milvus 又一个开源的向量数据库
Posted rongfengliang-荣锋亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了milvus 又一个开源的向量数据库相关的知识,希望对你有一定的参考价值。
以前简单介绍过一个基于rust 的qdrant 向量数据库,milvus 也是一个类似的
milvus 一些特性
- 快速
- 支持非结构化数据
- 可靠
- 高可用&弹性
- 混合搜索
- 通用lambda 架构,支持批以及stream 处理
参考架构
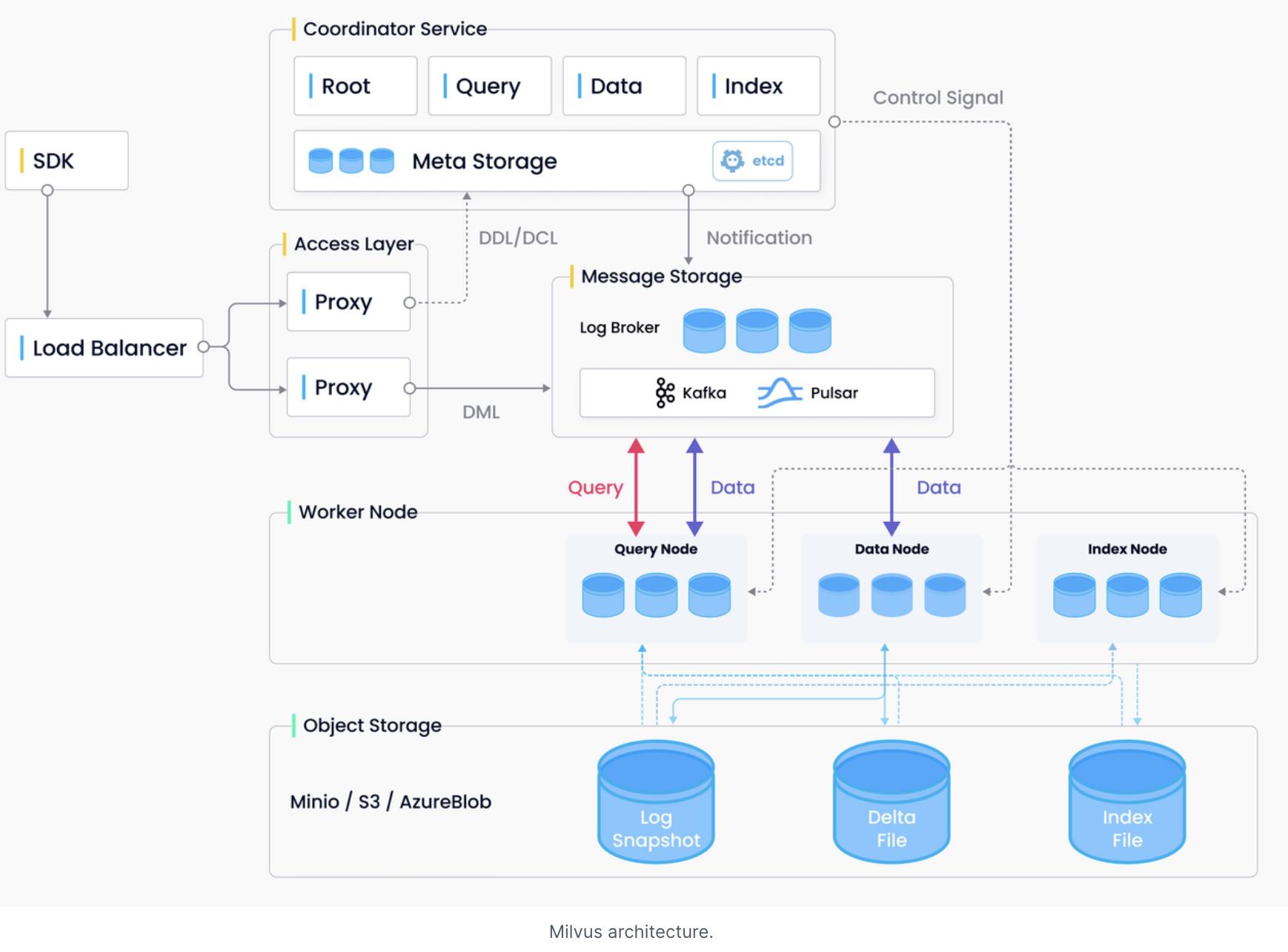
说明
因为GPT的火爆,最近一些向量数据库比较火了(支持ai 的一些能力),milvus 同时提供了官方demo 可以试用
参考资料
https://www.cnblogs.com/rongfengliang/p/17380404.html
https://github.com/qdrant/qdrant
https://milvus.io/milvus-demos
大数据系列13:milvus大规模向量检索引擎
1. 介绍与安装
参考https://milvus.io/cn/docs/home。Milvus 是一款基于云原生架构开发的开源向量数据库,支持查询和管理由机器学习模型或神经网络生成的向量数据。Milvus 在一流的近似最近邻(ANN)搜索库(例如 Faiss、NMSLIB、Annoy)的功能基础上进行扩展,具有按需扩展、流批一体和高可用等特点。
下面介绍几种安装方式:
- Docker compose方法
官网说了,只做测试使用。下载docker-compose.standalone.yml 配置文件并保存为 docker-compose.yml,然后docker-compose up -d即可 - 使用k8s
