(数据科学学习手札47)基于Python的网络数据采集实战
Posted 费弗里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(数据科学学习手札47)基于Python的网络数据采集实战相关的知识,希望对你有一定的参考价值。
一、简介
最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑。
二、马蜂窝评论数据采集实战
2.1 数据要求
这次我们需要采集的数据是知名旅游网站马蜂窝下重庆区域内所有景点的用户评论数据,如下图所示:
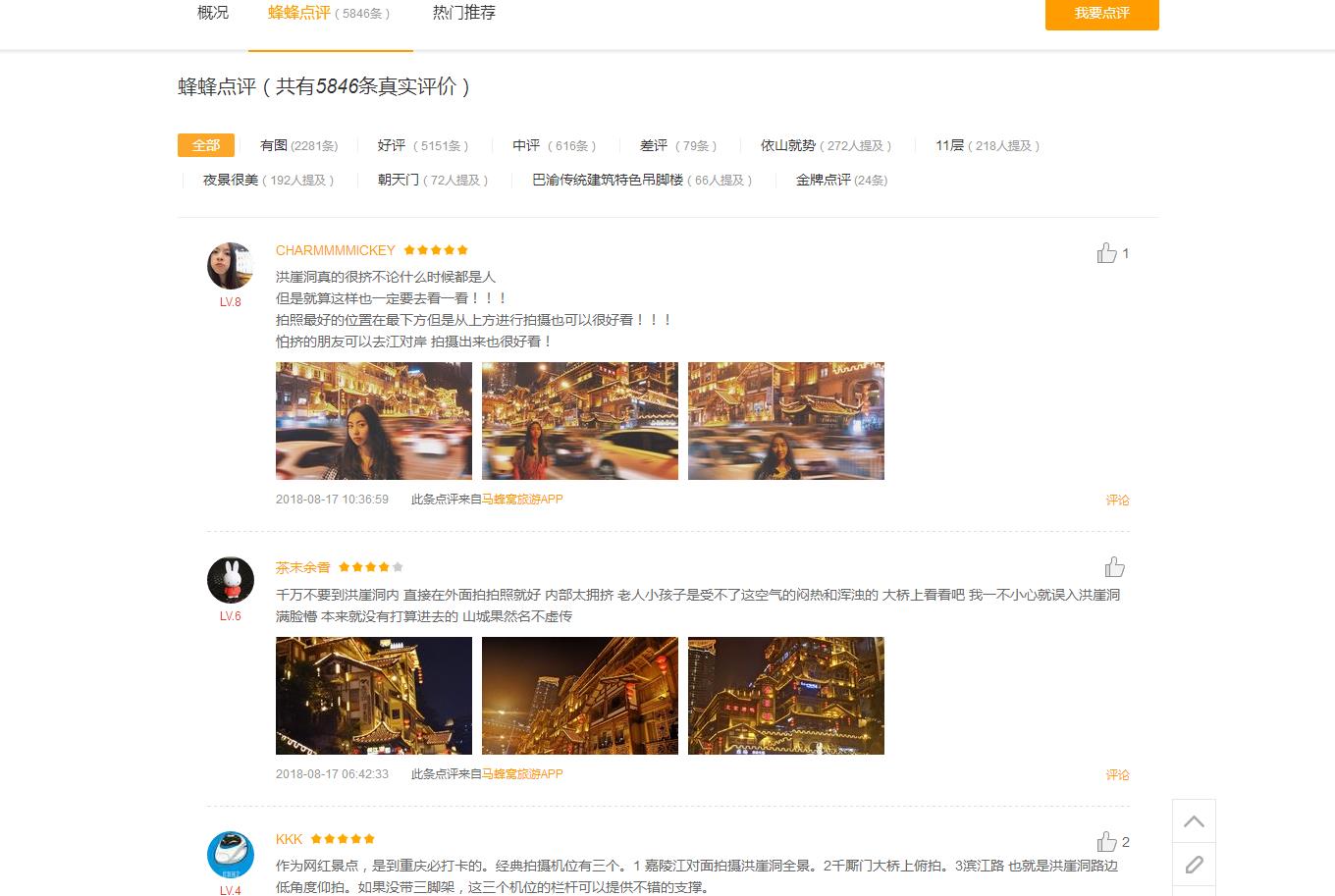
思路是,先获取所有景点的poi ID,即每一个景点主页url地址中的唯一数字:

