乐直链搜索|音乐在线试听 - by 刘志进实验室。直链下载下来只有 128kbps,不过已经够用了。
打开 F12,可以看到这个搜索是使用 POST 来传递的
- 请求载荷为表单形式,参数分别为
input, filter, type, page。 - 响应为 JSON 格式,非常完好的返回了各种歌曲的相关参数,包括链接、标题、作者、歌词、图片。
如果没有这个工具,那么我们还需要先爬取歌曲详情,再在歌曲详情页爬取这些信息,在这里也感谢这个工具的制作人。

建议在网站里发送一遍请求后,直接打开 F12 复制表单,在之后的请求中只需要修改 page 来获得对应信息。
url = \'https://music.liuzhijin.cn/\'
data = \'input=%E5%8F%91%E7%83%AD%E5%B7%AB%E5%A5%B3&\' \\
\'filter=name&\' \\
\'type=netease&\' \\
\'page=\'
headers = process_headers(
\'\'\'
Host: music.liuzhijin.cn
...
\'\'\'
)
def fetch_info():
result = []
for i in range(1, 44 + 1): # 提取查看一共需要多少页
res = requests.post(url, data=data + str(i), headers=headers)
if res.status_code == 200:
info = json.loads(res.text)
print(f\'success i\')
result.append(info)
else:
print(f\'fail i\')
time.sleep(3) # 休息,减少服务器压力
return result
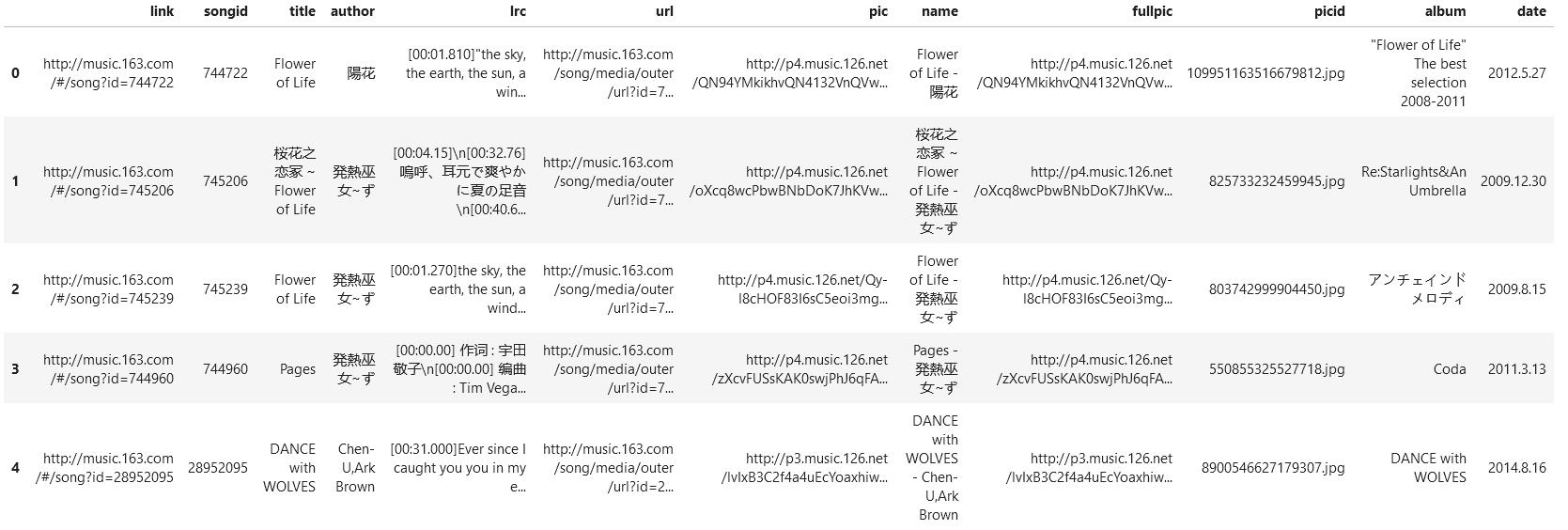
然后将信息用 Pandas 的 DateFrame 表示,并做一些预处理和保存
- 名字:要将标题和作者都显示在文件里面,删去 Windows 命名不能使用的符号;同时还要做防重名处理,将重名的文件名后面加上数字。
- 封面:因为提取出的信息里,封面图片是缩小后的形式,我们将图片的
url的param参数去掉,来获取完整的图片(如果不需要完整封面的也可以不做);同时文件的id也要截取下来,为后续进一步爬取做铺垫。
info = fetch_info()
info = sum((info[\'data\'] for info in result),
start=[])
info = pd.DataFrame(info)
info = info.drop(\'type\', axis=1)
# 命名处理
info[\'name\'] = info.apply(
lambda row: f\'row.title - row.author\',
axis=1
)
repeat_counts = defaultdict(int)
for i, a in info.iterrows():
name = a[\'name\']
# Windows 命名不能使用的符号
for c in \'\\\\/:*?"<>|\':
name = name.replace(c, \' \')
# Windows 不区分大小写,用 lower() 来防止重名
repeat_counts[name.lower()] += 1
if (rc := repeat_counts[name.lower()]) != 1:
info.loc[i, \'name\'] = info.loc[i, \'name\'] + f\' - rc\'
# 封面处理
info[\'fullpic\'] = info[\'pic\'].map(lambda p: p[:p.index(\'?\')])
info[\'picid\'] = info[\'fullpic\'].map(lambda p: p[p.rindex(\'/\')+1:])