使用 Kubernetes 包管理工具 Helm 添加 Milvus chart 仓库 - 从源码安装
# Clone github repository.
$ git clone https://github.com/milvus-io/milvus.git
# Install third-party dependencies.
$ cd milvus/
$ ./scripts/install_deps.sh
# Compile Milvus.
$ make
- 使用dockerhub
参见这篇http://www.qishunwang.net/news_show_32024.aspx
这里查看GPU使用方式:https://milvus.io/cn/docs/v1.1.1/milvus_docker-gpu.md
这里是一些注意事项:https://zhuanlan.zhihu.com/p/91444753
另外可以参考一下训练营,benchmark测试也在里面。给出的案例包括:
- 近似图片搜索,使用YOLOv3进行物体检测,ResNet-50提取特征向量
- 问答系统,使用BERT模型提取语言的特征向量
- 推荐系统,使用paddlepaddle的模型
- 视频相似系统,使用VGG神经网络
- 音频相似系统,使用PANNs模型
2. 基本概念
2.1 索引选择
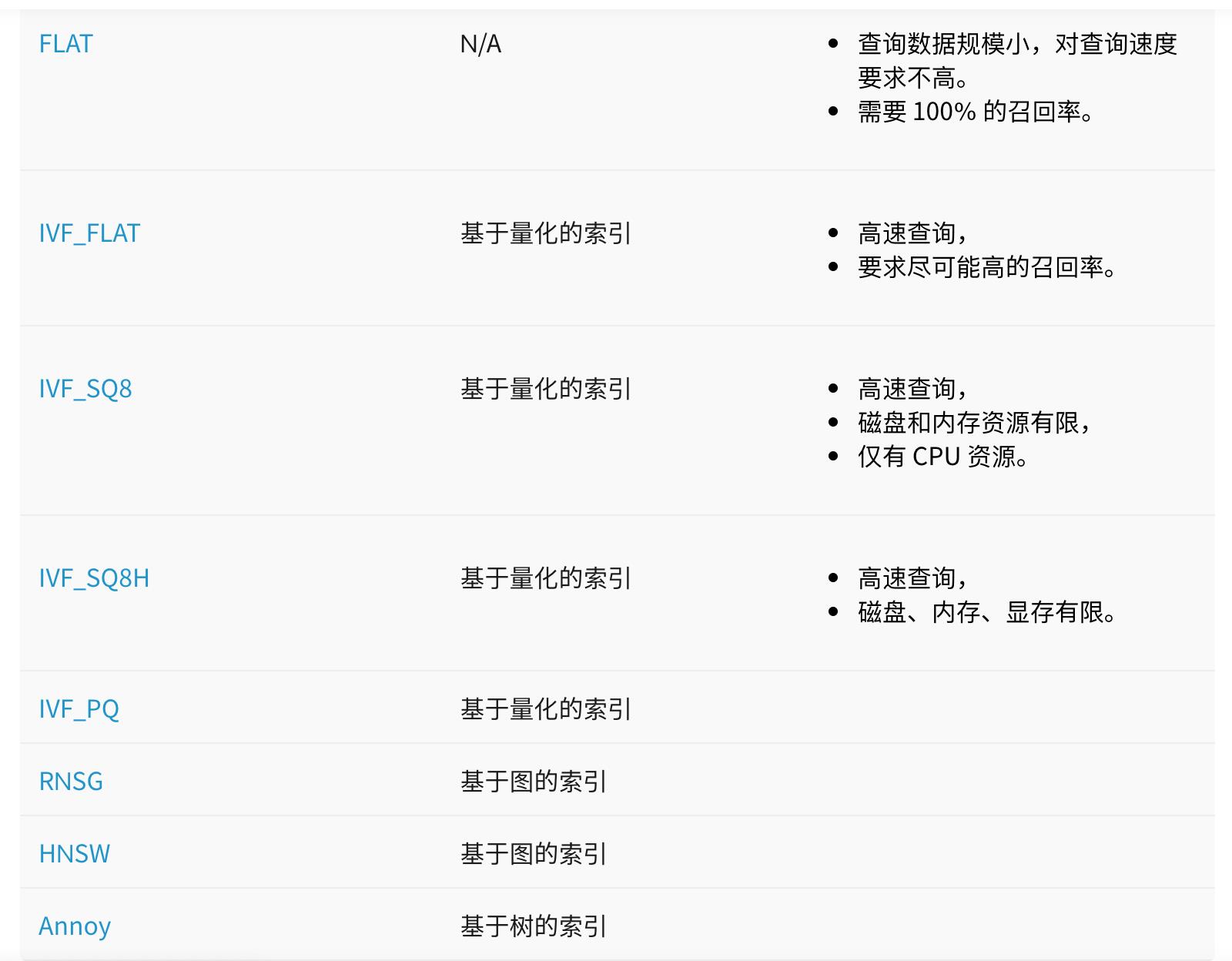
Milvus 数据段存储海量数据。在建立索引时,Milvus 为每个数据段单独创建索引。
调用 create_index() 接口时,Milvus 会对该字段上的已有数据同步建立索引。每当后续插入的数据的大小达到系统配置的 index_file_size 时,Milvus 会为其在后台自动创建索引。
当插入的数据段少于 4096 行时,Milvus 不会为其建立索引。
众所周知,建索引是一个比较消耗计算资源和时间的工作。当查询任务和后台建索引任务并发时,Milvus 通常把计算资源优先分配给查询任务,即用户发起的任何查询命令都会打断后台正在执行的建索引任务。之后仅当用户持续 5 秒不再发起查询任务,Milvus 才会恢复执行后台建索引任务。此外,如果查询命令指定的数据段尚未建成指定索引,Milvus 会直接在段内做全量搜索。
- FLAT:FLAT 索引类型是指对向量进行原始文件存储。搜索时,所有向量都会与目标向量进行距离计算和比较。FLAT 索引类型提供 100% 的检索召回率。与其他索引相比,当查询数量较少时,它是最有效的索引方法。metric_type是距离计算方式
- IVF(Inverted File,倒排文件)是一种基于量化的索引类型。它通过聚类方法把空间里的点划分成 nlist 个单元。查询时先把目标向量与所有单元的中心做距离比较,选出 nprobe 个最近单元。然后比较这些被选中单元里的所有向量,得到最终的结果。IVF_FLAT 是最基础的 IVF 索引,存储在各个单元中的数据编码与原始数据一致。注意GPU 版 Milvus 在 nprobe > 2048 时由 GPU 查询切换为 CPU 查询。
- IVF_SQ8 是在 IVF 的基础上对放入单元里的每条向量做一次标量量化(Scalar Quantization)。标量量化会把原始向量的每个维度从 4 个字节的浮点数转为 1 个字节的无符号整数,因此 IVF_SQ8 索引文件占用的存储空间远小于 IVF_FLAT。但是,标量量化会导致查询时的精度损失。建索引和查询参数同 IVF_FLAT
