python3 偏最小二乘法实现
Posted GXTon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3 偏最小二乘法实现相关的知识,希望对你有一定的参考价值。
python3的sklearn库中有偏最小二乘法。
可以参见下面的库说明:http://scikit-learn.org/stable/modules/generated/sklearn.cross_decomposition.PLSRegression.html
对下面的程序进行改写,可以在python3中运行了
程序来源:来源:https://blog.csdn.net/li_huifei/article/details/78467689 经过修改可以在python3上运行
我的数据A.csv

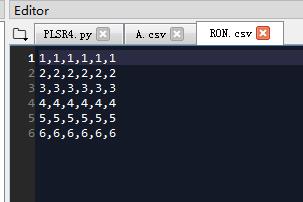
我的数据RON.csv
# -*- coding: utf-8 -*- #看来这个程序适合的是python2版本的。来源:https://blog.csdn.net/li_huifei/article/details/78467689 #这个目前也可以用了,主要还是在第60行的数据转换,,,不太清楚怎样去做装换。主要是因为数据类型不清楚,所以用了最笨的方法,不知道结果正不正确。????【这个是错误的】 #PLSR3经过摸索,第68行,还是因为数据结构类型不对,之后把array类型的数组转换成了list,,,这样方便在外面套一个[],,之后运行没有问题,但是结果的正确与否,还有待验证。 #导入库的部分 import csv from sklearn import preprocessing from sklearn.cross_validation import train_test_split from sklearn.decomposition import RandomizedPCA from sklearn.cross_decomposition import PLSRegression #偏最小二乘法的实现, 在这里是可以跳进 PLSRegression 里面的 import numpy as np import math import matplotlib.pyplot as plt #导入数据的部分 A = np.loadtxt(\'A.csv\',delimiter=\',\') #读入数据 这里的A就是y的矩阵 #读了这么多的数据???哪个是x,,哪个又是y呢??? print (A.shape) RON = np.loadtxt(\'RON.csv\',delimiter=\',\') #这里的RON就是x的矩阵 print (RON.shape) #暂且在这里设置全局变量吧。 x_train_st_i=[] #定义全局函数的部分。 def error(y_predict,y_test): #定义计算误差平方和函数,,,传入的是估算出的值,和测试值,,这里仅仅是用来定义的,方便后面的调用。 errs = [] for i in range(len(y_predict)): e = (y_predict[i]-y_test[i])**2 errs.append(e) return sum(errs) #偏最小二乘法的实现部分。 x_train, x_test, y_train, y_test = train_test_split(RON,A,test_size=0.5) #划分训练集测试集,,,这个是一个库函数?? ,,,,这里能够看出是A和RON进行建模的。 x_train_st = preprocessing.scale(x_train) #数据标准化,这个是内置函数 y_train_st = preprocessing.scale(y_train) #数据标准化,,这一句是我仿照上面的一句改写的。 n_components = 0 #这个应该是保存主成分的个数。 while n_components<x_train_st.shape[1]: n_components=n_components+1 #在第一遍的时候n_components是1,第二遍循环的时候是2,,,第n遍循环是n,,最大是x的列数,也就是特征的个数, pls2 = PLSRegression(n_components=n_components) #计算SS (SS这个是全建模 , PRESS是减去一个进行建模,,,,在python里建模很简单,设置好参数,调用一下函数就能建模了) #这个不是偏最小二乘法吗???,,这里是循环计算主成分的个数,直到达到满意的精度。 pls2.fit(x_train_st, y_train) #fit也是一个函数,,,两个参数,第一个参数是训练集,第二个参数是目标。 y_predict0 = pls2.predict(x_train_st) #predict也是一个内置的函数,,,,这个是不是用建好的模型去做预测,,,,把参数训练集输入进去,得到的是预测的值。 SS = error(y_predict0,y_train) #这里是预测的值和真正的值之间的误差大小。 y_predict1 = [] #这是创建了一个新的变量。根据名字的意思,根据模型得到的y的预测值,实际上这个模型是留一法建立的模型。 