R语言Apriori算法关联规则对中药用药复方配伍规律药方挖掘可视化
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言Apriori算法关联规则对中药用药复方配伍规律药方挖掘可视化相关的知识,希望对你有一定的参考价值。
全文链接:http://tecdat.cn/?p=32316
原文出处:拓端数据部落公众号
我们常说的中药挖掘,一般是用药挖掘,还有穴位的挖掘,主要是想找出一些用药的规律。在中医挖掘中,数据的来源比较广泛,有的是通过临床收集用药处方,比如,一个著名老中医针对某一疾病的用药情况;有的是通过古籍,古代流传下来的药方;还有一种情况是在论文数据框里查找专门治疗某一疾病的文献,从中找到处方,用来分析。
Apriori算法是一种最有影响的挖掘关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则,Apriori 算法采用了逐层搜索的迭代的方法,算法简单明了,没有复杂的理论推导,也易于实现。
由于Apriori算法的特性,十分适合中药处方、膏方、方剂的挖掘,甚至于穴位的挖掘。
本文帮助客户得出不同处方的药物组合和频率,挖掘出药方内在的规律。
中药处方数据
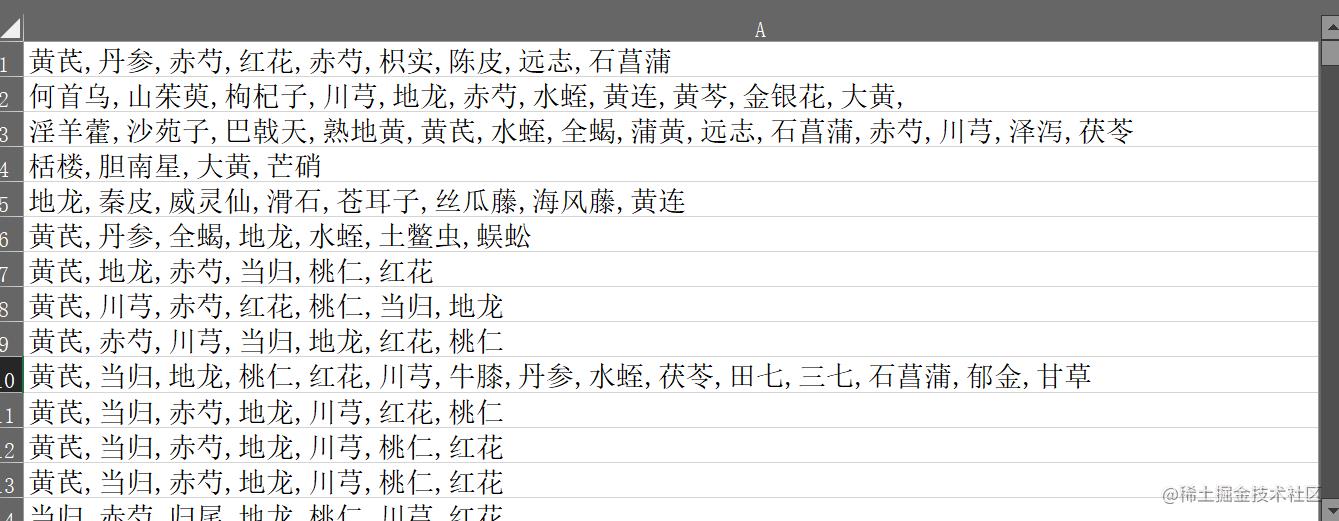
读取数据
a_df3=read.xlsx("挖掘用.xlsx",startRow=0, colNames = F)

转换数据结构
a_list=list(0)
for(i in 1:nrow(a_df3))
##删除事务中的重复项目
a_list[[i]]= unique(strsplit(a_df3[i,],",")[[1]])

将数据转换成事务类型
trans2 <- as(a_list, "tran
查看每个商品的出现频率

可以看到每个物品出现的频率,从而判断哪些物品的支持度较高。
关联规则挖掘
药对挖掘
at(dat1,parameter=list(support=0.3,minlen=2,maxle