- IVF_SQ8H 是一种优化查询执行的 IVF_SQ8 索引类型。在不同的 nq(Number of queries,查询数量)与系统参数 gpu_search_threshold 的关系下,查询方式如下:nq ≥ gpu_search_threshold:整个查询过程都在 GPU 上执行;nq < gpu_search_threshold:在 GPU 上执行在 IVF 里寻找 nprobe 个最近单元的运算,在 CPU 上执行其它运算。建索引和查询参数同 IVF_FLAT
IVF_PQ:PQ(Product Quantization,乘积量化)会将原来的高维向量空间均匀分解成 m 个低维向量空间的笛卡尔积,然后对分解得到的低维向量空间分别做矢量量化。最终每条向量会存储在 m × nbits 个 bit 位里。乘积量化能将全样本的距离计算转化为到各低维空间聚类中心的距离计算,从而大大降低算法的时间复杂度。IVF_PQ 是先对向量做乘积量化,然后进行 IVF 索引聚类。其索引文件甚至可以比 IVF_SQ8 更小,不过同样地也会导致查询时的精度损失。 - RNSG(Refined Navigating Spreading-out Graph)是一种基于图的索引算法。它把全图中心位置设为导航点,然后通过特定的选边策略来控制每个点的出度(小于等于 out_degree),使得搜索时既能减少内存使用,又能快速定位到目标位置附近。RNSG 的建图流程如下为每个点精确寻找 knng 个最近邻结点;以 knng 个最近邻结点为基础迭代至少 search_length 次,以选出 candidate_pool_size 个可能的最邻近结点;在选出的 candidate_pool_size 个结点里按择边策略构建每个点的出边。RNSG 的查询流程与建图流程类似,以导航点为起点至少迭代 search_length 次以得到最终结果。
- HNSW(Hierarchical Small World Graph)是一种基于图的索引算法。它会为一张图按规则建成多层导航图,并让越上层的图越稀疏,结点间的距离越远;越下层的图越稠密,结点间的距离越近。搜索时从最上层开始,找到本层距离目标最近的结点后进入下一层再查找。如此迭代,快速逼近目标位置。为了提高性能,HNSW 限定了每层图上结点的最大度数 M 。此外,建索引时可以用 efConstruction,查询时可以用 ef 来指定搜索范围。
- Annoy(Approximate Nearest Neighbors Oh Yeah)是一种用超平面把高维空间分割成多个子空间,并把这些子空间以树型结构存储的索引方式。在查询时,Annoy 会顺着树结构找到距离目标向量较近的一些子空间,然后比较这些子空间里的所有向量(要求比较的向量数不少于 search_k 个)以获得最终结果。显然,当目标向量靠近某个子空间的边缘时,有时需要大大增加搜索的子空间数以获得高召回率。因此,Annoy 会使用 n_trees 次不同的方法来划分全空间,并同时搜索所有划分方法以减少目标向量总是处于子空间边缘的概率。
2.2 存储相关
建立集合时,Milvus 根据参数 index_file_size 控制数据段的大小。另外,Milvus 提供分区功能,你可以根据需要将数据划分为多个分区。对数据的合理组织和划分可以有效提高查询性能。
-
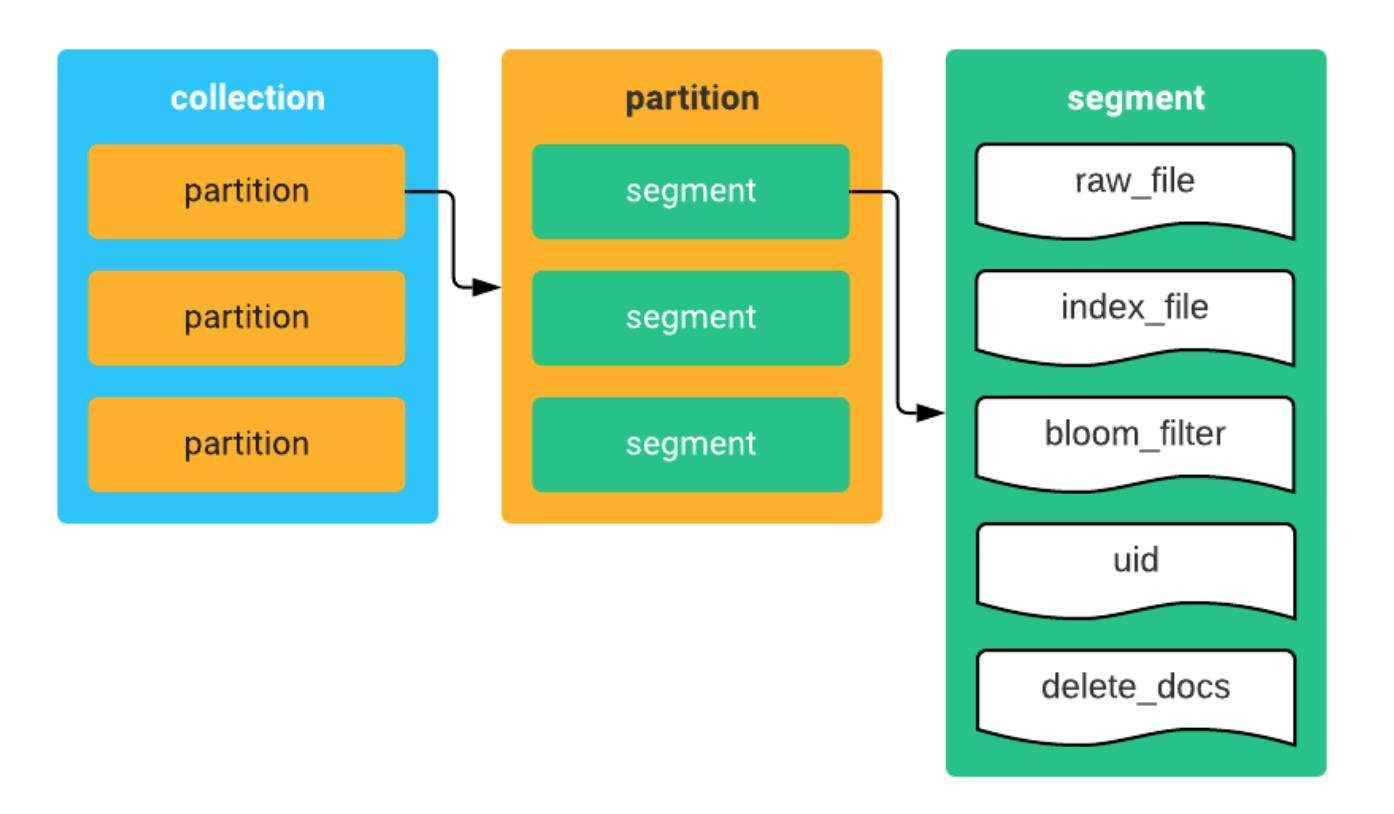
数据段(segment)
为了能处理海量的数据,Milvus 会将数据分段,每段数据拥有数万甚至数十万个实体。每个数据段的数据又按照字段(field)分开,每个字段的数据单独存为一个数据文件。目前的版本中,实体仅包含一个 ID 字段和一个向量字段,因此每个数据段的数据文件主要包括一个 UID 文件以及一个原始向量数据文件。