这一步和(数据科学学习手札33)基于Python的网络数据采集实战(1)中做法类似,即在下述界面:

翻页抓取对应每个景点poi ID的部分即可:

比较简单,这里不再赘述,最终整理成数据框,景点名和poi ID一一对应。
接着根据得到的poi ID,再对每一个景点下的评论数据分别进行采集,但和之前遇到的最简单的静态网页不同,这里的评论数据是有js控制的,即当我们在景点页面内点击评论区块的下一页按钮,界面会刷新并显示下一页的评论内容,但浏览器url栏中的url地址并无改变,这就需要用更深入的方式来获取评论区域数据的真实url地址。
2.2 目标url地址的获取
以洪崖洞页面为例,点击页面内的蜂蜂点评进入评论内容区域:

当我们点击评论数据区域下方的下一页时,评论内容翻页刷新,但浏览器地址栏中的url地址并没有发生改变:

这时我们就需要找到控制评论数据区域的真实请求地址,在浏览器中按下F12,打开开发者工具,点击network项:

选择JS,这时可以发现下面并无内容,因为这里只会记录打开开发者工具后页面内新增的内容,这时我们点击评论区域下方的后一页按钮,随着界面内容的更新,下方network中随即出现了如下内容:

这就是请求评论区域内容的真实url地址,点击它,进入如下内容:

至此,我们便找到了控制评论区域发起请求的真实地址和相关属性,接下来我们先提取一下这些内容中我们需要的部分,为正式的采集做好准备;
2.3 伪装浏览器
要伪装浏览器,我们需要将上图中的Request Headers下除了cookies的内容复制下来,整理成一个叫做headers的字典如下(其中起关键作用的是User-Agent,其他的可以不记录):

