PYTHON开发必备技能
Posted zmyting
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PYTHON开发必备技能相关的知识,希望对你有一定的参考价值。
第7名:Json&Pickle(序列化与反序列化模块)
参考Java网址:http://blog.csdn.net/a2011480169/article/details/51771539
绪言:Python中eval内置函数的作用:
eval()是Python内置的工具函数,其功能是将字符串对象转化为有效的表达式参与求值运算,并返回计算结果。
通过eval()可以在字符串对象和字典、列表、元组对象之间进行相互转换。
代码示例:
str_info1 = "(‘python‘,‘Java‘,‘Scala‘)"
print(str_info1,type(str_info1))
print(eval(str_info1),type(eval(str_info1)))
str_info2 = "[‘python‘,‘Java‘,‘Scala‘]"
print(str_info2,type(str_info2))
print(eval(str_info2),type(eval(str_info2)))
str_info3 = ‘{"name":"python","price":2000}‘
print(str_info3,type(str_info3))
print(eval(str_info3),type(eval(str_info3)))
运行结果:
(‘python‘,‘Java‘,‘Scala‘) <class ‘str‘>
(‘python‘, ‘Java‘, ‘Scala‘) <class ‘tuple‘>
[‘python‘,‘Java‘,‘Scala‘] <class ‘str‘>
[‘python‘, ‘Java‘, ‘Scala‘] <class ‘list‘>
{"name":"python","price":2000} <class ‘str‘>
{‘name‘: ‘python‘, ‘price‘: 2000} <class ‘dict‘>
Process finished with exit code 0
eval()内置函数的缺陷:
eval()就是用来提取字符串中的数据类型的,但是eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
代码示例:
import json x="[null,true,false,1]" print(eval(x)) #报错,无法解析null类型,而json就可以 print(json.loads(x))
上面这个例子这样改就可以了:
import json x = "[None,True,False,1]" print(eval(x))
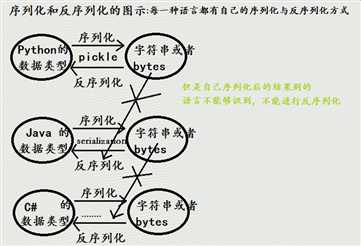
用于序列化的两个模块:
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
Json提供了一种通用的序列化与反序列化方式:
序列化和反序列化的概念:(重要)
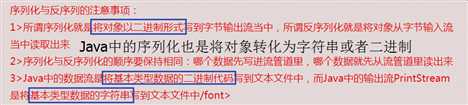
将内存中的数据类型转化成字符串或者bytes类型(二进制形式),叫做序列化(json、pickle、serialization);序列化之后,就可以把序列
化后的内容写入磁盘,或者通过网络传输到别的机器上。将字符串或者bytes类型(二进制形式)转化成内存中的数据类型,叫做反序列化。
在Python当中,自己的序列化方式与反序列化方式为pickle,代码如下所示:
代码示例1:
import pickle
user_info = {
‘name‘:‘angele‘,
‘age‘:35,
‘city‘:‘beijing‘,
}
print(user_info,type(user_info))
#python特有的序列化方式:pickle,将Python中的数据类型转化为bytes
p_bytes = pickle.dumps(user_info)
print(p_bytes,type(p_bytes))
#python特有的反序列化方式:pickle,将bytes转化为Python中的数据类型
user_info = pickle.loads(p_bytes)
print(user_info)
运行结果:
{‘name‘: ‘angele‘, ‘age‘: 35, ‘city‘: ‘beijing‘} <class ‘dict‘>
b‘x80x03}qx00(Xx04x00x00x00nameqx01Xx06x00x00x00angeleqx02Xx03x00x00x00ageqx03K#Xx04x00x00x00cityqx04Xx07x00x00x00beijingqx05u.‘ <class ‘bytes‘>
{‘name‘: ‘angele‘, ‘age‘: 35, ‘city‘: ‘beijing‘}
代码示例2:将Python中序列化后的数据写入到磁盘当中,并反序列化读取(推荐的方式)
dumps与loads的组合使用
import pickle
user_info = {
‘name‘:‘angele‘,
‘age‘:35,
‘city‘:‘beijing‘,
}