数据段的大小是由创建集合时的参数 index_file_size 来决定的,默认为 1024 MB,上限为 128 GB。
建立索引时,集合中的每个数据段依次建立索引,并将索引单独存为一个文件。索引文件之间相互独立。索引可以显著地提高检索性能。 -
分区(partition)
当一个集合累积了大量数据之后,查询性能会逐渐下降。而某些场景只需查询集合中的部分数据,这时就要考虑把集合中的数据根据一定规则在物理存储上分成多个部分。这种对集合数据的划分就叫分区。每个分区可包含多个数据段。
分区以标签(tag)作为标识。插入向量数据时,你可以指定将数据插入到某个标签对应的分区中。查询向量数据时,你可以根据标签来指定在某个分区的数据中进行查询。Milvus 既支持对分区标签的精确匹配,也支持正则表达式匹配。
每个集合的分区数量上限是 4096 个
3. 基本操作
3.1 数据插入
客户端通过调用 insert 接口来插入数据,单次插入的数据量不能大于 256 MB。插入数据的流程如下:
服务端接收到插入请求后,将数据写入预写日志(WAL)。
当预写日志成功记录后,返回插入操作。
将数据写入可写缓冲区(mutable buffer)。
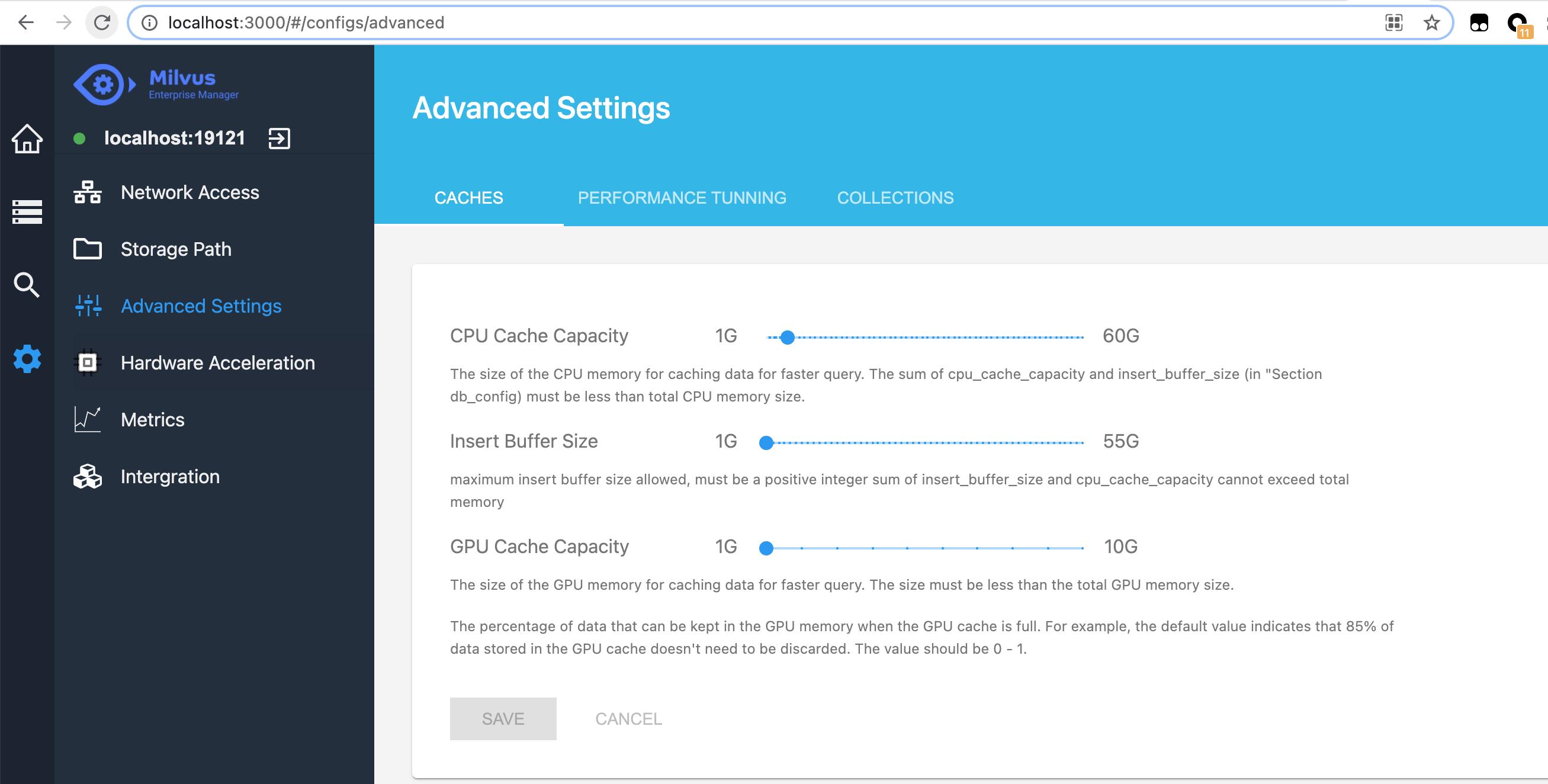
每个集合都有独立的可写缓冲区。每个可写缓冲区的容量上限是 128 MB。所有集合的可写缓冲区总容量上限由系统参数 insert_buffer_size 决定,默认是 1 GB。
3.2 数据落盘
缓冲区中的数据落盘有三种触发机制:
-
定时触发
系统会定时触发落盘任务。定时间隔由系统参数 auto_flush_interval 决定,默认是 1 秒。
落盘操作的流程如下:
系统开辟一块新的可写缓冲区,用于容纳后续插入的数据。
系统将之前的可写缓冲区设为只读(immutable buffer)。
系统把只读缓冲区的数据写入磁盘,并将新数据段的描述信息写入元数据后端服务。
完成以上流程后,系统就成功创建了一个数据段(segment)。 -
客户端触发
由客户端调用 flush 接口触发落盘。 -
缓冲区达到上限触发
累积数据达到可写缓冲区的上限(128MB)会触发落盘操作。
每个数据段的所有相关文件都被存放在以段 ID 命名的文件夹中,比如记录实体 ID 的 UID 文件、用于标记已被删除实体的 delete_docs 文件,以及用于快速查找实体的布隆过滤器(bloom-filter)文件。
3.3 数据合并
小数据段过多会导致查询性能低下。为了避免此问题,Milvus 会在需要的时候触发后台段合并任务,即把小数据段合并成新的数据段,并删除小数据段、更新元数据。其中,新数据段的大小不低于 index_file_size。
合并操作的触发时机如下:
启动服务时
完成落盘任务后
建索引前
删除索引后
3.4 删除
-
删除集合:客户端调用 drop_collection 接口来删除一个集合。
服务端接收到请求后,仅在元数据中把该集合(包括它的分区和段)标记为删除状态。对于已标记为删除状态的集合,将无法再对其进行任何新操作(比如插入和查询)。
后台的清理任务将被标记为删除状态的集合(包括它的分区和段)从元数据中删除,然后将该集合的数据文件和文件夹从磁盘上删除。如果在删除操作之前已经有对该集合的操作正在执行,后台清理任务不会删除正在使用的段,直到操作完成。 -
删除分区:客户端调用 drop_partition 接口来删除一个分区。