得到频繁规则挖掘
inspect(frequent

查看求得的频繁项集
spect(sort(frequentsets,by="suppo
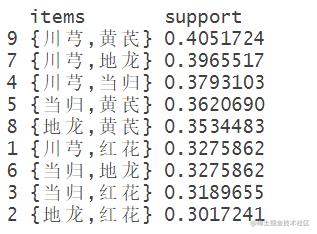
根据支持度对求得的频繁项集排序并查看(等价于inspect(sort(frequentsets)[1:10])。
建立模型
apriori(dat1,parame

设置支持度为0.01,置信度为0.3
summary(rules)#查看规则

查看部分规则
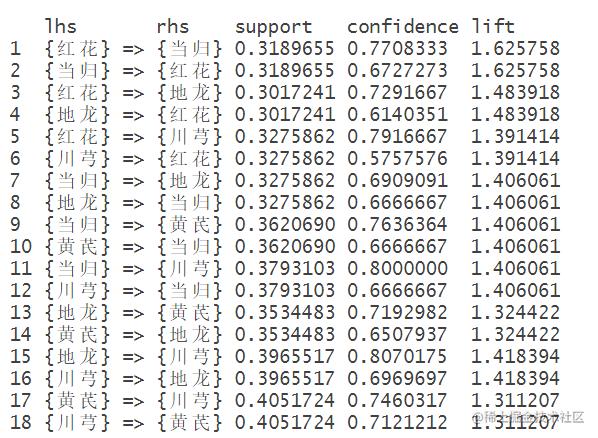
查看置信度 支持度和提升度

可视化
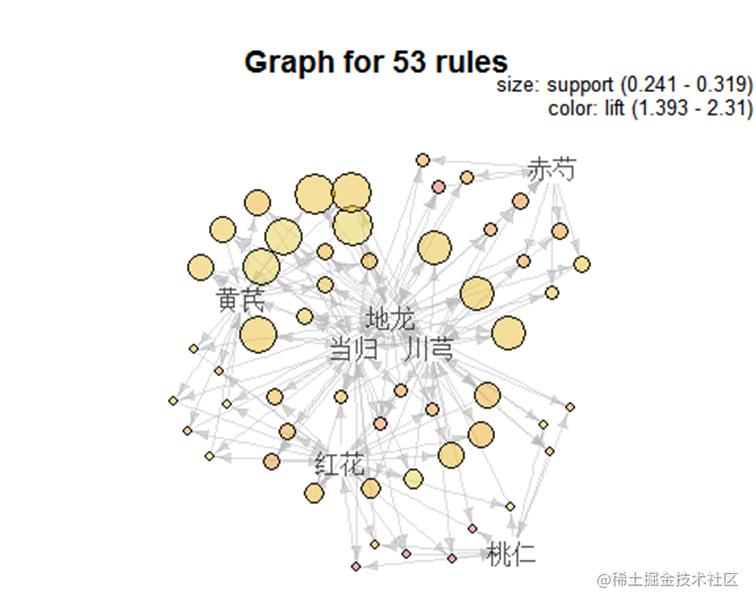
绘制不同规则图形来表示支持度,置信度和提升度。

通过该图可以看到规则前项和规则后项分别有哪些物品 以及每个物品的支持度大小,支持度越大则圆圈越大。

ules, method = NULL,
measure = "support", shading = "lift", int

从该图可以看到支持度和置信度的关系,置信度越高提升度也越高。
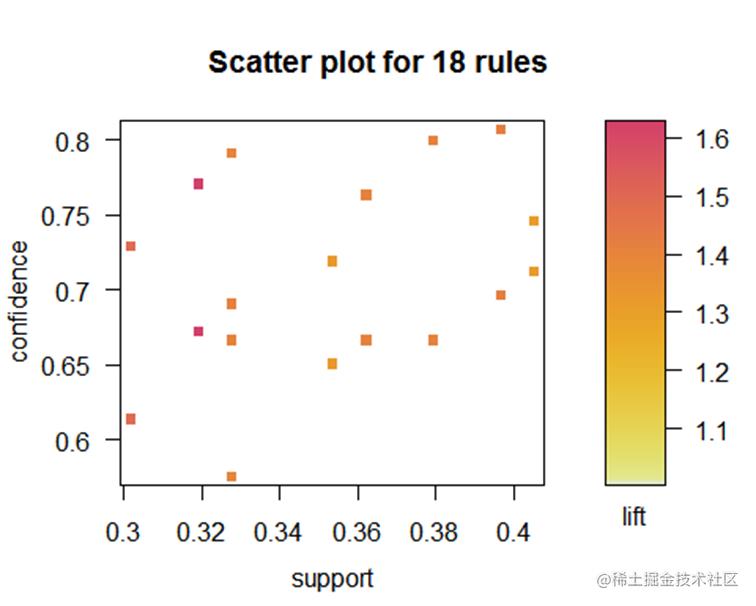

从该图可以看到支持度和置信度的关系,提升度越高置信度也越高。
ules, method="matrix3D", measure="lift


从上图可以看到不同物品之间的关联关系,图中的点越大说明该物品的支持度越高,颜色越深说明该物品的提升度越高。