再将Request Headers下的cookies中由;分隔的内容同样整理成一个叫做cookies的字典如下:
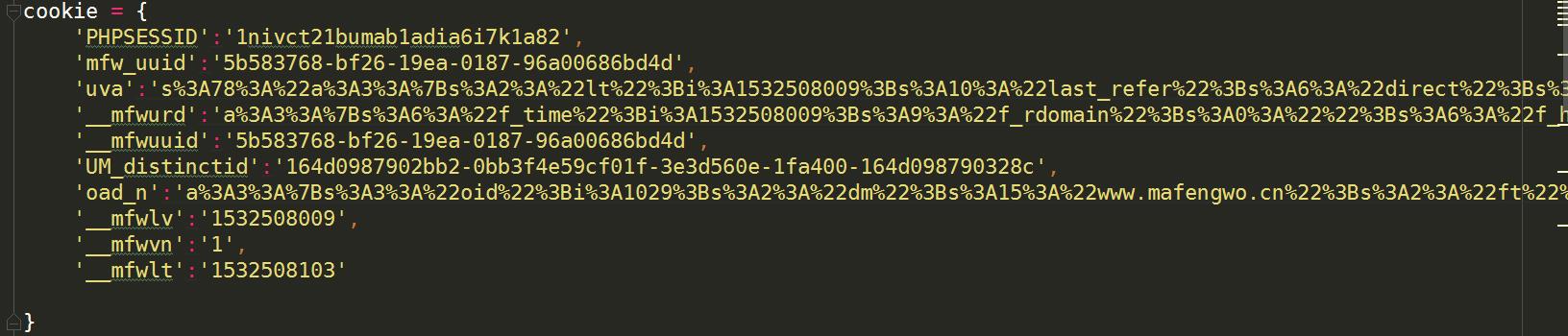
这两个参数我们会在requests包中的get方法中传入,接下来我们来观察翻页请求url的规律;
2.4 探索url规律
我们找到下列内容中红圈指示的地方:
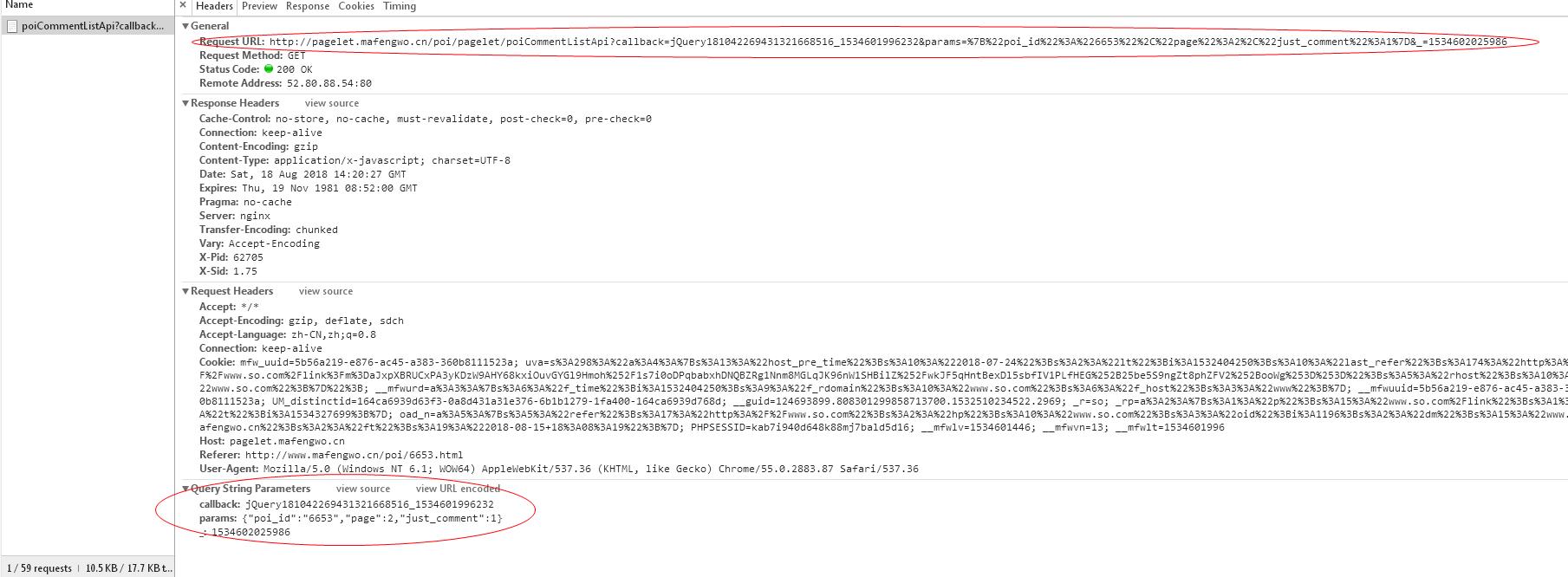
上面红圈中的内容是当前评论区域发起请求的真实url地址,下面红圈的内容是在当前url中的关键参数,很明显,params是一个字典,其中poi_id顾名思义即为当前景点(洪崖洞)对应的poi ID,page对应的则是当前评论内容所在的页数,just_comment这个参数我观察到在任何页中都不变,这里我们让它持续为1即可。
2.5 测试
了解到上述内容后,结合当前的url地址,可以得到下列替换规则:
http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApicallback=jQuery181042269431321668516_1534601996232¶ms=%7B%22poi_id%22%3A%226653%22%2C%22page%22%3A2%2C%22just_comment%22%3A1%7D&_=1534602025986
只需要控制红色区域内容的替换,我们即可实现对评论内容资源的请求,下面我们来做个测试,这里以解放碑(对应poi ID 1690)下第13页评论为例,按照上述规则,我们将网址分成素材和实时参数两部分,下面的url即为通过拼接最终得到的url地址:
url_left = \'http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18109093089574473625_1532513669920¶ms=%7B%22poi_id%22%3A%22\' url_middle = \'%22%2C%22page%22%3A\' url_right = \'%2C%22just_comment%22%3A1%7D&_=1532513718986\' url = url_left+\'1690\'+url_middle+\'13\'+url_right
我们在Python中进行测试,对上述url地址发起请求:
import requests #设置请求头文件 headers = { \'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36\', \'Accept\':\'*/*\', \'Accept-Encoding\':\'gzip, deflate\', \'Accept-Language\':\'zh-CN,zh;q=0.9\', \'Connection\':\'keep-alive\', \'Referer\':\'http://www.mafengwo.cn/poi/6653.html\' } #设置cookies cookie = { \'PHPSESSID\':\'1nivct21bumab1adia6i7k1a82\', \'mfw_uuid\':\'5b583768-bf26-19ea-0187-96a00686bd4d\', \'uva\':\'s%3A78%3A%22a%3A3%3A%7Bs%3A2%3A%22lt%22%3Bi%3A1532508009%3Bs%3A10%3A%22last_refer%22%3Bs%3A6%3A%22direct%22%3Bs%3A5%3A%22rhost%22%3Bs%3A0%3A%22%22%3B%7D%22%3B\', \'__mfwurd\':\'a%3A3%3A%7Bs%3A6%3A%22f_time%22%3Bi%3A1532508009%3Bs%3A9%3A%22f_rdomain%22%3Bs%3A0%3A%22%22%3Bs%3A6%3A%22f_host%22%3Bs%3A3%3A%22www%22%3B%7D\', \'__mfwuuid\':\'5b583768-bf26-19ea-0187-96a00686bd4d\', \'UM_distinctid\':\'164d0987902bb2-0bb3f4e59cf01f-3e3d560e-1fa400-164d098790328c\', \'oad_n\':\'a%3A3%3A%7Bs%3A3%3A%22oid%22%3Bi%3A1029%3Bs%3A2%3A%22dm%22%3Bs%3A15%3A%22www.mafengwo.cn%22%3Bs%3A2%3A%22ft%22%3Bs%3A19%3A%222018-07-25+16%3A40%3A08%22%3B%7D\', \'__mfwlv\':\'1532508009\', \'__mfwvn\':\'1\', \'__mfwlt\':\'1532508103\' } url_left = \'http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18109093089574473625_1532513669920¶ms=%7B%22poi_id%22%3A%22\' url_middle = \'%22%2C%22page%22%3A\' url_right = \'%2C%22just_comment%22%3A1%7D&_=1532513718986\' url = url_left+\'1690\'+url_middle+\'13\'+url_right r = requests.get(url=url, headers=headers, cookies=cookie)
得到网页内容如下:
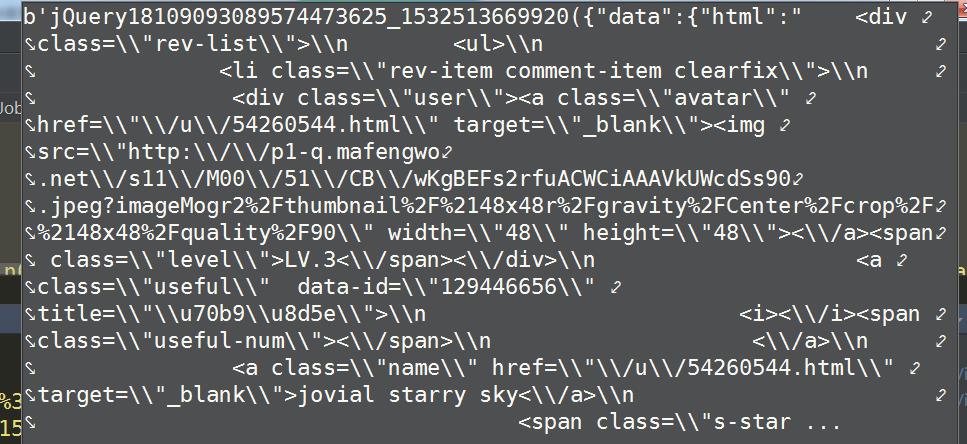
这里的网页内容还未经过转码,这里我们使用下述方式转码,并将\\替换为空字符:
\'\'\'对相应的网页内容进行转码\'\'\' html = r.content.decode(\'unicode-escape\').replace(\'\\\\\',\'\')
得到html为:

可以看到,需要的中文内容已经提取完毕,接下来我们需要做的是对我们感兴趣的内容进行提取,,这里我们感兴趣的是每条评论的文本内容、评分以及评论时间,这里使用正则表达式来提取:
import re from bs4 import BeautifulSoup obj = BeautifulSoup(html,\'lxml\') # # \'\'\'利用findAll定位目标标签及其属性并返回其字符形式结果\'\'\' text = list(obj.findAll(\'p\', {\'class\': "rev-txt"})) star = list(obj.findAll(\'span\')) Time = list(obj.findAll(\'span\', {\'class\': "time"})) #将每一条评论对应的内容提取出来 control = 0 for m in range(len(star)): try: if \'star\' in str(star[m]): \'\'\'设置不同的正则规则来提取目标内容\'\'\' print(re.findall(\'[0-5]+\', str(star[m]))[0]) print(re.sub(\'[a-zA-Z="\\-<> \\/\\n\\r]+\', \'\', str(text[control]))) print(re.findall(\'<.*?>(.*?)<.*?>\',str(Time[control]))[0]) control += 1 except Exception as e: print(\'error\')

通过上面的测试,我们成功获取到该测试页内的所需内容,下面附上完整采集的代码,只是加上一些错误处理机制、随机暂停防ban机制和一些保存数据的内容:
2.6 完整的采集程序
正式采集部分沿用前面测试中的思想,具体代码如下:
\'\'\'这个脚本用于对JS脚本控制翻页的动态网页进行爬取\'\'\' import requests import time import random from bs4 import BeautifulSoup import re import json import pandas as pd #设置请求头文件 headers = { \'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36\', \'Accept\':\'*/*\', \'Accept-Encoding\':\'gzip, deflate\', \'Accept-Language\':\'zh-CN,zh;q=0.9\', \'Connection\':\'keep-alive\', \'Referer\':\'http://www.mafengwo.cn/poi/6653.html\' } #设置cookies cookie = { \'PHPSESSID\':\'1nivct21bumab1adia6i7k1a82\', \'mfw_uuid\':\'5b583768-bf26-19ea-0187-96a00686bd4d\', \'uva\':\'s%3A78%3A%22a%3A3%3A%7Bs%3A2%3A%22lt%22%3Bi%3A1532508009%3Bs%3A10%3A%22last_refer%22%3Bs%3A6%3A%22direct%22%3Bs%3A5%3A%22rhost%22%3Bs%3A0%3A%22%22%3B%7D%22%3B\', \'__mfwurd\':\'a%3A3%3A%7Bs%3A6%3A%22f_time%22%3Bi%3A1532508009%3Bs%3A9%3A%22f_rdomain%22%3Bs%3A0%3A%22%22%3Bs%3A6%3A%22f_host%22%3Bs%3A3%3A%22www%22%3B%7D\', \'__mfwuuid\':\'5b583768-bf26-19ea-0187-96a00686bd4d\', \'UM_distinctid\':\'164d0987902bb2-0bb3f4e59cf01f-3e3d560e-1fa400-164d098790328c\', \'oad_n\':\'a%3A3%3A%7Bs%3A3%3A%22oid%22%3Bi%3A1029%3Bs%3A2%3A%22dm%22%3Bs%3A15%3A%22www.mafengwo.cn%22%3Bs%3A2%3A%22ft%22%3Bs%3A19%3A%222018-07-25+16%3A40%3A08%22%3B%7D\', \'__mfwlv\':\'1532508009\', \'__mfwvn\':\'1\', \'__mfwlt\':\'1532508103\' } \'\'\'JS脚本发起的真实的网址请求对应的网址内容模板(及除去几个动态参数之外的死板的url内容)\'\'\' url_left = \'http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18109093089574473625_1532513669920¶ms=%7B%22poi_id%22%3A%22\' url_middle = \'%22%2C%22page%22%3A\' url_right = \'%2C%22just_comment%22%3A1%7D&_=1532513718986\' data = pd.read_excel(r\'C:\\Users\\windows\\Desktop\\summer_project\\GIS\\data\\马蜂窝重庆景点评论数据(2018-7-26采集)\\chongqing_scene.xlsx\') \'\'\'读入poi_id数据以在循环中进行url的构建\'\'\' Q = {} poi_id_list = [] scene_name = [] for key,value in zip(data[\'id\'],data[\'景点名称\']): Q[str(key)] = str(value) poi_id_list.append(str(key)) scene_name.append(value) comment = [] S = [] id = [] t = [] count = 1 for i in poi_id_list: print(\'{}采集开始\'.format(Q[i])) \'\'\'构造包含poi_id内容的url前半部分内容\'\'\' url_first = url_left+i+url_middle for j in range(1,10000): try: \'\'\'构造包含翻页信息的完整url内容\'\'\' url_first = url_left + i + url_middle url = url_first + str(j) + url_right \'\'\'向构造好的真实网页发起请求\'\'\' r = requests.get(url=url, headers=headers, cookies=cookie) \'\'\'对相应的网页内容进行转码\'\'\' html = r.content.decode(\'unicode-escape\') \'\'\'判断当前景点所有有效评论页面是否已被爬取完成\'\'\' if \'暂无内容\' in str(html): print(\'本景点评论数据已被爬完!\') break else: \'\'\'将网页内容中的单\\替换成空\'\'\' html = html.replace(\'\\\\\', \'\') \'\'\'利用bs4对网页内容进行CSS解析\'\'\' obj = BeautifulSoup(html, \'lxml\') # # \'\'\'利用findAll定位目标标签及其属性并返回其字符形式结果\'\'\' text = list(obj.findAll(\'p\', {\'class\': "rev-txt"})) star = list(obj.findAll(\'span\')) Time = list(obj.findAll(\'span\', {\'class\': "time"})) \'\'\'设置一个复杂周密的错误处理机制以防止长时间爬虫任务中可能出现的各种错误中断任务主体\'\'\' control = 0 for m in range(len(star)): try: if \'star\' in str(star[m]): \'\'\'设置不同的正则规则来提取目标内容\'\'\' token = re.findall(\'[0-5]+\', str(star[m]))[0] comment.append(re.sub(\'[a-zA-Z="\\-<> \\/\\n\\r]+\', \'\', str(text[control]))) t.append(re.findall(\'<.*?>(.*?)<.*?>\',str(Time[control]))[0]) S.append(int(token)) id.append(i) print(\'-\'*100) print(\'总第{}条评论被采集\'.format(str(count))) print(\'-\' * 100) count += 1 control += 1 else: pass except Exception as e: pass \'\'\'设置随机睡眠机制以防止被ban\'\'\' print(\'=\'*100) print(\'{}的\'.format(Q[i]),\'第{}页被采集完\'.format(str(j))) print(\'=\' *100) time.sleep(random.randint(2,4)) except Exception as e: pass print(\'{}采集结束\'.format(Q[i])) \'\'\'写出数据到数据框\'\'\' df = pd.DataFrame({\'id\':id, \'comment\':comment, \'S\':S, \'Time\':t}) df.to_excel(\'raw_data.xlsx\',index=False)
运行结果:

最终得到的评论数据集格式如下:

以上就是关于本文的全部内容,如有不解之处,望指出。
以上是关于(数据科学学习手札47)基于Python的网络数据采集实战的主要内容,如果未能解决你的问题,请参考以下文章