服务端接收到请求后,仅在元数据中把该分区(包括它的段)标记为删除状态。
后台清理任务按照删除集合的流程来删除该分区和元数据。 -
删除实体:Milvus 为每个数据段建立了一个 delete_docs 文件,用来记录被删除向量在段内的位置。
Milvus 使用布隆过滤器(bloom filter)来快速判断一个实体 ID 是否可能存在于某个数据段中。因此,在每个数据段下都创建了一个名为 bloom_filter 的文件。
删除实体的流程如下:
客户端调用 delete_entity_by_id 接口删除集合中的实体。
服务端接收到请求后,执行以下操作删除实体:
如果该实体在插入缓冲区中,直接删除该实体。
否则,根据每个数据段的布隆过滤器判断该实体所处的数据段,然后更新该数据段的 delete_docs 以及 bloom_filter 文件。 -
数据段整理:查询一个数据段时,Milvus 会将该数据段的实体数据以及 delete_docs 文件读入内存。虽然被删除的实体不参与计算,但它们也会被读入内存。所以,一个数据段中被删除的实体越多,浪费的内存资源和磁盘空间越多。为了减少此类不必要的资源消耗,Milvus 提供了数据段整理(compact)的操作,流程如下:
客户端调用 compact 接口。
服务端接收到请求后,根据 delete_docs 所记录的信息,将段内未被删除的实体写入一个新的数据段,并把旧数据段标记为删除状态。之后将由后台清理任务负责清理被标记为删除状态的数据段。如果旧数据段已建立索引,新数据段产生之后会重建索引。
compact 操作会忽略被删除向量占比小于 10% 的数据段。
基准测试
从SIFT1B Dataset(10亿)中提取数据进行性能测试。测试过程见https://github.com/milvus-io/bootcamp/blob/master/benchmark_test/lab1_sift1b_1m.md和https://github.com/milvus-io/bootcamp/blob/master/benchmark_test/lab2_sift1b_100m.md
5. python接口
5.1 连接
使用以下任意一种方法连接 Milvus 服务端:
milvus = Milvus(host='localhost', port='19530')
milvus = Milvus(uri='tcp://localhost:19530')
milvus.drop_collection(collection_name='test01')
5.2 创建集合、分区
创建集合:相当于建表
param = {'collection_name':'test01', 'dimension':256, 'index_file_size':1024, 'metric_type':MetricType.L2}
milvus.create_collection(param)
创建分区:你可以通过标签将集合分割为若干个分区,从而提高搜索效率。每个分区实际上也是一个集合。
milvus.create_partition('test01', 'tag01')
milvus.drop_partition(collection_name='test01', partition_tag='tag01')
5.3 插入、删除向量
插入向量时,如果你不指定向量 ID,Milvus 自动为向量分配 ID。Milvus 中数据是分文件存储的,后续新增向量会存在新的数据文件中。该文件达到一定量后会自动触发建立索引,生成一个新的索引文件,不会影响之前已经建立过的索引。