plot(rules, method="doubledecker" )
查看最高的支持度样本规则
ules::inspect(head(rules

查看最高置信度样本规则
sort(rules, by="confidenc
nspect(head(rules
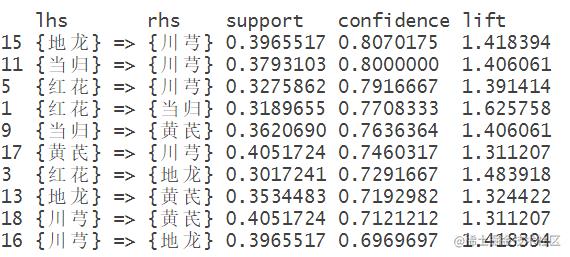
sort(rules, by="lift

得到有价值规则子集
rules,subset=confidence>0.3 & support>0.2 & lift>=1
summary(x)

按照支持度排序
sort(x,by="support

按照置信度排序
inspect(sort(x,by="confide

对有价值的x集合进行数据可视化。
method="grouped")

组合挖掘
at(dat1,parameter=list(support=0.22,minlen=3,maxle
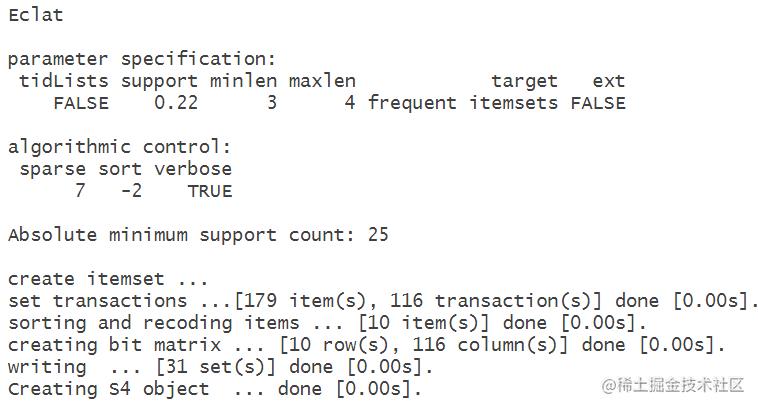
得到频繁规则挖掘
nspect(frequents

察看求得的频繁项集
nspect(sort(frequentsets,by="sup

根据支持度对求得的频繁项集排序并查看(等价于inspect(sort(frequentsets)[1:10])
建立模型
apriori(dat1,parameter=list(support=0.24