# 保存 显示
info.to_csv(\'info.csv\', index=False)
info.head()

进一步爬取
这里只是爬取的文件的基本信息,为了进一步完善音乐信息,现在我们需要爬取网易云音乐的专辑页面
进入专辑页,可以看到一个页面只能显示 12 个专辑,但点到第二页之后可以看到 url 出现了 limit 和 offset 两个参数,从名字上就可以判断这两个参数的作用。修改 limit 为 80 并删去 offset 使所有专辑都显示在一个页面上,F12 查看响应。
在响应的原始模式中搜索我们需要的封面信息、专辑名、专辑发布时间三个信息,可以看到它们在 li 表示的列表中,上一级为 <ul class="m-cvrlst m-cvrlst-alb4 f-cb" id="m-song-module" data-id="19783"> 表示的无序列表中,我们使用 BeatifulSoup 进行提取。

from bs4 import BeautifulSoup
url = \'https://music.163.com/artist/album?id=19783&limit=80\'
headers = process_headers(
\'\'\'
Host: music.163.com
...
\'\'\'
)
def get_artist_albums():
res = requests.get(url=url, headers=headers)
if res.status_code == 200:
print(\'OK\')
return res
def parse_html(html):
def image_name(url):
b, e = url.rindex(\'/\'), url.index(\'?\')
return url[b+1:e]
soup = BeautifulSoup(html, "lxml")
album_infos = soup.find_all(\'ul\', id=\'m-song-module\')[0].find_all(\'li\')
img_album_date_dict =
image_name(a.find(\'img\')[\'src\']):
(
a.find(\'p\', class_=\'dec dec-1 f-thide2 f-pre\')[\'title\'],
a.find(\'span\', class_=\'s-fc3\').text
)
for a in album_infos
return img_album_date_dict
将爬取的信息添加到 info 中,这时候之前处理的 picid 就有用到了,它可以将图片和专辑、日期联系起来
html = get_artist_albums()
img_album_date_dict = parse_html(html.text)
album_date_df = pd.DataFrame(info[\'picid\'].map(
lambda p: img_album_date_dict.get(p, \'album\': None, \'date\': None)
).to_list())
info = pd.concat((info, album_date_df), axis=1, sort=False)
info.to_csv(\'info_plus.csv\', index=False)
info.head()
爬取图片、音频
现在图片在 fullpic 中,音频在 url 中,首先用浏览器打开一遍,复制 headers,并且查看其他情况。
发现图片可以直接获取,而音频则会被转发到不同的 CDN 服务器进行分流。而下载下来的音频几乎没有额外信息,这也是为什么我们需要爬取这些信息并且组装。

最关键的是,分流前后使用的 headers 是不同的,因此不能让 requests.get 进行重定向,而是手动提取 302 响应头的 Location 修改请求头后进行重定向。
headers = process_headers(
\'\'\'
Host: p3.music.126.net
...
