房东要给我涨800房租,生气的我用Python抓取帝都几万套房源信息,我主动涨了1000。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了房东要给我涨800房租,生气的我用Python抓取帝都几万套房源信息,我主动涨了1000。相关的知识,希望对你有一定的参考价值。
老猫我在南五环租了一个80平两居室,租房合同马上到期,房东打电话问续租的事,想要加房租;我想现在国家正在也在抑制房价,房子价格没怎么涨,房租应该也不会涨,于是霸气拒绝了,以下是聊天记录: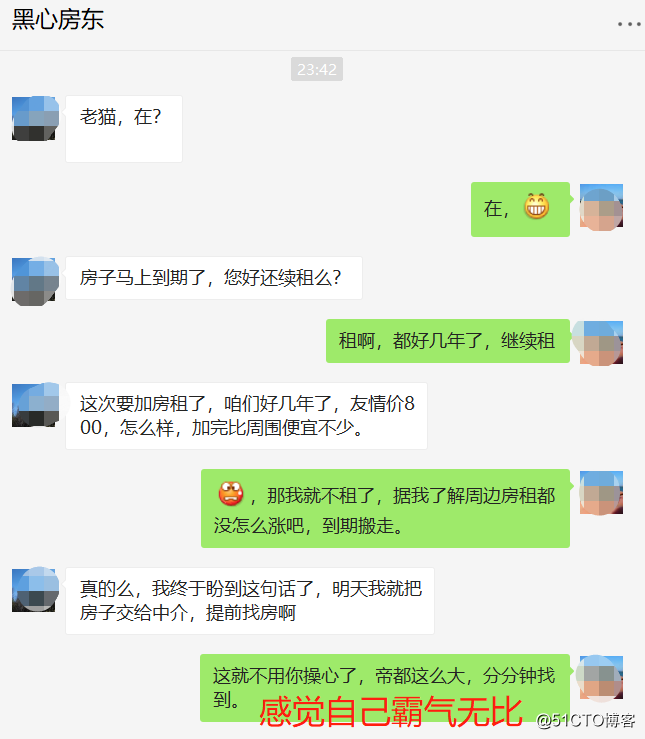
确认不续租之后,两三年没找过房的我上网搜索租房,没想到出来一坨自如,蛋壳,贝壳等中介网站;进去看看,各种房照非常漂亮,但是一看房租,想送给自己一首《凉凉》;附近房租居然比我当前房租高1000多RMB;自我安慰下,这些网站房源价格不是真实的,于是切换到我爱我家,链家等大中介平台,结果发现房租价格都差不多;心想这才几年,如果两年前对自己狠点买了房,房租都够还房贷了。为了生存,不甘心的我,决定把这些大网站的房源信息抓取下来进行分析,帝都这么大总有一套适合自己。
说干就干,先找到市场上主要的中介平台,主要关注我爱我家、链家、贝壳,还有类似于自如,蛋壳等长租公寓;还有一个问题,好像链家、贝壳、自如是一个大老板,链家房源和自如的都是混到一起的,整的我一个头大;贝壳类似于京东,不仅自己自营,还允许其他平台来入住这个平台,这老板头脑真是好使,折腾半天数据都在自己手里了,总感觉房价与房租上涨感觉和这个货有种说不清的关系。
最后决定使用Python抓取链家,我爱我家,与贝壳网租房信息。
租住小区门口就有一个链家,先从链家下手;抓取与分析过程如下:
1:查看链家租房信息,决定抓取那些数据;
2:请求行为分析;
3:分析使用知识点,
4:抓取实现;
5:对出租房源信息进行分析;
1.使用浏览器查看要抓取信息:
借助浏览器打开链家主页,查看要抓取信息,如下图: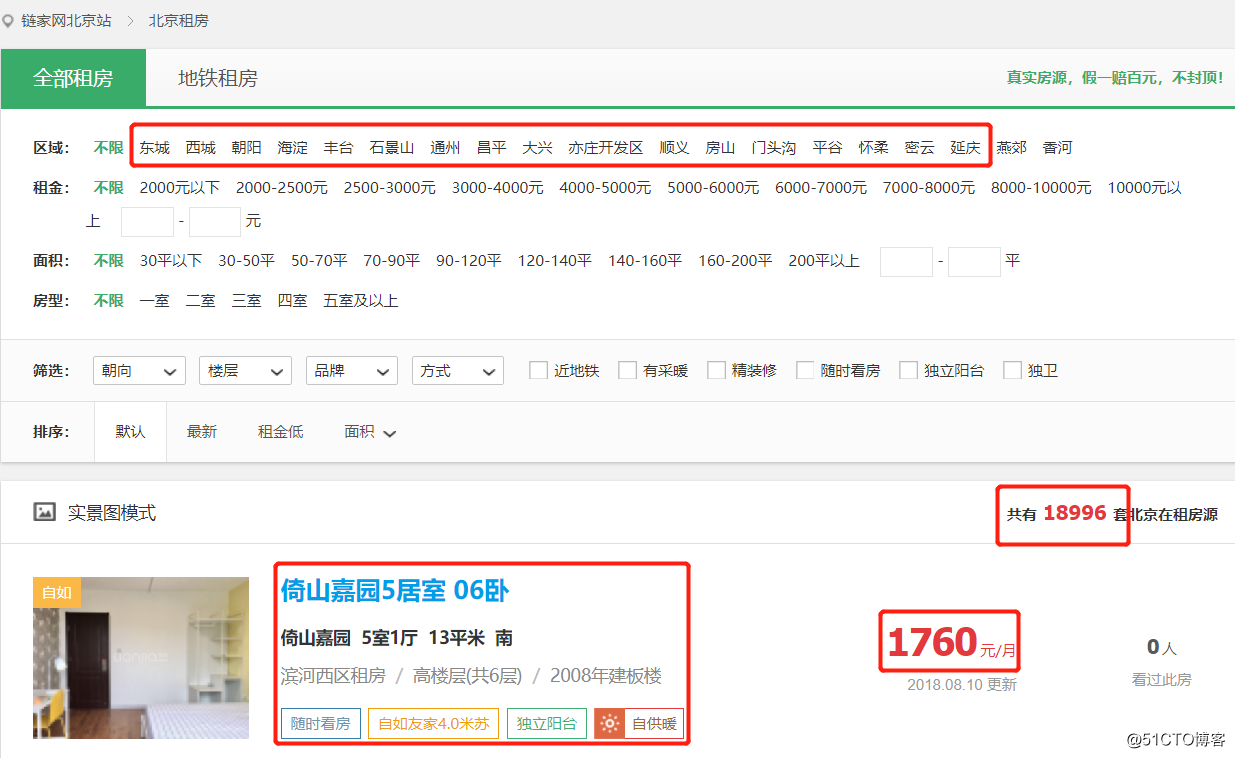
从当前信息中可以看到,链家有近19000套再租房源(某些为单间);
抓取信息包括:所属小区,户型,面积,价格,所属区域,具体地址,房龄,房屋编号及详情页地址;确认抓取信息后,分析请求行为,如何进行抓取。
2.请求行为分析:
使用浏览器打开页面,查看请求过程,需要分下面几步进行抓取:
1> 请求首页:https://bj.lianjia.com/zufang/;
2>解析北京下行政区对对应url,注意,这里不包括燕郊与香河;
3>按照行政区进行查找,提取页面房源信息,并请求下一页,直到请求结束;
整个请求过程如下:
确认抓取过程后,我们确认使用哪些知识点。
3.知识点分析:
整个抓取过程分为请求数据,提取信息,数据保存,老猫这边使用Python实现,主要知识点如下:
1>请求数据:requests模块;
2>提取信息:BeautifulSoup模块;
3>数据保存:csv格式存储,csv模块;
请求行为与知识点分析完成后,老猫在Jupyter下完成了单页数据抓取与提取,具体过程这里不详细讲解了,直接上最终代码与结果。
4.链家出租房信息抓取实现:
老猫在这里使用类实现抓取,简单描述实现过程:
1>整理思路,确认要做的事情,分步实现;
1>根据请求与提取行为定义类与相关方法;