for i in range(x_train_st.shape[0]): #计算PRESS,,,,这个是x_train_st的行数 n_components1 = n_components #但是我不明白,为什么这里还要加1,主成分不可能是0个吧,所以就从1开始了。 x_train_st1 = np.delete(x_train_st,i,0) #这里的0是行,1是列,,这个应该是删除第i行,,,这里是标准化的数组。留一法的实现 y_train_st1 = np.delete(y_train,i,0) #这个也是删除第i行,这里都是经过标准化的(但这个x是经过标准化的,y却没有用标准化的数据)。,,这个没有用到过,是不是这里写错了?? pls2 = PLSRegression(n_components=n_components1) #偏最小二乘法参数的设置,,,这里面一般有5个参数,,但这里只传入了主成分的个数。 #参数1:n_components:int ,(default 2) ,,要保留的主成分数量,默认为2 #参数2:scale:boolean,(default True),,是否归一化数据,默认为是 #参数3:max_iter: an integer,(default 500),,使用NIPALS时的最大迭代次数 #参数4:tol: non-negative real(default 1e-06),,迭代截止条件 #参数5:copy: Boolean,(default True),, pls2.fit(x_train_st1, y_train_st1) #这里是根据前面设置好的参数建模过程,这里的建模过程是不是不太对(这里x是归一化的,y并没有用归一化的),应该都是用归一化的才行呀。??? #这里主要是进行了数据格式的转换,因为做预测要传进的是矩阵【格式很重要】 x_train_st_i=[] #用之前要进行清空,这个很重要。用一个参数之前要进行清空。 x_train_st_list=x_train_st[i].tolist() x_train_st_i.append(x_train_st_list) print (\'the x_train_st is \',x_train_st_i) #输出一下变量,查看格式是否正确,因为下面的predict函数需要用[[1,1,1,1,1,1]] 这种格式的数据 y_predict11 = pls2.predict(x_train_st_i) #预测函数,给定之前留一法没有用到的样本,进行建模,预测对应的y值。????可是已经删除了不是吗??? ZHE这句出了一点问题????就是数据格式有问题,需要在最外面在加一个[] y_predict1.append(y_predict11) #把所有的y值组成一个数组,便于计算误差。,这个也是y的预测值,用它来算出另一个误差。 PRESS = error(y_predict1,y_train) #可能错误:https://blog.csdn.net/little_bobo/article/details/78861578 Qh = 1-float(PRESS/SS) if Qh<0.0985: #判断精度 模型达到精度要求,可以停止主成分的提取了。 plt.figure(1) plt.scatter(y_predict0,y_train) #画了一个图,这个图是预测值,与测量值的图??? plt.figure(2) plt.scatter(y_predict1,y_train) print (\'the Qh is \',Qh) print (\'the PRESS is\',PRESS) print (\'the SS is\',SS) break #达到了上面的精度,就可以停止while的迭代了 #这下面就没有看懂了。 print (\'n_components is \',n_components+1) #这里为什么要加1???,,,难道因为计数是从0开始的?? SECs = [] errors = [] e = 100 for i in range(10): #循环测试 #print i x_train, x_test, y_train, y_test = train_test_split( RON,A, test_size=0.5) #划分训练集与测试集,这个是一个内置的函数。 x_test_st = preprocessing.scale(x_test) #数据标准化 y_predict = pls2.predict(x_test_st) #进行预测 SECs.append(np.sqrt(error(y_predict,y_test)/(y_test.shape[0]-1))) errors.append(float(error(y_predict,y_test))) if SECs[-1]<e: y_predict_min = y_predict y_test_min = y_test print (\'the prediced value is \' ,y_predict.T) #画图,打印结果 print (\'the true value is\',y_test) print (\'the mean error is\',float(np.mean(errors))) print ("the mean SEC is ",float(np.mean(SECs))) plt.figure(3) plt.scatter(y_predict_min,y_test_min)
摘自:
以上是关于python3 偏最小二乘法实现的主要内容,如果未能解决你的问题,请参考以下文章