\'\'\'
)
def fetch_images():
if not os.path.isdir(\'image/\'):
os.mkdir(\'image\')
pic_set =
for i, a in result.iterrows():
pic_url = a[\'fullpic\']
picid = a[\'picid\']
name = a[\'name\']
if picid in pic_set:
print(f\'OK i name\')
continue
res = requests.get(url=pic_url, headers=headers)
if res.status_code == 200:
print(f\'OK i name\')
with open(os.path.join(\'image\', picid), \'wb\') as p:
p.write(res.content)
else:
print(f\'fail i name\')
time.sleep(1)
headers = process_headers(
\'\'\'
Host: music.163.com
...
\'\'\'
)
next_headers_list = [
process_headers(
\'\'\'
Host: m10.music.126.net
...
\'\'\'),
process_headers(
\'\'\'
Host: m701.music.126.net
...
\'\'\'
)
]
next_headers = next_headers_list[0]
def fetch_mp3s(indexes=None, interval=None):
if not os.path.isdir(\'music/\'):
os.mkdir(\'music\')
# 爬取失败的索引
failed_indexes = []
for i, a in result.iterrows():
if indexes is not None and i not in indexes:
continue
failed = False
url = a[\'url\']
name = a[\'name\']
path = os.path.join(\'music\', name) + \'.mp3\'
# 禁止自动重定向
res = requests.get(url=url, headers=headers, allow_redirects=False)
if res.status_code == 200:
print(f\'OK i name\')
with open(path, \'wb\') as p:
p.write(res.content)
elif res.status_code == 302:
url = res.headers[\'Location\']
res = requests.get(url=url, headers=next_headers)
if res.status_code == 200:
print(f\'OK i name\')
with open(path, \'wb\') as p:
p.write(res.content)
else:
failed = True
else:
failed = True
if failed:
print(f\'FAIL i res.status_code\')
failed_indexes.append(i)
if interval:
time.sleep(interval)
return failed_indexes
failed_indexes = fetch_mp3s()