with open(‘example.pkl‘,‘wb‘) as fw:
print(pickle.dumps(user_info))
fw.write(pickle.dumps(user_info))
with open(‘example.pkl‘,‘rb‘) as fr:
user_info = pickle.loads(fr.read())
print(user_info,type(user_info))
运行结果:
b‘x80x03}qx00(Xx04x00x00x00nameqx01Xx06x00x00x00angeleqx02Xx03x00x00x00ageqx03K#Xx04x00x00x00cityqx04Xx07x00x00x00beijingqx05u.‘
{‘name‘: ‘angele‘, ‘age‘: 35, ‘city‘: ‘beijing‘} <class ‘dict‘>
Process finished with exit code 0
代码示例3:将Python中序列化后的数据写入到磁盘当中,并反序列化读取(利用文件句柄,不推荐的方式)
dump与load的组合使用
import pickle
user_info = {
‘name‘:‘angele‘,
‘age‘:35,
‘city‘:‘beijing‘,
}
with open(‘example.pkl‘,‘wb‘) as fw:
pickle.dump(user_info,fw)
with open(‘example.pkl‘,‘rb‘) as fr:
print(pickle.load(fr))
"""
{‘name‘: ‘angele‘, ‘age‘: 35, ‘city‘: ‘beijing‘}
Process finished with exit code 0
"""
上面讲的方式都是Python特有的序列化与反序列的方式,接下来讲一种通用的序列化与反序列的方式。
Json的序列化与反序列化方式:
代码示例1:
import json
user_info = {
‘name‘:‘angele‘,
‘age‘:35,
‘city‘:‘beijing‘,
}
#Json序列化:将Python的数据类型转化为字符串
str_js = json.dumps(user_info)
print(str_js,type(str_js))
#Json反序列化:将字符串转化为python中的数据类型
user_info = json.loads(str_js)
print(user_info,type(user_info))
运行结果:
{"city": "beijing", "age": 35, "name": "angele"} <class ‘str‘>
{‘city‘: ‘beijing‘, ‘age‘: 35, ‘name‘: ‘angele‘} <class ‘dict‘>
Process finished with exit code 0
代码示例2:将Python中序列化后的数据写入到磁盘当中,并反序列化读取(推荐这种通用的方式)
dumps和loads
import json
user_info = {
‘name‘:‘angele‘,
‘age‘:35,
‘city‘:‘beijing‘,
}
#序列化
with open(‘example.json‘,encoding=‘utf-8‘,mode=‘w‘) as fw:
user_info = json.dumps(user_info)
print(user_info,type(user_info))
fw.write(user_info)
#反序列化
with open(‘example.json‘,encoding=‘utf-8‘,mode=‘r‘) as fr:
user_info = json.loads(fr.read())
print(user_info,type(user_info))
运行结果:
{"name": "angele", "age": 35, "city": "beijing"} <class ‘str‘>
{‘name‘: ‘angele‘, ‘age‘: 35, ‘city‘: ‘beijing‘} <class ‘dict‘>
Process finished with exit code 0
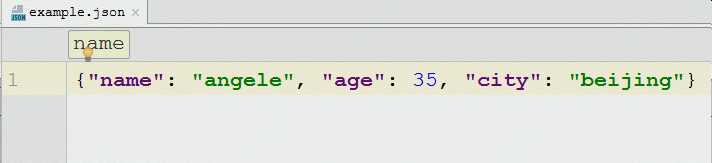
example文件中的数据:
代码示例3:将Python中序列化后的数据写入到磁盘当中,并反序列化读取(利用文件句柄,不推荐这种通用的方式)
dump和load的组合
import json
user_info = {
‘name‘:‘angele‘,
‘age‘:35,
‘city‘:‘beijing‘,
}
#序列化
with open(‘example.json‘,encoding=‘utf-8‘,mode=‘w‘) as fw:
json.dump(user_info,fw)
#反序列化
with open(‘example.json‘,encoding=‘utf-8‘,mode=‘r‘) as fr:
print(json.load(fr))
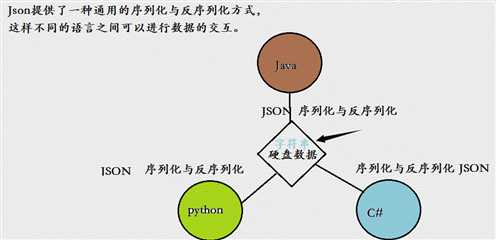
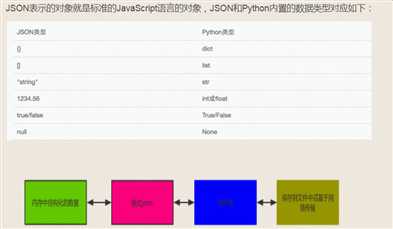
JSON的概念:
JSON是一种轻量级的数据交换格式,本质就是一串字符串.