2>将Jupyter下实现填充到对应方法中;
3>存储类实现;
4>代码调试与运行;
最终代码如下:
#coding=utf-8
#Author: qimao
import requests
from bs4 import BeautifulSoup
import json
import csv
import time
class CsvSaveModule(object):
#存储csv类
def __init__(self, fname = "info.csv"):
self.f = open(fname, ‘w‘)
self.fcsv = csv.writer(self.f)
self.head = True
def write(self, keys, data):
#写入字段
if self.head:
self.head = False
self.fcsv.writerow(keys)
#获取并写入数据
values = [data.get(key, "") for key in keys]
self.fcsv.writerow(values)
def close(self):
self.f.close()
class SpiderMoujia(object):
def __init__(self, *args):
‘args:保存数据对象‘
self.urlhead = ‘https://bj.lianjia.com/‘
self.hds = args
def reqPage(self, url):
num = 0
#一个页面最多尝试请求三次
while num < 3:
#请求页面信息,添加请求异常处理,防止某个页面请求失败导致整个抓取结束,
try:
if url:
req = requests.get(url)
if req.status_code == 200:
#返回BeautifulSoup对象
return BeautifulSoup(req.text, ‘html5lib‘)
except:
pass
time.sleep(3)
num += 1
def startCrawler(self, url):
#抓取对外接口,Url为种子url
self.startRequest(url)
self.close()
def startRequest(self, url):
#开始抓取
obj = self.reqPage(url)
areas = obj.find(‘div‘, class_="option-list")
#提取区域信息:海淀,朝阳,....
listarea = areas.select(‘a[href^="/zufang/"]‘)
for area in listarea[1:]:
aurl = self.urlhead + area.get(‘href‘)
district = area.text.strip()
#按照区域进行抓取
self.crawlerArea(aurl,district)
def crawlerArea(self, url, district):
#print(‘crawlerArea‘, url)
page = self.reqPage(url)
if not page:
return
#解析页面信息
self.parsePage(page,district)
#获取下一页地址