之所以准备多个请求头,是因为分流的 CDN 需要的请求头是不一样的,在这里只需要用到两个请求头就可以获取全部的音频了。然后将失败的 url 更换请求头再次请求。
next_headers = next_headers_list[1]
while failed_indexes:
failed_indexes = fetch_mp3s(failed_indexes)
print(\'-----------\')
print(failed_indexes)
print(\'-----------\')
至此,所有需要网络连接的工作已经完成,接下来是使用 eyeD3 库进行将音频、封面以及其他信息进行组装。
组装
万事俱备,我们遍历表格,通过 picid 寻找图片,通过 name 寻找音频,再组装其他信息。
import eyed3
def attach_tag(audio, artist, album, title, album_artist, date, lyrics, image):
if not audio.tag:
audio.initTag()
audio.tag.artist = artist or \'\'
audio.tag.album = album or \'\'
audio.tag.title = title or \'\'
audio.tag.album_artist = album_artist or \'\'
if date and isinstance(date, str):
audio.tag.release_date = eyed3.core.Date(*map(int, date.split(\'.\')))
if lyrics and isinstance(lyrics, str):
audio.tag.lyrics.set(lyrics, \'lyrics\', b\'jp\')
if image:
audio.tag.images.set(eyed3.id3.frames.ImageFrame.FRONT_COVER,
image, \'image/jpeg\')
# 编码
audio.tag.save(encoding=\'utf-8\')
info = pd.read_csv(\'info_plus.csv\')
for i, a in info.iterrows():
name = a[\'name\']
audio = eyed3.load(os.path.join(\'music\', name) + \'.mp3\')
with open(os.path.join(\'image\', a[\'picid\']), \'rb\') as p:
attach_tag(
audio=audio,
artist=a[\'author\'],
album=a[\'album\'],
title=a[\'title\'],
album_artist=\'発热巫女~ず\',
date=a[\'date\'],
lyrics=a[\'lrc\'],
image=p.read()
)
print(i, a[\'name\'])
Tag 的每一项数据都是以 Frame 类表示的,一般关注它的几个属性 id, description, lang, text,再通过 FrameAccessor 接口类的方法 get, set 方法来修改这几个属性。
对于一般的文字性的 Tag,比如 artist, album, title,使用的是 str 直接存储,然后写入 TextFrame 中,这个 TextFrame 包含了大部分地文字性描述。调用 save() 的时候才会写入 TextFrame。