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示
出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。
JSON不仅是标准格式,而且比XML更快,而且可以直接在Web页面中读取,非常方便。Json最广泛的应用是作为AJAX中web服务器和客户
端的通讯的数据格式。
Json与pickle的异同点:
第一:Json在写入和读取数据时,是以字符串类型进行操作;pickle在写入和读取数据时,则是以二进制的格式进行操作。
第二:Json只支持一些简单的通用的数据类型,如字符串、列表、字典、元祖、集合等;pickle支持简单的数据类型,也支持复杂的数据
类型,如函数、类等。即pickle可以支持序列化python中所有的数据类型。
第三:Json可以跨语言进行转换,pickle只能在Python中使用。
第四:Json是一种通用的序列化与反序列化的方式,而pickle是Python自己独有的序列化与反序列化的方式。
注意:如果向文件当中写数据,只能写两种格式:
第一:文本字符串(数字都必须要先变成字符串)
第二:bytes b‘x80x03}qx00(Xx02x00x00x00i‘类型。
疑问:

实战:
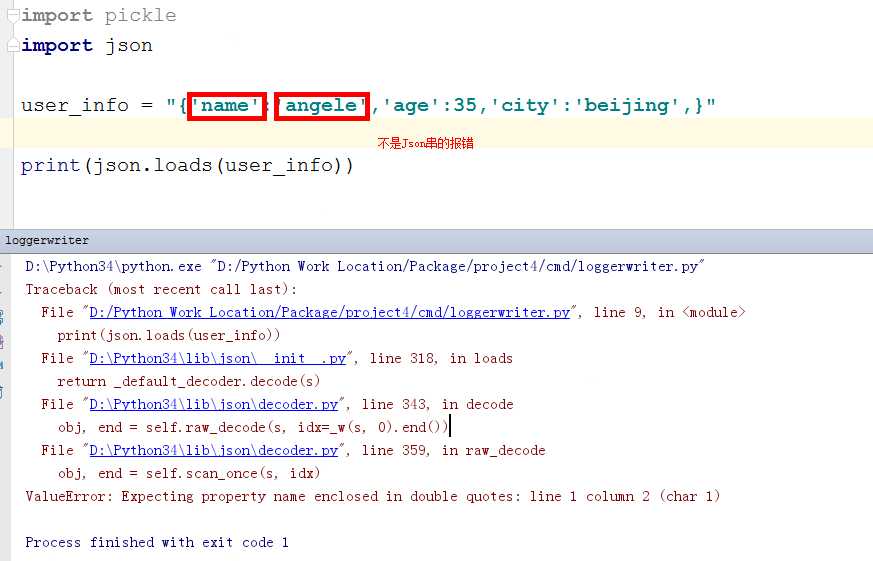
Json本质就是Json串,下面如何理解?