nextpage = self.getNextPage(page)
if nextpage:
urlhead = url.rsplit(‘/‘,1)[0]
nexturl = ‘/‘.join([urlhead, nextpage])
#继续请求下一页
self.crawlerArea(nexturl,district)
def extractInfo(self, node, css):
snode = node.select_one(css)
val = ‘‘
if snode and snode.text:
val = snode.text.strip()
return val
def parsePage(self, page,district):
#主要功能,提取页面信息
listhouse = page.select(‘#house-lst > li‘)
#定义出提取字段
keys = [‘信息‘, ‘小区‘, ‘户型‘, ‘价格‘, ‘面积‘, ‘区域‘,
‘位置‘, ‘楼层‘, ‘年份‘, ‘附加信息‘, ‘房屋ID‘, ‘详情页地址‘]
for house in listhouse:
hinfo = []
#提取title, 小区,户型,价格,面积
cssexpress = [‘h2 a‘, ‘.where a‘, ‘.zone‘, ‘.num‘,‘.meters‘]
info = house.select_one(".info-panel")
if not info:
continue
for express in cssexpress:
hinfo.append(self.extractInfo(info, express))
#添加区域
hinfo.append(district)
#区域,楼层,年代
hinfo.extend(info.select_one(‘.con‘).text.split(‘/‘))
#房子其他信息,例如:地铁,阳台,供暖等
spans = info.select_one(‘.view-label‘)
hpoint = ‘,‘.join((spans.stripped_strings))
hinfo.append(hpoint)
#房子ID号,唯一标识
hinfo.append(house.get(‘data-id‘))
#房租详情页url
hinfo.append(info.select_one(‘h2 a‘).get(‘href‘))
#转换成字典
housedata = dict(zip(keys, hinfo))
print (housedata)
self.saveData(housedata)
def getNextPage(self, page):
try:
#获取下一页
pagenode = page.select_one(‘.page-box‘)
pageinfo = pagenode.get(‘page-data‘)
jdata = json.loads(pageinfo)
curpage = jdata.get(‘curPage‘)
total = jdata.get(‘totalPage‘)
if (curpage < total):
return ‘pg%d‘%(int(curpage+1))
except:
print(‘error‘)
pass
def saveData(self, data):
