2018.8.20 Python之路---常用模块
Posted 中杯可乐不加冰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2018.8.20 Python之路---常用模块相关的知识,希望对你有一定的参考价值。
一、re模块
查找:
re.findall(‘正则表达式’,‘字符串’)
匹配所有符合正则表达式的内容,形成一个列表,每一项都是列表中的一个元素。
ret = re.findall(\'\\d+\',\'sjkhk172按实际花费928\') # 正则表达式,带匹配的字符串,flag
ret = re.findall(\'\\d\',\'sjkhk172按实际花费928\') # 正则表达式,带匹配的字符串,flag
print(ret)
re.search(‘正则表达式’,‘字符串’)
只匹配从左到右的第一个,得到的不是直接的结果,而是一个变量,通过这个变量的group方法来获取结果
如果没有匹配到,会返回None,使用group会报错
ret = re.search(\'\\d+\',\'sjkhk172按实际花费928\')
print(ret) # 内存地址,这是一个正则匹配的结果
print(ret.group()) # 通过ret.group()获取真正的结果
ret = re.search(\'\\d+\',\'sjkhk172按实际花费928\')
if ret : # 内存地址,这是一个正则匹配的结果
print(ret.group()) # 通过ret.group()获取真正的结果
re.match(\'正则表达式\',‘字符串’)
从头开始匹配,相当于search中的正则表达式加上一个^
ret = re.match(\'\\d+$\',\'172sjkhk按实际花费928\')
print(ret)
字符串的扩展处理:替换、切割
split:切割
s = \'alex83taibai40egon25\'
ret = re.split(\'\\d+\',s)
print(ret) #[\'alex\', \'taibai\', \'egon\', \'\']
sub:替换
ret = re.sub(\'\\d+\',\'H\',\'alex83taibai40egon25\')
print(ret) #alexHtaibaiHegonH
ret = re.sub(\'\\d+\',\'H\',\'alex83taibai40egon25\',1)
print(ret) #alexHtaibai40egon25
subn:替换。返回一个元组,第二个元素是替换的次数。
ret = re.subn(\'\\d+\',\'H\',\'alex83taibai40egon25\')
print(ret)
#(\'alexHtaibaiHegonH\', 3)
re模块的进阶:时间/空间
compile:编译正则表达式,编译成字节码,节省使用正则表达式解决问题的时间。
ret = re.compile(\'\\d+\') # 已经完成编译了
print(ret)
res = ret.findall(\'alex83taibai40egon25\')
print(res)
res = ret.search(\'sjkhk172按实际花费928\')
print(res.group())
finditer:返回一个迭代器,所有匹配到的内容需要迭代取到,迭代取到的每一个结果都需要group取具体值,节省内存空间。
ret = re.finditer(\'\\d+\',\'alex83taibai40egon25\')
for i in ret:
print(i.group())
分组:
1.给不止一个字符的整体做量词约束的时候 www(\\.[\\w]+)+ www.baidu.com
2.优先显示,当要匹配的内容和不想匹配的内容混在一起的时候,
就匹配出所有内容,但是对实际需要的内容进行分组
3.分组和re模块中的方法 :
findall : 分组优先显示 取消(?:正则)
search :
可以通过.group(index)来取分组中的内容
可以通过.group(name)来取分组中的内容
正则 (?P<name>正则)
使用这个分组 ?P=name
split : 会保留分组内的内容到切割的结果中
ret = re.split(\'\\d+\',\'alex83taibai40egon25\')
print(ret)
#[\'alex\', \'taibai\', \'egon\', \'\']
ret = re.split(\'(\\d+)\',\'alex83taibai40egon25aa\')
print(ret)
#[\'alex\', \'83\', \'taibai\', \'40\', \'egon\', \'25\', \'aa\']
二、random模块
取随机小数:数学计算
print(random.random()) # 取0-1之间的小数
print(random.uniform(1,2)) # 取1-2之间的小数
取随机整数 : 彩票 抽奖
print(random.randint(1,2)) # [1,2]
print(random.randrange(1,2)) # [1,2)
print(random.randrange(1,200,2)) # [1,200) 每两个取一个
从一个列表中随机取值:抽奖
l = [\'a\',\'b\',(1,2),123]