import random
# Generate 20 vectors of 256 dimensions.
vectors = [[random.random() for _ in range(256)] for _ in range(20)]
milvus.insert(collection_name='test01', records=vectors)
vector_ids = [id for id in range(20)]
milvus.insert(collection_name='test01', records=vectors, ids=vector_ids)
milvus.insert('test01', vectors, partition_tag="tag01")
假设你的集合中存在以下向量 ID:ids = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19],你可以通过以下命令删除向量:
milvus.delete_entity_by_id(collection_name='test01', id_array=ids)
5.4 创建索引
create_index() 会指定该集合的索引类型,并同步为之前插入的数据建立索引,后续插入的数据在大小达到 index_file_size 时,索引会在后台自动建立。在实际生产环境中,如果是流式数据,建议在插入向量之前先创建索引,以便后续系统自动建立;如果是静态数据,建议导入所有数据后再一次性创建索引。更多索引用法请参考https://github.com/milvus-io/pymilvus/blob/master/examples/old_style_example_index.py。
ivf_param = {'nlist': 16384}
# Create an index.
milvus.create_index('test01', IndexType.IVF_FLAT, ivf_param)
milvus.drop_index('test01')
删除索引后,集合再次使用默认索引类型 FLAT。
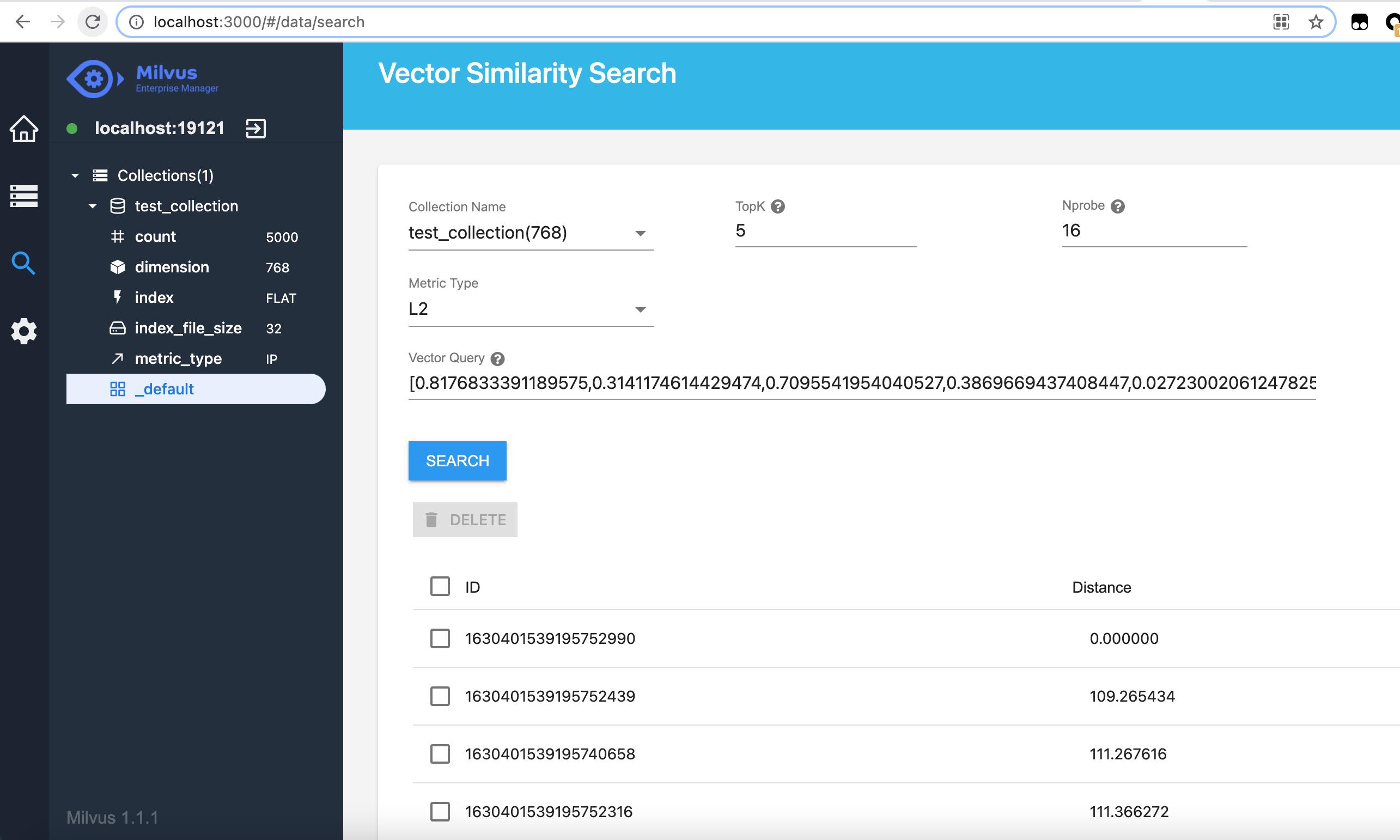
5.5 进行搜索
对于不同的索引类型,搜索所需参数也有区别。所有的搜索参数都必须赋值。详细信息请参考 Milvus 索引类型。
search_param = {'nprobe': 16}
# Create 5 vectors of 256 dimensions.
q_records = [[random.random() for _ in range(256)] for _ in range(5)]
milvus.search(collection_name='test01', query_records=q_records, top_k=2, params=search_param)
