Spring Cloud Hystrix熔断机制原理剖析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Cloud Hystrix熔断机制原理剖析相关的知识,希望对你有一定的参考价值。
参考技术A 一、前言
在分布式系统架构中多个系统之间通常是通过远程RPC调用进行通信,也就是 A 系统调用 B 系统服务,B 系统调用 C 系统的服务。当尾部应用 C 发生故障而系统 B 没有服务降级时候可能会导致 B,甚至系统 A 瘫痪,这种现象被称为雪崩现象。所以在系统设计时候要使用一定的降级策略,来保证当服务提供方服务不可用时候,服务调用方可以切换到降级后的策略进行执行。
二、Hystrix 中基于自反馈调节熔断状态的算法原理
我们可以把熔断器想象为一个保险丝,在电路系统中,一般在所有的家电系统连接外部供电的线路中间都会加一个保险丝,当外部电压过高,达到保险丝的熔点时候,保险丝就会被熔断,从而可以切断家电系统与外部电路的联通,进而保障家电系统不会因为电压过高而损坏。
Hystrix提供的熔断器就有类似功能,当在一定时间段内服务调用方调用服务提供方的服务的次数达到设定的阈值,并且出错的次数也达到设置的出错阈值,就会进行服务降级,让服务调用方之间执行本地设置的降级策略,而不再发起远程调用。但是Hystrix提供的熔断器具有自我反馈,自我恢复的功能,Hystrix会根据调用接口的情况,让熔断器在closed,open,half-open三种状态之间自动切换。
open状态说明打开熔断,也就是服务调用方执行本地降级策略,不进行远程调用。
closed状态说明关闭了熔断,这时候服务调用方直接发起远程调用。
half-open状态,则是一个中间状态,当熔断器处于这种状态时候,直接发起远程调用。
三种状态的转换:
open->half-open:当服务接口对应的熔断器状态为open状态时候,所有服务调用方调用该服务方法时候都是执行本地降级方法,那么什么时候才会恢复到远程调用那?Hystrix提供了一种测试策略,也就是设置了一个时间窗口,从熔断器状态变为open状态开始的一个时间窗口内,调用该服务接口时候都委托服务降级方法进行执行。如果时间超过了时间窗口,则把熔断状态从open->half-open,这时候服务调用方调用服务接口时候,就可以发起远程调用而不再使用本地降级接口,如果发起远程调用还是失败,则重新设置熔断器状态为open状态,从新记录时间窗口开始时间。
half-open->closed: 当熔断器状态为half-open,这时候服务调用方调用服务接口时候,就可以发起远程调用而不再使用本地降级接口,如果发起远程调用成功,则重新设置熔断器状态为closed状态。
那么有一个问题,用来判断熔断器从closed->open转换的数据是哪里来的那?其实这个是HystrixCommandMetrics对象来做的,该对象用来存在HystrixCommand的一些指标数据,比如接口调用次数,调用接口失败的次数等等,后面我们会讲解。
图中流程的说明:
注意:熔断是否开启熔断器主要由依赖调用的错误比率决定的,依赖调用的错误比率=请求失败数/请求总数。Hystrix中断路器打开的默认请求错误比率为50%(这里暂时称为请求错误率),还有一个参数,用于设置在一个滚动窗口中,打开断路器的最少请求数(这里暂时称为滚动窗口最小请求数),这里举个具体的例子:如果滚动窗口最小请求数为默认20,在一个窗口内(默认10秒,统计滚动窗口的时间可以设置),收到19个请求,即使这19个请求都失败了,此时请求错误率高达95%,但是断路器也不会打开。对于被熔断的请求,并不是永久被切断,而是被暂停一段时间(默认是5000ms)之后,允许部分请求通过,若请求都是健康的(ResponseTime<250ms)则对请求健康恢复(取消熔断),如果不是健康的,则继续熔断。(这里很容易出现一种错觉:多个请求失败但是没有触发熔断。这是因为在一个滚动窗口内的失败请求数没有达到打开断路器的最少请求数)
三、总结
系统设计时候要使用一定的降级策略,来保证当服务提供方服务不可用时候,服务调用方可以切换到降级后的策略进行执行,Hystrix作为熔断器组件使用范围还是很广泛的.
学过分布式、微服务知识的朋友们对熔断机制都不会陌生的,即使没有系统化的学习过理论知识,在实际项目开发中也使用过,熔断机制其实就是一种补救措施,不至于一个节点服务宕机了,整个服务系统全部完蛋,从业务层面上看,增强了用户体验,运营角度看,不至于太难看。
10.Spring-Cloud-Hystrix之熔断监控Hystrix Dashboard单个应用
SpringCloud完美的整合Hystrix-dashboard,Hystrix-dashboard是一款针对Hystrix进行实时监控的工具,通过Hystrix Dashboard我们可以在直观地看到各Hystrix Command的请求响应时间, 请求成功率等数据。可以实时反馈信息帮助我们快速发现系统中,但是只使用Hystrix Dashboard的话, 你只能看到单个应用内的服务信息。
在上一个项目上重构地址
1.pom.xml(必须包)
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--引入hystrix熔断器 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> </dependency> <!--引入hystrix dashboard(仪表盘)--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix-dashboard</artifactId> </dependency>
2.启动类
package com.niugang; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; import org.springframework.cloud.client.loadbalancer.LoadBalanced; import org.springframework.cloud.netflix.hystrix.dashboard.EnableHystrixDashboard; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.ComponentScan; import org.springframework.web.client.RestTemplate; /** * 负责服务的发现与消费 * * @author niugang * */ @SpringBootApplication @EnableDiscoveryClient @EnableCircuitBreaker @EnableHystrixDashboard //启动仪表盘 /* * @SpringCloudApplication * 包含了 * @SpringBootApplication * @EnableDiscoveryClient * @EnableCircuitBreaker * 着三个注解 */ @ComponentScan public class Application { //负载均衡 @LoadBalanced @Bean public RestTemplate restTemplate() { return new RestTemplate(); } public static void main(String[] args) { SpringApplication.run(Application.class, args); } }