print(random.choice(l))
print(random.sample(l,2))
打乱一个列表的顺序,在原列表的基础上直接进行修改,节省空间
洗牌
l = [\'a\',\'b\',(1,2),123]
random.shuffle(l)
print(l) #[(1, 2), \'a\', 123, \'b\']
验证码:
4位数字验证码
6位数字验证码
6位数字+字母验证码
def code(n = 6,alpha = True):
s = \'\'
for i in range(n):
num = str(random.randint(0,9))
if alpha:
alpha_upper = chr(random.randint(65,90))
alpha_lower = chr(random.randint(97,122))
num = random.choice([num,alpha_upper,alpha_lower])
s += num
return s
print(code(4,False))
print(code(alpha=False))
三、时间模块(import time)
time.sleep(2) 程序走到这会等待2秒
时间格式:
时间戳时间:
print(time.time()) #1534767054.6681
格式化时间:
print(time.strftime(\'%Y-%m-%d %H:%M:%S\')) # str format time
# 2018-08-20 20:17:08
print(time.strftime(\'%y-%m-%d %H:%M:%S\')) # str format time
# 18-08-20 20:17:08
print(time.strftime(\'%Y-%m-%d %X\'))
# 2018-08-20 20:19:25
print(time.strftime(\'%c\'))
# Mon Aug 20 20:18:14 2018
结构化时间:
struct_time = time.localtime() # 北京时间
print(struct_time)
#time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, tm_hour=20, tm_min=21, tm_sec=23, tm_wday=0, tm_yday=232, tm_isdst=0)
print(struct_time.tm_mon)
# 8
print(time.gmtime()) #伦敦时间
时间戳时间换成字符串时间
struct_time = time.localtime(1500000000)
# print(time.gmtime(1500000000))
ret = time.strftime(\'%y-%m-%d %H:%M:%S\',struct_time)
print(ret)
字符串时间转时间戳时间
struct_time = time.strptime(\'2018-8-8\',\'%Y-%m-%d\')
print(struct_time)
res = time.mktime(struct_time)
print(res)

相关操作:
1.查看一下2000000000时间戳时间表示的年月日
时间戳 - 结构化 - 格式化
struct_t = time.localtime(2000000000)
print(struct_t)
print(time.strftime(\'%y-%m-%d\',struct_t))
2.将2008-8-8转换成时间戳时间
t = time.strptime(\'2008-8-8\',\'%Y-%m-%d\')
print(time.mktime(t))
3.请将当前时间的当前月1号的时间戳时间取出来 - 函数
def get_time():
st = time.localtime()
st2 = time.strptime(\'%s-%s-1\'%(st.tm_year,st.tm_mon),\'%Y-%m-%d\')
return time.mktime(st2)
print(get_time())
4.计算时间差 - 函数
str_time1 = \'2018-8-19 22:10:8\'
str_time2 = \'2018-8-20 11:07:3\'
struct_t1 = time.strptime(str_time1,\'%Y-%m-%d %H:%M:%S\')
struct_t2 = time.strptime(str_time2,\'%Y-%m-%d %H:%M:%S\')
timestamp1 = time.mktime(struct_t1)
timestamp2 = time.mktime(struct_t2)
sub_time = timestamp2 - timestamp1
gm_time = time.gmtime(sub_time)
# 1970-1-1 00:00:00
print(\'过去了%d年%d月%d天%d小时%d分钟%d秒\'%(gm_time.tm_year-1970,gm_time.tm_mon-1,
gm_time.tm_mday-1,gm_time.tm_hour,
gm_time.tm_min,gm_time.tm_sec))
# 过去了0年0月0天12小时56分钟55秒
四、sys模块(import sys)
sys是和python解释器打交道的。