#按照顺序保存数据
keys = [‘信息‘, ‘小区‘, ‘户型‘, ‘价格‘, ‘面积‘, ‘区域‘,
‘位置‘, ‘楼层‘, ‘年份‘, ‘附加信息‘, ‘房屋ID‘, ‘详情页地址‘]
[hd.write(keys, data) for hd in self.hds]
def close(self):
#列表解析关闭存储模块
[hd.close() for hd in self.hds]
if __name__ == ‘__main__‘:
#开始抓取
url = ‘https://bj.lianjia.com/zufang/‘
csvhd = CsvSaveModule(‘ljinfo.csv‘)
spider = SpiderMoujia(csvhd)
spider.startCrawler(url)运行过程如下图:
最终获取了1W多套出租房信息;到这里我完成链家出租房员信息抓取。
5.我爱我家与贝壳抓取分析。
我爱我家是一个老牌的房地产中介,老猫来帝都10年了,毕业当年大部分同学干了当年认为比较正统的工作,一个另类同学去了我爱我家做中介,早些年他经常群里发消息,给我们介绍房源,大家认为他是推销,很少有人理他;最近同学聚会见面我问他:你当年为什么不在使劲逼着我买房?同学抬起头,吸了一口烟吐了一圈,说了一句话,让我感觉夏天顿时凉爽了许多:‘逼你你也买不起,逼你你也买不起,逼你你也买不起,重要事情说三遍‘,感觉友谊的小船就要翻了。
下面我们来看我爱我家出租房源页面信息,如下图: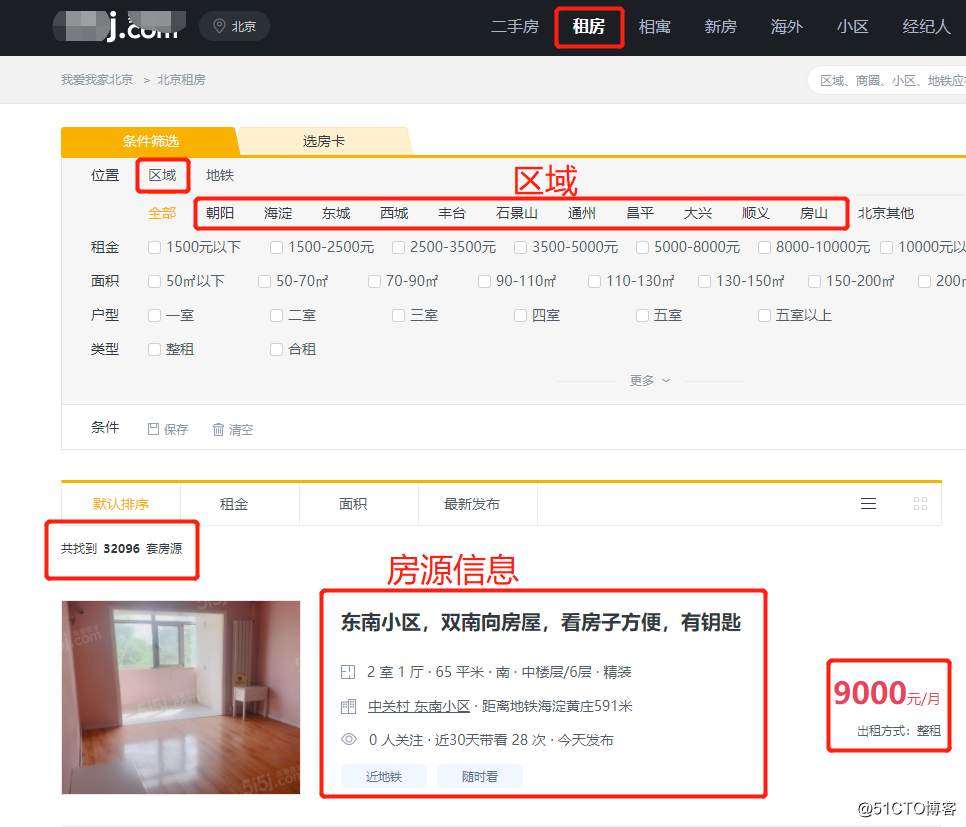
从页面中我们可以看到,我爱我家有3.2万套出租房源,房源信息比较直观;通过分析发现抓取我爱我家请求行为与抓取链家类似,不同之处在于提取数据与提取过程;我们可以在基于链家爬虫进行修改实现;具体实现过程在这里不详细讲解,直接上抓取部分结果:
区域,地址,小区,价格,面积,楼层,装修,地铁附近,户型,朝向,信息,附加信息,详情
朝阳,望京,宝星国际,8000,64 平米,低楼层/25层,精装,距离地铁望京东450米,1 室 1 厅,南,宝星国际紧邻望京SOHO 阿里巴巴 精装朝南大开间,"近地铁,随时看,拎包入住,押金减免",/zufang/41330436.html
朝阳,望京,炫彩嘉轩,6500,60 平米,中楼层/21层,精装,距离地铁望京东760米,1 室 0 厅,南,炫彩一居室老业主委托 我有钥匙 邻望京SOHO,"近地铁,可短租,拎包入住,集中供暖",/zufang/41348206.html
朝阳,望京,宝星国际,8500,64 平米,高楼层/25层,精装,距离地铁望京东450米,1 室 1 厅,南北,望京SOHO旁宝星国际,邻阿里巴巴,绿地,南向大开间,"近地铁,随时看,拎包入住,押金减免",/zufang/41331126.html
朝阳,CBD,阳光100国际公寓,9500,48 平米,低楼层/33层,精装,距离地铁大望路391米,1 室 1 厅,北,阳光100国际公寓精装开 二次装修有钥匙看房方便,"近地铁,随时看,免佣,拎包入住",/zufang/41330729.html
朝阳,望京,朝庭公寓,13000,112 平米,高楼层/27层,精装,距离地铁望京南476米,2 室 1 厅,南北,望京南朝庭公寓,邻悠乐汇和方恒国际,看房有钥匙,随时看房,"近地铁,随时看,免佣,拎包入住",/zufang/41337320.html