对于日期 DateFrame,需要使用类 eyed3.core.Date,其初始化为 __init__(year=None, month=None, day=None, ...) 一直到秒,已经通过 @property 修饰过了,直接赋值其实就已经调用了 set 方法。
对于歌词 LyricsFrame,显式地通过 set 方法进行配置,set(text, description, lang) 对应歌词、描述、语言,虽然我选的歌不少是英文,不过还是使用了 b\'jp\' 作为语言,描述则可以随意配置。
对于图片 ImageFrame,显式地通过 set 方法进行配置,set(type, img_data, mime_type, description, img_url) 对应图片类型、图片数据、图片格式、描述、URL,后两项省略不填。类型指的是下列的一长串,因为是封面所以选 FRONT_COVER;格式就用 image/jpeg。

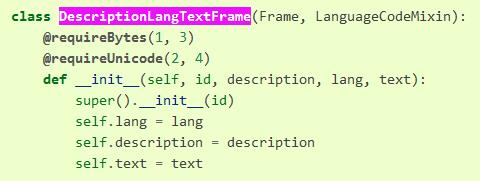
还需要注意参数的类型,通过 @requireBytes, @requireUnicode 修饰的方法对参数类型有要求,比如下面这个 __init__ 函数就需要 1,3 位置的参数 id, lang 为 Bytes;2,4 位置的参数 description, text 为 Unicode,其实就是 str,所以有 Unicode 描述的参数还需要注意编码。
结果
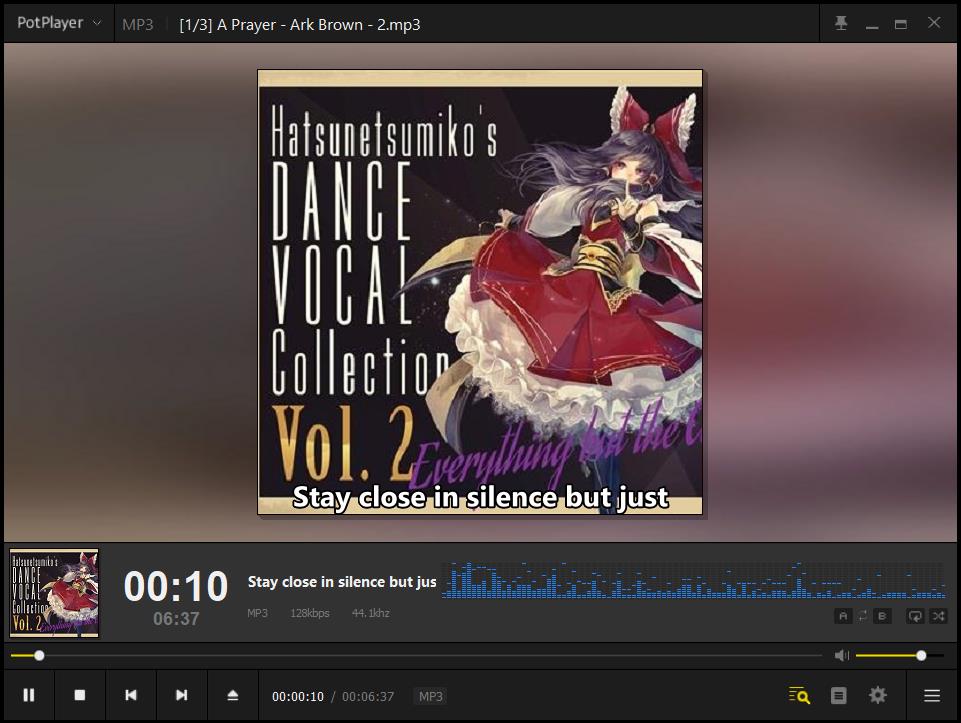

封面、歌词、专辑、作者、日期显示正常。
错误
eyeD3 编码错误

在完善 Tag 的过程中,发生 latin-1 编码错误,这是因为有些歌曲的 Tag 已经默认使用了 latin-1 编码。查看源码可知 eyeD3 使用的编码,我们需要的是 UTF-8 编码。

解决方法有三种,eyeD3 使用不同的 Frame 表示标签 Tag 的组成,比如图片就是 ImageFrame、歌词就是 LyricsFrame,这里出现错误的是 TextFrame。不论方法是什么,都需要改变这个 Frame 的编码。按正常的途径 Frame 上面设有一个 FrameAccessor 接口类来控制 Frame 数据的修改,但是通过这个接口无法修改编码。所以有四种解决方法:
-
Python 没有严格的访问限制,可以直接修改对应
TextFrame的encoding属性,但是这个对应的TextFrame比较难找; -
eyeD3 相比其他库,比较方便的地方就是它是由 Python 编写的,因此我们可以轻松的通过报错找到错误发生的位置,并且加入输出和修复。
上面的错误已经提供了错误发生的位置
eyed3\\id3\\frames.py:314, in TextFrame.render(self),直接找到这个文件修改为def render(self): self._initEncoding() try: self.data = (self.encoding + self.text.encode(id3EncodingToString(self.encoding))) except UnicodeEncodeError as e: print(e) print(self.text) self.data = (self.encoding + self.text.encode(id3EncodingToString(UTF_8_ENCODING))) assert type(self.data) is bytes return super().render() -
第三个是最简便的方法
错误发生的原因其实是音频文件已经有了自己的
