用Puppeteer Docker镜像给网页截图
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Puppeteer Docker镜像给网页截图相关的知识,希望对你有一定的参考价值。
参考技术A 原来镜像不支持中文, Fork之后添加中文支持(已提交PR给原仓库)并构建了新的镜像, 直接拉取即可:语法:
<tool> <url> <width>x<height> [<delay_in_ms>]
https://hub.docker.com/r/alekzonder/puppeteer/
[1] Docker - 中国官方镜像加速
用puppeteer爬取网页数据初体验
用puppeteer爬取网页数据
业务需求,页面需要显示很多链接列表,像这样的。
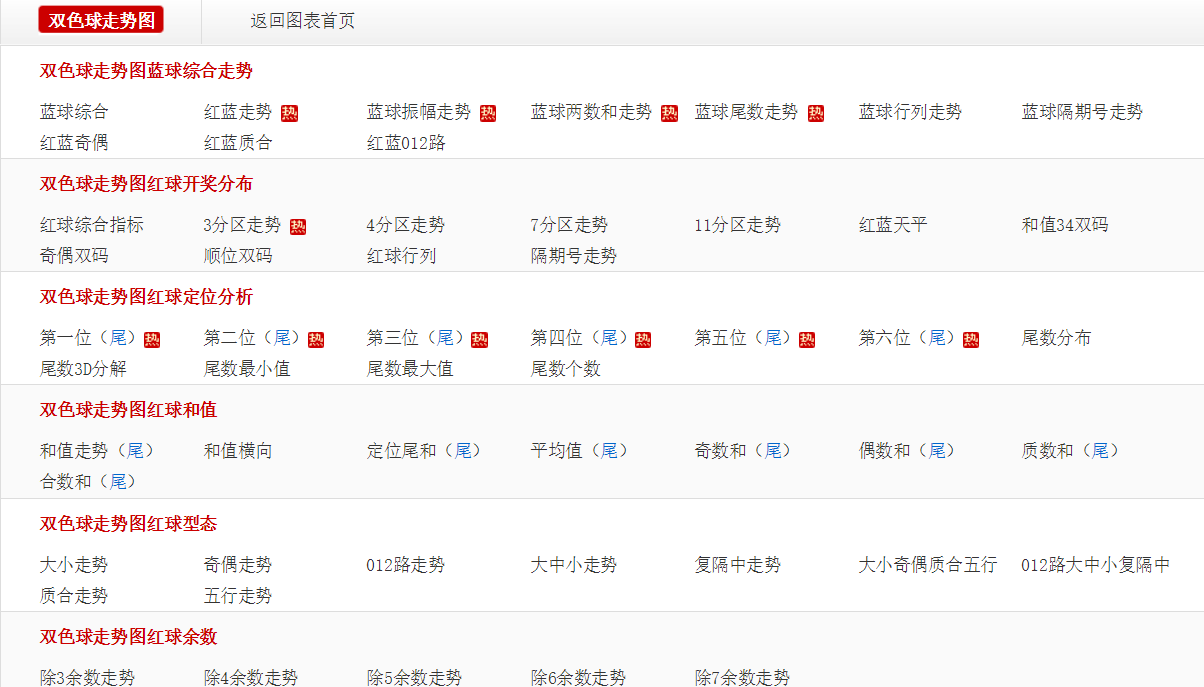
我问项目经理要字典表,他笑咪咪地拍着我的肩膀说:“这边有点忙,要不按照这个自己抄一下吧”。
emmm…
我看了一下,数据大概有七八百条,一个一个录入,那不得搞到地老天荒、海枯石烂。
心口一股燥热,差点就要口吐莲花,舌吐芬芳了…
转念一想,做人要儒雅随和,念在平时没少蹭吃蹭喝的份上,咱先弄一下吧。
可是怎么弄呢?
一个一个输入是不可能的,我们需要录入每个组的标题、标题下的名称和链接,这是需要看网页源码,效率太低。
拦截接口也不行,网页是 PHP 写的,后端渲染,前端看不到接口。
那就只有一种方法,爬取网页数据。想到之前了解过的pupeteernodejs 库可以爬取网页数据,要不咱先试一下?
说干就干。
准备工作
安装依赖,puppeteer 下载完成后会自动下载 me
1 | npm install puppeteer |
代码实现
1 | const puppeteer = require("puppeteer"); |
爬取结果
大功告成.
源码地址
https://github.com/superman12312/learning/tree/master/NODEJS/puppeteer-demo
以上是关于用Puppeteer Docker镜像给网页截图的主要内容,如果未能解决你的问题,请参考以下文章
Puppeteer + Nodejs 通用全屏网页截图方案常用参数实现
有了 serverless,前端也可以快速开发一个 Puppeteer 网页截图服务