朝阳,石佛营,日月东华,6700,66.3 平米,顶层/21层,精装,距离地铁十里堡1072米,1 室 1 厅,南,石佛营新上婚房一居拎包入住 看房预约,"近地铁,拎包入住,集中供暖",/zufang/41348814.html
朝阳,惠新西街,胜古北里,2800,58 平米,底层/5层,精装,距离地铁惠新西街南口232米,3 室 1 厅,北,随时看 随时住三家合住正规中卧室精装修,"近地铁,随时看,拎包入住,集中供暖",/zufang/41338276.html
朝阳,潘家园,弘善家园,5300,61 平米,中楼层/13层,精装,距离地铁十里河691米,1 室 1 厅,南,十里河 潘家园10号线 弘善家园精装正规一居 拎包入住,"近地铁,拎包入住",/zufang/41334177.html
朝阳,东坝,朝阳新城一区,6500,114 平米,中楼层/6层,精装,,2 室 1 厅,南北,朝阳新城一区两室一厅,随时看,/zufang/41351101.html
朝阳,十里堡,十里堡,6000,60 平米,底层/4层,中装,距离地铁十里堡781米,2 室 1 厅,南北,6号线 十里堡 南北两居带小院子 居家必备,"近地铁,随时看,集中供暖",/zufang/41345370.html
朝阳,十里堡,十里堡北里,5000,50 平米,中楼层/13层,中装,距离地铁十里堡371米,1 室 1 厅,南北,十里堡 八里庄北里 晨光家园 随时看,"近地铁,免佣",/zufang/41342158.html
朝阳,南沙滩,南沙滩小区,7000,65 平米,中楼层/6层,精装,距离地铁北沙滩775米,2 室 1 厅,南北,南沙滩 中间层两居室 临地铁北辰中科院 有钥匙,"近地铁,随时看,拎包入住",/zufang/41341943.html
朝阳,管庄,管庄周井大院,6000,72 平米,中楼层/5层,精装,距离地铁双桥604米,3 室 1 厅,南北,管庄周井大院精装三居室出租 随时入住,"近地铁,随时看,拎包入住,集中供暖",/zufang/41339579.html
朝阳,百子湾,金泰先锋,10000,92 平米,底层/11层,精装,距离地铁百子湾437米,2 室 1 厅,南北,金泰先锋 南北两室一厅一厨一卫,"近地铁,拎包入住,集中供暖",/zufang/41328442.html
朝阳,北苑,蕴实园,5800,66.37 平米,中楼层/14层,精装,距离地铁北苑571米,1 室 1 厅,南,钥匙房源,看房随时。,"近地铁,随时看,拎包入住",/zufang/41349514.html
朝阳,芍药居,芍药居,13000,118.38 平米,中楼层/14层,简装,距离地铁芍药居116米,3 室 1 厅,南,芍药居南里精装修三室一厅,"近地铁,随时看,拎包入住,集中供暖",/zufang/41348855.html
朝阳,双桥,东一时区,4500,65 平米,中楼层/26层,精装,距离地铁管庄1214米,1 室 1 厅,西北,管庄 东一时区 精装一居室 家电齐全 随时入住看房,"近地铁,拎包入住,集中供暖",/zufang/41346286.html
...最后我们来看贝壳抓取,贝壳是近些年起来的中介平台,有点类京东,不仅有链家,自如房源,还有其他家;除了贝壳,还有其他很多短租长租平台,例如小猪短租,蛋壳等;