sys.argv 命令行参数List,第一个元素是程序本身路径
print(sys.argv) # argv的第一个参数 是python这个命令后面的值
usr = input(\'username\')
pwd = input(\'password\')
usr = sys.argv[1]
pwd = sys.argv[2]
if usr == \'alex\' and pwd == \'alex3714\':
print(\'登录成功\')
else:
exit()
sys.exit(n) 退出程序,正常退出时exit(0),错误退出时sys.exit(1)
sys.path 返回模块的搜索路径
# 一个模块能否被顺利的导入 全看sys.path下面有没有这个模块所在的
# 自定义模块的时候 导入模块的时候 还需要再关注 sys.path
sys.modules
print(sys.modules) # 是我们导入到内存中的所有模块的名字,存在一个字典中 : 这个模块的内存地址
print(sys.modules[\'re\'].findall(\'\\d\',\'abc126\'))
五、os模块(import os #os是和操作系统交互的模块)
#文件和文件夹的处理 os.makedirs(\'dirname1/dirname2\') 可生成多层递归目录 os.removedirs(\'dirname1\') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(\'dirname\') 生成单级目录;相当于shell中mkdir dirname os.rmdir(\'dirname\') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(\'dirname\') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(\'path/filename\') 获取文件/目录信息 #执行操作系统命令 os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd #路径的处理 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如果path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
六、序列化模块 (json/pickle)
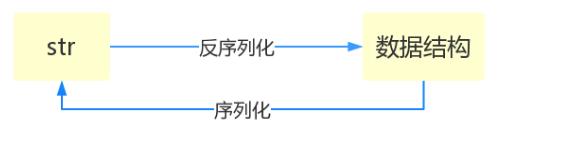
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
序列化的目的
dumps loads
在内存中做数据转换 :
dumps 数据类型 转成 字符串 序列化
loads 字符串 转成 数据类型 反序列化
dump load
直接将数据类型写入文件,直接从文件中读出数据类型
dump 数据类型 写入 文件 序列化
load 文件 读出 数据类型 反序列化
json是所有语言都通用的一种序列化格式
只支持 列表 字典 字符串 数字
字典的key必须是字符串
1 import json
2 dic = {\'key\':\'value\',\'key2\':\'value2\'}
3 ret = json.dumps(dic) #序列化
4 print(dic,type(dic)) #{\'key\': \'value\', \'key2\': \'value2\'} <class \'dict\'>
5 print(ret,type(ret)) #{"key": "value", "key2": "value2"} <class \'str\'>
6
7 res = json.loads(ret) #反序列化
8 print(res,type(res)) #{\'key\': \'value\', \'key2\': \'value2\'} <class \'dict\'>
9
10 dic = {1:\'value\',2:\'value\'}
11 ret = json.dumps(dic) #序列化
12 print(dic,type(dic)) #{1: \'value\', 2: \'value\'} <class \'dict\'>
13 print(ret,type(ret)) #{"1": "value", "2": "value"} <class \'str\'>
14
15 res = json.loads(ret) #反序列化
16 print(res,type(res)) #{\'1\': \'value\', \'2\': \'value\'} <class \'dict\'>
17
18 dic = {1:[1,2,3],2:(4,5,\'aa\')}
19 ret = json.dumps(dic) #序列化
20 print(dic,type(dic)) #{1: [1, 2, 3], 2: (4, 5, \'aa\')} <class \'dict\'>
21 print(ret,type(ret)) #{"1": [1, 2, 3], "2": [4, 5, "aa"]} <class \'str\'>
22
23 res = json.loads(ret) #反序列化
24 print(res,type(res)) #{\'1\': [1, 2, 3], \'2\': [4, 5, \'aa\']} <class \'dict\'>
