泰坦尼克号生存预测(python)
Posted islvgb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了泰坦尼克号生存预测(python)相关的知识,希望对你有一定的参考价值。
1 数据探索
对数据进行一个整体的理解
1.1 查看数据都有一些什么特征
import pandas as pd import seaborn as sns %matplotlib inline titanic = pd.read_csv(‘G:\\titanic\\train.csv‘)
titanic.sample(10)
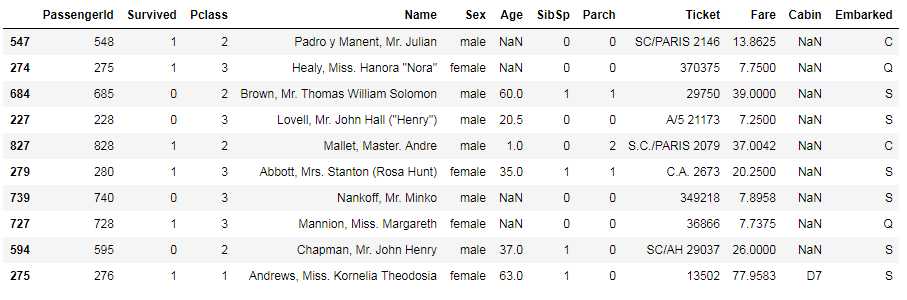
获取数据的10行记录进行观察,初步了解数据的组成,可以看到Age、Cabin里面是存在缺失值的,在进一步理解数据的统计量后再进行数据处理,观察各特征的最大最小值等,可以发现这些数据比较合理,不存在特别的异常值。
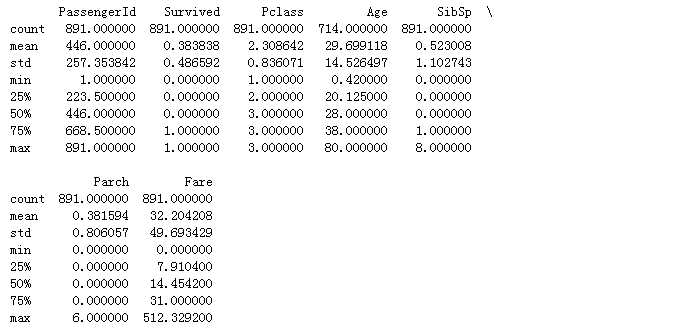
print(titanic.describe())
#查看常用的统计量
2 数据分析处理
Name和Ticket依据基本认知来看,与乘客是否有机会存活相关不大,因此暂时不理会这两个特征。由于Cabin这一个特征缺失值比较多,参考价值低,因此同样暂时搁置。
2.1 Sex特征处理
Sex分为female和male,但是一些算法模型只能识别数字,所以将他们分别用0和1表示
titanic.Sex = titanic.Sex.replace("male",1) titanic.Sex = titanic.Sex.replace("female",0)
2.2 Age特征处理
Age这里存在缺失值,有年纪记录的有714行,这里使用age的平均数来进行填充缺失值
titanic.Age = titanic["Age"].fillna(titanic.Age.mean())
2.3 Embarked特征处理
将Embarked的S C Q分别替换为0 1 2
titanic.Embarked = titanic.Embarked.replace("S",0) titanic.Embarked = titanic.Embarked.replace("C",1) titanic.Embarked = titanic.Embarked.replace("Q",2)
查看Embarked特征统计量发现,他存在缺失值,这里用众数进行替换缺失值
titanic.Embarked = titanic["Embarked"].fillna(0)
3 特征工程
通过热力图观察各特征与Survived之间的相关性
info = ["Survived","PassengerId","Pclass","Sex","Age","SibSp","Parch","Fare","Embarked"] sns.heatmap(titanic[info].corr(),annot =True,vmin = 0, vmax = 1)
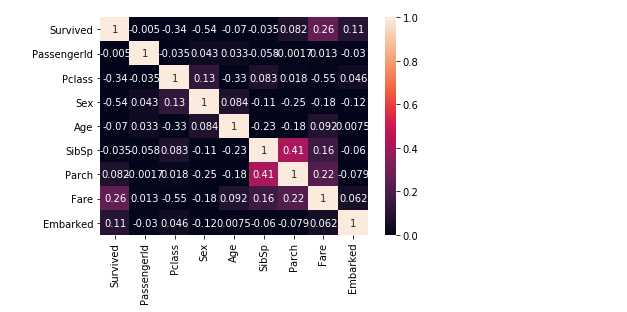
根据热力图可以看出Pclass、Sex、Fare、Embarked与Survived相关性比较强,所以将这些特征代入机器学习模型中进行学习
4 模型学习/评估
import numpy as np from sklearn import linear_model from sklearn.model_selection import cross_val_score
x = titanic[["Pclass","Sex","Age","Fare","Embarked"]]
y = titanic["Survived"]
这里采用交叉检验的方法,最后取平均值来对模型进行评估
4.1 逻辑回归
lm = linear_model.LogisticRegression() scores = cross_val_score(lm,x,y,cv = 5,scoring = "accuracy") print(np.mean(scores))
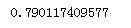
4.2 k近邻
from sklearn import neighbors knn = neighbors.KNeighborsClassifier(10,weights = "uniform") scores = cross_val_score(knn,x,y,cv = 5,scoring = "accuracy") print(np.mean(score)
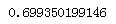
4.3 决策树
from sklearn import tree dt = tree.DecisionTreeClassifier() scores = cross_val_score(dt,x,y,cv = 5,scoring = "accuracy") print(np.mean(scores))
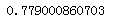
4.4 随机森林
from sklearn import ensemble rf = ensemble.RandomForestClassifier(50) scores = cross_val_score(rf,x,y,cv = 5,scoring = "accuracy") print(np.mean(scores))
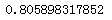
4.5 GBDT
gbdt = ensemble.GradientBoostingClassifier() scores = cross_val_score(gbdt,x,y,cv = 5,scoring = "accuracy") print(np.mean(scores))
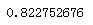
5 总结
经过数据探索、数据处理、常用机器学习模型比较,最后可以发现GBDT在泰坦尼克号生存预测上面表现最好,准确率能达到82%以上。
以上是关于泰坦尼克号生存预测(python)的主要内容,如果未能解决你的问题,请参考以下文章