有时候我常思考一个问题:
负能量:这些网站都是IT开发人员搞得,我们都是一个行业,为什么要自己坑自己。如果没有这么多中介平台去抢房源,炒房价,价格可能落下来;
正能量:中介伤根据市场需求搭建中介平台,使广大租客可以从正规渠道租房,远离黑中介,给我们省去很多租房过程中遇到难题与烦恼,我们应该感谢这些中介商。
下面我们看下贝壳网页面信息:
贝壳房源信息中除了基本信息,还包括房源属于谁,例如:自如,链家,xx公寓等;贝壳抓取过程和链家也是类似的,具体实现在这里不详细讲解,直接看我们抓取的数据:中介商,价格,面积,信息,区域,位置,户型,楼层,附加信息,详情页地址 链家,14000,84㎡,整租 · 海运仓小区 3室1厅 14000元,东城,东直门,3室1厅1卫,低楼层(7层),"近地铁,精装,集中供暖",/zufang/BJ2058598225715675136.html 链家,9200,89㎡,整租 · 安定门 安德路 精装修大两居 可拎包入住,东城,安定门,2室1厅1卫,高楼层(19层),"近地铁,精装",/zufang/BJ2047499309347512320.html 链家,6000,61㎡,整租 · 安化南里 1室1厅 6000元,东城,广渠门,1室1厅1卫,低楼层(16层),"近地铁,新上,随时看房",/zufang/BJ2062732570394894336.html 链家,3500,14㎡,整租 · 南剪子巷 1室1厅 3500元,东城,东四,1室1厅0卫,低楼层(1层),"近地铁,新上,随时看房",/zufang/BJ2064894449783685120.html 链家,25000,158㎡,整租 · 东城逸墅南北通透大三居 婚房出租 可看房 家具齐全,东城,工体,3室1厅2卫,中楼层(7层),"近地铁,精装,集中供暖,双卫生间,随时看房",/zufang/BJ2034641117466591232.html 城家精选公寓,11300,43㎡,整租 · 元嘉国际公寓 1室0厅,东城,东直门,1室0厅1卫,未知(10层),"公寓,租房节,七天换租,近地铁,精装,集中供暖,免中介费,押一付一,新上",/zufang/BJ2066558104174067712.html 链家,28000,207㎡,盛德大厦 4室2厅 28000元,东城,和平里,4室2厅2卫,中楼层(20层),"近地铁,集中供暖,随时看房",/zufang/BJ2049715273455910912.html 龙源易家,3500,26㎡,合租 · 海运仓小区 3室1厅,东城,东直门,3室1厅1卫,未知(6层),"限女生,限男生,独立卫生间,租房节,近地铁,精装,独立阳台,集中供暖,免中介费,新上",/zufang/BJ2066335711790891008.html ... `` 房源信息抓取完成后保存到csv文件中,然后使用对数据进行分析。
5.房源价格分析:
老猫算了下,三个平台数据加起来差不多7W套左右(链家数据和贝壳有重复,同一个房员可同时挂在链家与我爱我家中),所有应该到不了7W套。
我们使用分析模块为Python中的matplotlib, pandas, seaborn, pyecharts;
5.1:分析北京各辖区的总的价格分布:
以上是关于房东要给我涨800房租,生气的我用Python抓取帝都几万套房源信息,我主动涨了1000。的主要内容,如果未能解决你的问题,请参考以下文章