25
26 s = {1,2,\'aaa\'}
27 json.dumps(s) #不能是集合
28
29 json.dumps({(1,2,3):123}) #keys must be a string
30 # json 能处理的数据类型:字符串 列表 字典 数字
31 # 字典中的key只能是字符串
32
33 # 向文件中记录字典
34 dic = {\'key\':\'value\',\'key2\':\'value2\'}
35 ret = json.dumps(dic) #序列化
36 with open(\'json_file\',\'a\') as f:
37 f.write(ret)
38
39 #从文件中读取字典
40 with open(\'json_file\',\'r\') as f:
41 str_dic = f.read()
42 dic = json.loads(str_dic) #反序列化
43 print(dic.keys())
44
45 # dump load 是直接操作文件的 问题:不支持连续的存取
46 dic = {\'key\':\'value\',\'key2\':\'value2\'}
47 with open(\'json_file\',\'a\') as f:
48 json.dump(dic,f)
49 with open(\'json_file\',\'r\') as f:
50 dic = json.load(f)
51 print(dic.keys())
52
53 # 一个一个存,一个一个取
54 dic = {\'key\':\'value\',\'key2\':\'value2\'}
55 with open(\'json_file\',\'a\') as f:
56 str_dic = json.dumps(dic)
57 f.write(str_dic+\'\\n\')
58 str_dic = json.dumps(dic)
59 f.write(str_dic+\'\\n\')
60 str_dic = json.dumps(dic)
61 f.write(str_dic+\'\\n\')
62 with open(\'json_file\',\'r\') as f:
63 for line in f:
64 dic = json.loads(line.strip())
65 print(dic.keys())
66
67 dic = {\'key\':\'你好\'}
68 print(json.dumps(dic,ensure_ascii=False)) #{"key": "你好"}
69
70 dic = {\'key\':\'你好\'}
71 print(json.dumps(dic,ensure_ascii=True)) #{"key": "\\u4f60\\u597d"}
pickle模块
只能在python中使用,支持python几乎所有的数据类型,序列化的结果是字节,所以在和文件操作的时候用rb,wb的模式打开。
可以执行多次dump和多次load。
1 import pickle
2 # 支持python中几乎所有的数据类型, 只能在python中使用
3 dic = {(1,2,3):{\'a\',\'b\'},1:\'abc\'}
4 ret = pickle.dumps(dic) #序列化,结果只能是字节
5 print(dic,type(dic)) #{(1, 2, 3): {\'a\', \'b\'}, 1: \'abc\'} <class \'dict\'>
6 print(ret,type(ret)) #b\'\\x80\\x03}q\\x00(K\\x01K\\x02K\\x03\\x87q\\x01cbuiltins\\nset\\nq\\x02]q\\x03(X\\x01\\x00\\x00\\x00aq\\x04X\\x01\\x00\\x00\\x00bq\\x05e\\x85q\\x06Rq\\x07K\\x01X\\x03\\x00\\x00\\x00abcq\\x08u.\' <class \'bytes\'>
7
8 res = pickle.loads(ret) #反序列化
9 print(res,type(res)) #{(1, 2, 3): {\'a\', \'b\'}, 1: \'abc\'} <class \'dict\'>
10
11 可以多次dump 和多次 load
12 dic = {(1,2,3):{\'a\',\'b\'},1:\'abc\'}
13 dic1 = {(1,2,3):{\'a\',\'b\'},2:\'abc\'}
14 dic2 = {(1,2,3):{\'a\',\'b\'},3:\'abc\'}
15 dic3 = {(1,2,3):{\'a\',\'b\'},4:\'abc\'}
16 with open(\'pickle_file\',\'wb\') as f:
17 pickle.dump(dic, f)
18 pickle.dump(dic1, f)
19 pickle.dump(dic2, f)
20 pickle.dump(dic3, f)
21
22 with open(\'pickle_file\',\'以上是关于2018.8.20 Python之路---常用模块的主要内容,如果未能解决你的问题,请参考以下文章