3.访问
启动工程后访问 http://localhost:9002/hystrix,看到如下
![]() ?
?

上面截图是HystrixBoard的监控首页,该页面并没有什么监控信息。从1,2,3标号中可以知道HystrixBoard提供了三种不同的监控方式。
标号1:默认的集群方式:通过URL http://turbine-hostname:port/turbine.stream开启,实现对默认集群的监控。
标号2:指定的集群监控,通过URL http://turbine-hostname:port/turbine.stream?cluster=[clusterName]开启对clusterName的集群监控。
标号3:单体应用的监控,通过URL http://hystrix-app:port/hystrix.stream开启,实现对具体某个服务实例的监控。
标号4:Delay:改参数用来控制服务器上轮训监控信息的延迟时间,默认为2000毫秒,可以通过配置该属性来降低客户端的网络和CPU消耗。
标号5:Title:该参数对应了上图头补标题Hystrix Stream之后的内容,默认会使用具体监控实例的URL,可以通过该信息来展示更合适的标题。
点击Monitor Stream ,如果没有请求会先显示Loading ...,刷新几次http://localhost:9002/queryUser/5,仪表板监控如下:
![]() ?
?

访问http://localhost:9002/hystrix.stream 也会不断的显示ping(浏览器一直在刷新):
![]() ?
?

Hystrix Dashboard Wiki上详细说明了图上每个指标的含义,如下图:
![]() ?
?
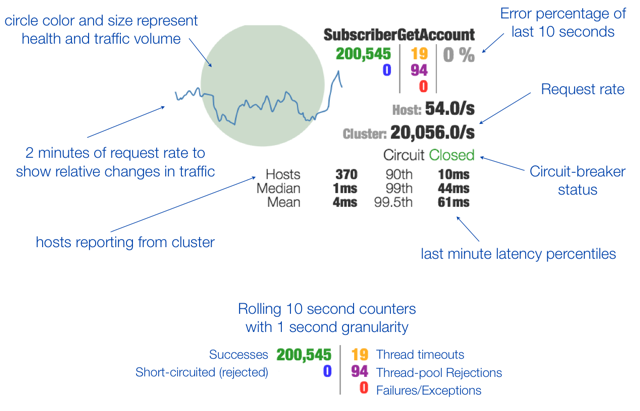
![]() ?
?

左上部实心圆和一条曲线含义:
实心圆:通过颜色的变化代表了实例的健康程度,它的大小也会根据实例的请求流量发生变化,流量越来实心圆越大。
曲线:用来记录2分钟内流量的相对变化,可通过它来观察流量的上升和下降趋势。
微信公众号:
![]() ?
?

JAVA程序猿成长之路
分享资源,记录程序猿成长点滴。专注于Java,Spring,SpringBoot,SpringCloud,分布式,微服务。
以上是关于Spring Cloud Hystrix熔断机制原理剖析的主要内容,如果未能解决你的问题,请参考以下文章