设置支持度为0.01,置信度为0.3。
summary(rules)#查看规则

查看部分规则

查看置信度 支持度和提升度

可视化






从该图可以看到支持度和置信度的关系,提升度越高置信度也越高。


查看最高的支持度样本规则

查看最高置信度样本规则

查看最高提升度样本规则

confidence>0.3 & support>0.3 & lift>=1) #得到有价值规则子集
summary(x)

aspect(sort(x,by="support")) #按照支持度排序
## lhs rhs support confidence lift
## 45 川芎,黄芪 => 地龙 0.3189655 0.7872340 1.602090
## 43 地龙,黄芪 => 川芎 0.3189655 0.9024390 1.586105
## 44 川芎,地龙 => 黄芪 0.3189655 0.8043478 1.481021
## 42 川芎,黄芪 => 当归 0.3103448 0.7659574 1.615474
## 41 川芎,当归 => 黄芪 0.3103448 0.8181818 1.506494
## 40 当归,黄芪 => 川芎 0.3103448 0.8571429 1.506494
## 37 当归,地龙 => 川芎 0.3017241 0.9210526 1.618820
## 38 川芎,当归 => 地龙 0.3017241 0.7954545 1.618820
## 39 川芎,地龙 => 当归 0.3017241 0.7608696 1.604743
pect(sort(x,by="confidence")) #按照置信度排序
## lhs rhs support confidence lift
## 37 当归,地龙 => 川芎 0.3017241 0.9210526 1.618820
## 43 地龙,黄芪 => 川芎 0.3189655 0.9024390 1.586105
## 40 当归,黄芪 => 川芎 0.3103448 0.8571429 1.506494
## 41 川芎,当归 => 黄芪 0.3103448 0.8181818 1.506494
## 44 川芎,地龙 => 黄芪 0.3189655 0.8043478 1.481021
## 38 川芎,当归 => 地龙 0.3017241 0.7954545 1.618820
## 45 川芎,黄芪 => 地龙 0.3189655 0.7872340 1.602090
## 42 川芎,黄芪 => 当归 0.3103448 0.7659574 1.615474
## 39 川芎,地龙 => 当归 0.3017241 0.7608696 1.604743
对有价值的x集合进行数据可视化


 最受欢迎的见解
最受欢迎的见解
6.采用SPSS Modeler的Web复杂网络对所有腧穴进行分析
7.R语言如何在生存分析与COX回归中计算IDI,NRI指标
多维关联规则挖掘算法r语言能实现吗
参考技术A 一下自己学习关联规则经典算法Apriori的笔记。1、概述
Apriori算法是用一种称为逐层搜索的迭代方法,从项集长度k=1开始,选出频繁的k=1项集,根据先验性质:频繁项集的子集一定是频繁的(逆否命题:非频繁项集的超集一定是非频繁的,通俗的说就是某件事发生的概率很低,比这件事发生条件更严苛的事情发生的概率会更低),筛选k=2项集中的频繁项集,以此迭代k=3...。每迭代一次都要完整的扫描一次数据库。
2、关联规则三度:
支持度:占比
置信度:条件概率
提升度:相关性
3、R语言示例代码如下:(小众语言的辛酸:选项里没有。。)
[plain] view plain copy
library(arules)
#从rattle包中读入数据
dvdtrans <- read.csv(system.file("csv", "dvdtrans.csv",package="rattle"))
str(dvdtrans)
#将数据转化为合适的格式
data <- as(split(dvdtrans$Item,dvdtrans$ID),"transactions")
data
#用 apriori命令生成频繁项集,设其支持度为0.5,置信度为0.8
rules <- apriori(data, parameter=list(support=0.5,confidence=0.8,minlen = 2))
#用inspect命令查看提取规则
inspect(rules)
常用数据形式有data.frame格式和list格式,前者即A项集为一列B项集为另一列,后者为A和B放在同一个购物篮中。
去除冗余规则以及提取子规则代码如下:
[plain] view plain copy
redundant.rm <- function(rule,by="lift")
#rule:需要进行简化的规则
#by:在清除的时候根据那个变量来选择,
#可能取值为"support","lift","confidence"
a <- sort(rule,by=by)
m<- is.subset(a,a,proper=TRUE)
m[lower.tri(m, diag=TRUE)] <- NA
r <- colSums(m, na.rm=TRUE) >= 1
finall.rules <- a[!r]
return(finall.rules)
rules <- redundant.rm(rules)
rules.sub <- subset(rules, subset = lhs %in% "筛选项集名称" & lift > 1)
以上是关于R语言Apriori算法关联规则对中药用药复方配伍规律药方挖掘可视化的主要内容,如果未能解决你的问题,请参考以下文章