如果你不指定 partition_tags, Milvus 会在整个集合中搜索。下面是在分区中查询向量
# Create 5 vectors of 256 dimensions.
q_records = [[random.random() for _ in range(256)] for _ in range(5)]
milvus.search(collection_name='test01', query_records=q_records, top_k=1, partition_tags=['tag01'], params=search_param)
5.6 落盘、整理
milvus.flush(collection_name_array=['test01'])
milvus.compact(collection_name='test01', timeout=1)
5.9 综合例子
# -*- coding: utf-8 -*-
# 导入相应的包
import numpy as np
from milvus import Milvus, MetricType
# 初始化一个Milvus类,以后所有的操作都是通过milvus来的
milvus = Milvus(host='localhost', port='19530')
# 向量个数
num_vec = 5000
# 向量维度
vec_dim = 768
# name
collection_name = "test_collection"
# 创建collection,可理解为mongo的collection
collection_param = {
'collection_name': collection_name,
'dimension': vec_dim,
'index_file_size': 32,
'metric_type': MetricType.IP # 使用内积作为度量值
}
milvus.create_collection(collection_param)
# 随机生成一批向量数据
# 支持ndarray,也支持list
vectors_array = np.random.rand(num_vec, vec_dim)
# 把向量添加到刚才建立的collection中
status, ids = milvus.insert(collection_name=collection_name, records=vectors_array) # 返回 状态和这一组向量的ID
milvus.flush([collection_name])
# 输出统计信息
print(milvus.get_collection_stats(collection_name))
# 创建查询向量
query_vec_array = np.random.rand(1, vec_dim)
# 进行查询,
status, results = milvus.search(collection_name=collection_name, query_records=query_vec_array, top_k=5)
print(status)
print(results)
# 如果不用可以删掉
status = milvus.drop_collection(collection_name)
# 断开、关闭连接
milvus.close()
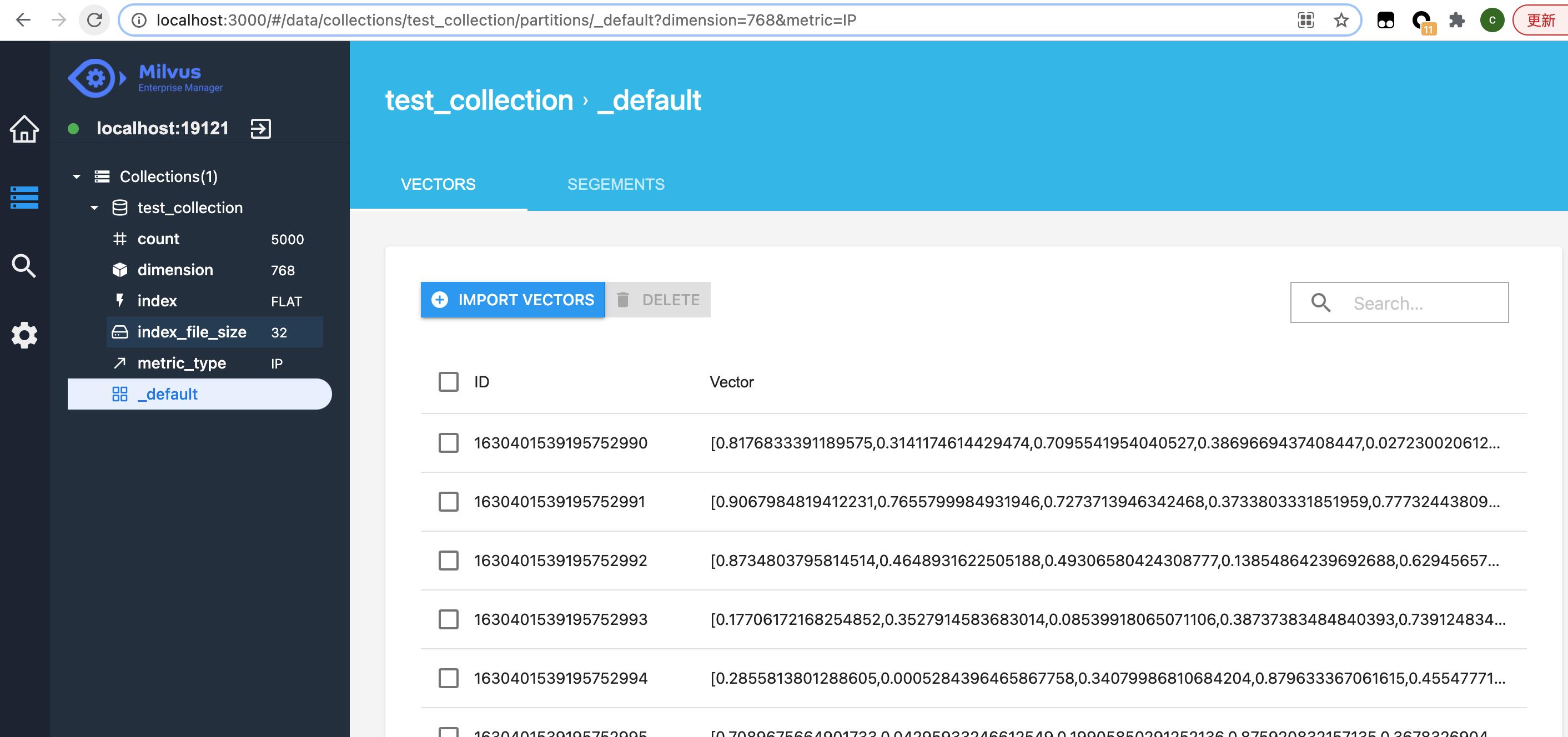
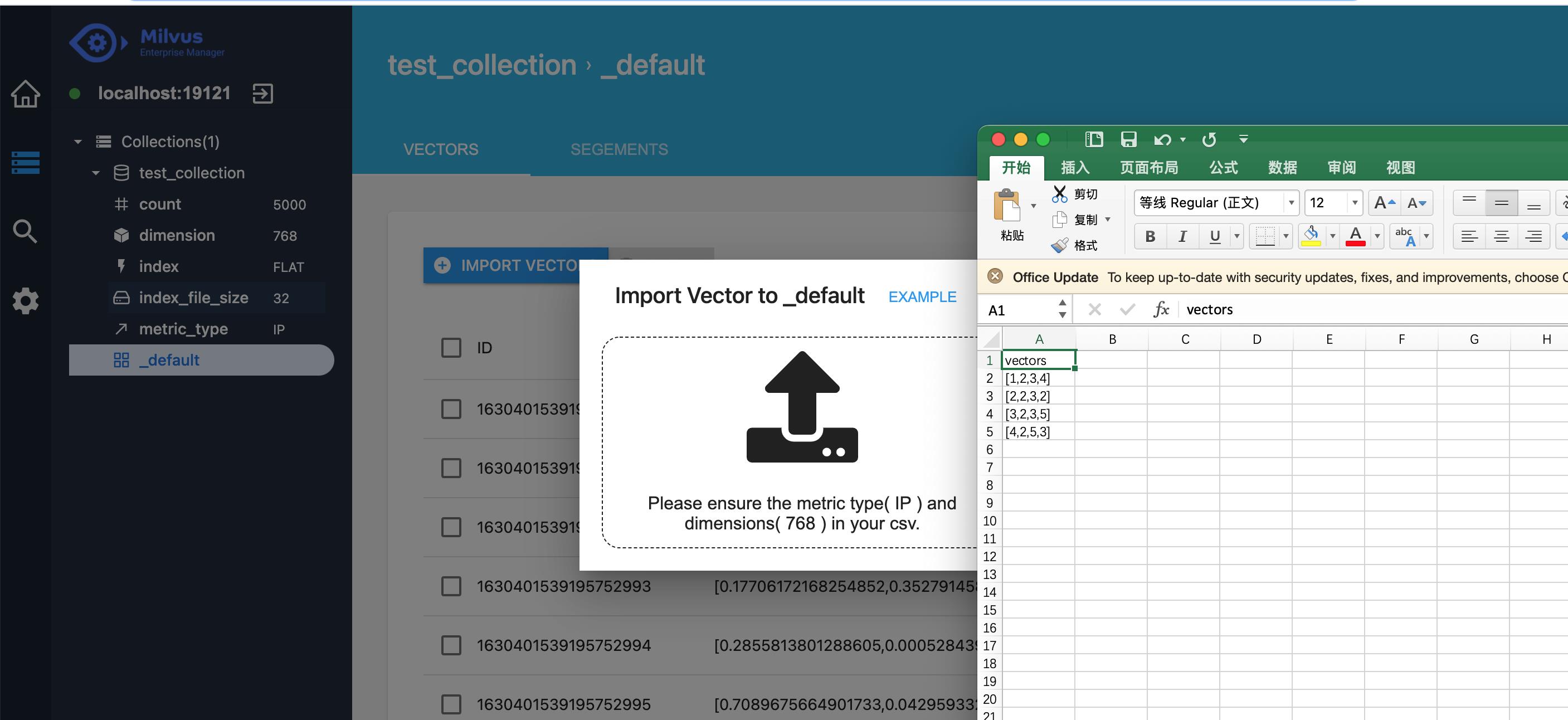
6. 图形管理界面
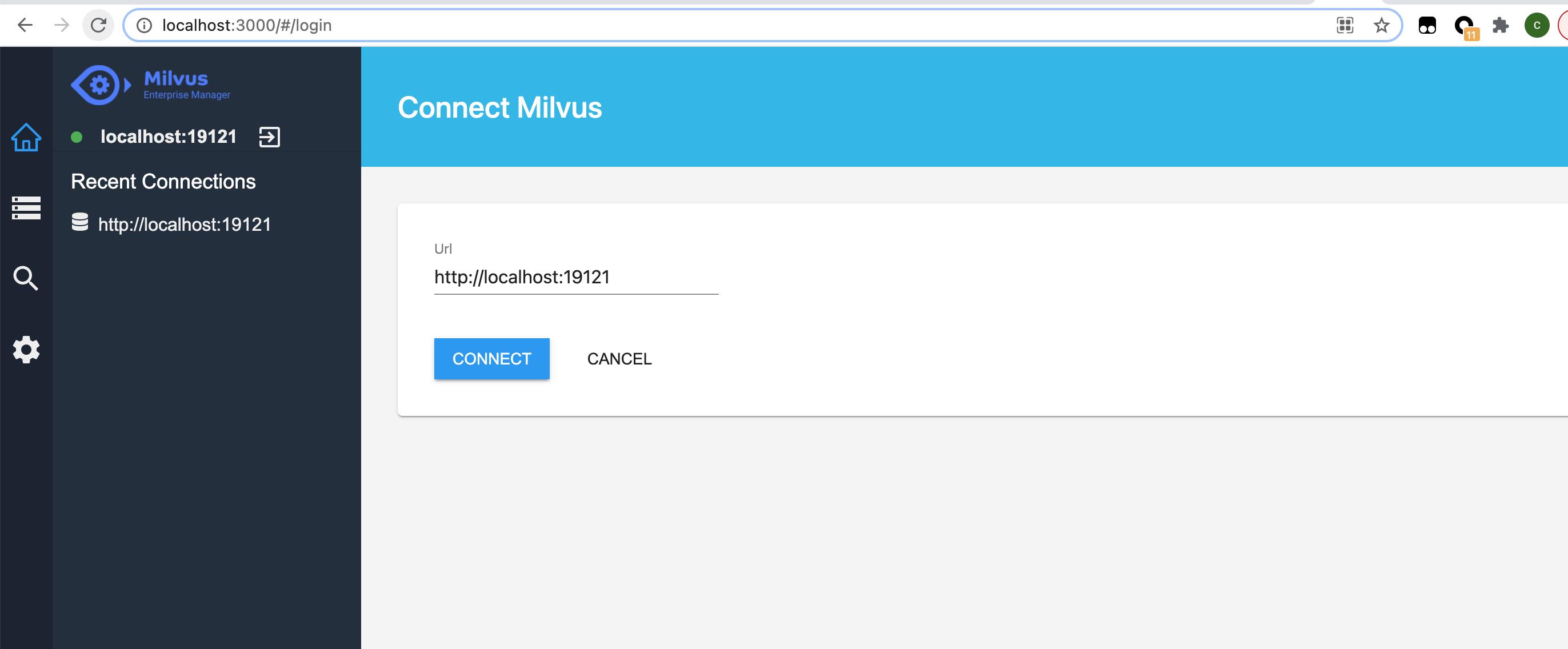
如下代码安装控制台
docker pull milvusdb/milvus-em:v0.4.2
docker run -d -p 3000:80 milvusdb/milvus-em:v0.4.2
登录http://localhost:3000/,在url填入http://localhost:19121,就可以进行管理界面了
以上是关于milvus 又一个开源的向量数据库的主要内容,如果未能解决你的问题,请参考以下文章