str_info = "python" print(json.loads(str_info))
ValueError: Expecting value: line 1 column 1 (char 0)
第8名:hashlib加密模块
这个算法我在工作当中在Django的时候用到过,在校验文件的时候也用到过。
Python中hashlib算法的作用:
print(time.clock())
Python的hashlib算法提供了常见的摘要算法,如md5、sha1等等,摘要算法又称哈希算法、散列算法。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被别人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困
难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
Python中hashlib模块使用的方法:
第一:创建一个哈希对象h = hashlib.md5()
第二:将字节对象arg填充到哈希对象中,arg通常为要加密的字符串
h.update(arg)
第三:调用digest() 或 hexdigest()方法来获取摘要(加密结果)
h.hexdigest()
hashlib校验文件的原理:
如果同一个hash对象重复调用update()方法,则m.update(a); m.update(b) 等效于 m.update(a+b)
示例程序1:
import hashlib """ python中hashlib算法的基本使用方法: """ #第一:创建一个哈希对象、h=hashlib.md5() h = hashlib.md5() #第二:将字节对象arg填充到哈希对象当中,arg通常为要加密的字符串 h.update(‘angela‘.encode(‘utf-8‘)) #第三:调用hexdigest()方法来获取摘要(加密结果) print(h.hexdigest())
运行结果:
36388794be2cf5f298978498ff3c64a2 Process finished with exit code 0
示例程序2:(Django中用户名和密码的校验)
import hashlib
"""
python中的hashlib算法在Django中的类似应用
"""
user_name = input(‘请输入注册的用户名:‘)
pass_word = input(‘请输入注册的密码:‘)
print(‘�33[42m您注册的用户名是:%s,密码是:%s�33[0m‘%(user_name,pass_word))
m1 = hashlib.md5()
m1.update(pass_word.encode(‘utf-8‘))
pass_word_md5 = m1.hexdigest()
print(pass_word_md5)
#将用户注册后的信息写到数据库当中
with open(‘db.txt‘,encoding=‘utf-8‘,mode=‘w‘) as fw:
fw.write(‘%s|%s‘%(user_name,pass_word_md5))
#用户二次登陆进行用户名和密码校验
username = input(‘请输入注册的用户名:‘)
password = input(‘请输入注册的密码:‘)
m2 = hashlib.md5()
m2.update(password.encode(‘utf-8‘))
password_md5 = m2.hexdigest()
with open(‘db.txt‘,encoding=‘utf-8‘,mode=‘r‘) as fr:
user,pwd = fr.read().split(‘|‘)
print(user,pwd)
if user == username and pwd == password_md5:
print(‘登陆成功..‘)
else:
print(‘登陆失败..‘)
示例程序3:(****)
import hashlib """ python中的hashlib算法在文本校验中的用法:实际上就是校验文本字符串的内容 """ m1 = hashlib.md5() m1.update(‘angela‘.encode(‘utf-8‘)) m1.update(‘helloyou‘.encode(‘utf-8‘)) print(m1.hexdigest()) m2 = hashlib.md5() m2.update(‘angelahelloyou‘.encode(‘utf-8‘)) print(m2.hexdigest())
运行结果:
eb4ab8ec5815365e9fc88dfa444d9796 eb4ab8ec5815365e9fc88dfa444d9796 Process finished with exit code 0
示例程序4:(文本文件的校验)
import hashlib
"""
python中的hashlib算法在文本校验中的用法:实际上就是校验文本字符串的内容
"""
m = hashlib.md5()
with open(‘db.txt‘,encoding=‘utf-8‘,mode=‘r‘) as fr:
data = fr.read()
m.update(data.encode(‘utf-8‘))
print(m.hexdigest())
print(‘****************‘)
#下面的方式每次在内存当中只存在一个数值:这种方式是我们推荐的
m2 = hashlib.md5()
with open(‘db.txt‘,encoding=‘utf-8‘,mode=‘r‘) as fr:
for line in fr:
m2.update(line.encode(‘utf-8‘))
print(m2.hexdigest())
运行结果:
3232ea30e0a71e5f5c3e83676f64c9eb **************** 3232ea30e0a71e5f5c3e83676f64c9eb Process finished with exit code 0
示例程序5:获取标志Id
import hashlib
import time
def get_id():
h = hashlib.md5()
h.update(str(time.clock()).encode(‘utf-8‘))
return h.hexdigest()
print(get_id())
print(get_id())
print(get_id())
print(get_id())
运行结果:
85b8a467159e14ec4b2d16bff39ed199 5b0526b768b41eb7b4d1a8e741b1dae5 42999cb93fd523a787960fec38530026 ce1322698e3badb958538b1100c8d550 7b7bc63304b72fa74f81d01e8317c66d Process finished with exit code 0
以上是关于PYTHON开发必备技能的主要内容,如果未能解决你的问题,请参考以下文章