TextFrame,而且编码已经设置好了。干脆直接把 Tag 清除重新写入就可以了,因为本来就没有多少信息,而且我们自己要写入的信息其实是很充足的。将写入 Tag 的代码前清除 Tag,改为
def attach_tag(song, artist, album, title, date, lyrics, image): audio.initTag() song.tag.artist = artist or \'\' ... audio.tag.save() -
第四个也是最简便的方法,就是文章里面写的,保存的时候提供编码即可
audio.tag.save(encoding=\'utf-8\')
requests 重定向错误
这就是前面说的因为分流前后请求头不同而发生的,默认情况下 requests.get() 的 allow_redirects=True,使用重定向之后请求头却没有修改,容易引起服务器拒绝请求,即 403 错误。
通关 Wireshark 抓包,也可以发现(11~22 为 requests.get,81~3764 为浏览器,图中没有显示具体的请求头并且隐去了 Source 和 Destination),不同的请求方式都接受了 302 Found,但重定向后分别引起了 502 Bad Gateway 和 200 OK。

记一次不太成功的爬取dingtalk上的企业的信息
首先打开这个链接https://www.dingtalk.com/qiye/1.html,可以网页列出了很多企业,点击企业,就看到了企业的信息。
所以,我们的思路就很明确了,通过https://www.dingtalk.com/qiye/1.html这个入口链接获取企业的URL,然后通过访问企业的URL获取企业的信息。在jupyter notebook中试一下。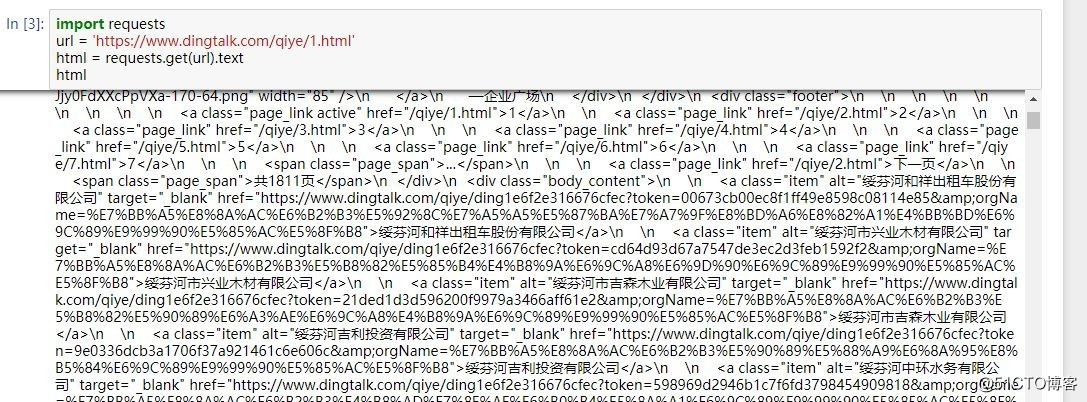
企业的URL已经获取到了,然后再访问企业的URL,看看能否获取到企业的信息。
没有。
写请求头,请求头包含两项,一个是cookie,一个user-agent。加上请求头再试试看,有了。
发现企业信息在js代码里,写正则表达式
patterns = r‘"businessInfoData":{"enterpriseName":"(.*?)","frName":"(.*?)","enterpriseType":"(.*?)","enterpriseStatus":"(.*?)","regCap":"(.*?)","regCapCur":"(.*?)","esDate":"(.*?)","regOrg":"(.*?)","operateScope":"(.*?)","address":"(.*?)","regNo":"(.*?)","creditCode":"(.*?)","region":"(.*?)"}‘
results = re.findall(patterns, html)ok,成功匹配出来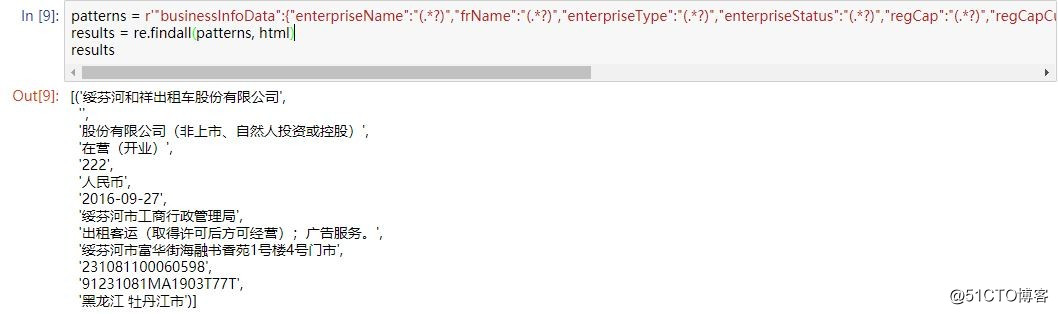
到此,发现很简单了,立马就把代码给写了出来,但发现一些问题,只有一部分企业的信息爬取了出来,大部分企业信息都获取失败了。这是咋回事呢,原来啊,有的企业URL源码里有企业信息,而有的没有。

然后,我查看完整企业信息,发现这个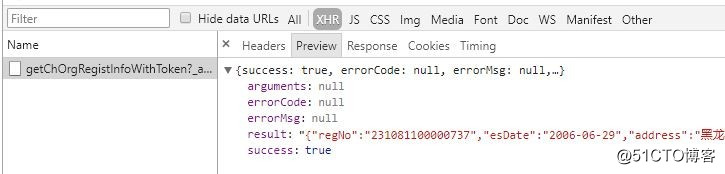
但是,我无法构造这个链接,忧伤。
所以,整个爬虫到此为止。写代码的时候,原本想用入口链接不断下一页获取所有企业URL,但一想,算了吧,直接简单粗暴一点。然后呢,爬取的时候,爬取速度好慢。
最后,附上垃圾的源码github。
以上是关于记一次爬取组装音乐的过程(使用 requests, eyed3)的主要内容,如果未能解决你的问题,请参考以下文章