python_正则表达式
Posted 含笑半步颠√
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python_正则表达式相关的知识,希望对你有一定的参考价值。
了解正则:
在实际的应用中,我们会经常得到用户的输入,在得到用户的输入之后,需要我们对输入进行判断时候合法,比如判断输入的手机号码,从形式上来看是正确的呢?
笨办法:
phone = "15132154554" if phone.startswith("1") and phone.isdigit() and len(phone) == 11: print("正在给你发送验证码") # 验证通过 else: print("请输入正确的电话号码") #验证失败
利用正则:
import re phone = "15132154554" # 匹配,满足正则表达式的内容 if re.findall(r"^1\\d{10}$", phone): print("正在给你发送验证码") else: print("请输入正确的电话号码")
那么看到这里大家就理解了把,正则就是通过匹配满足的条件,达到优化代码的方式。我们进入正题
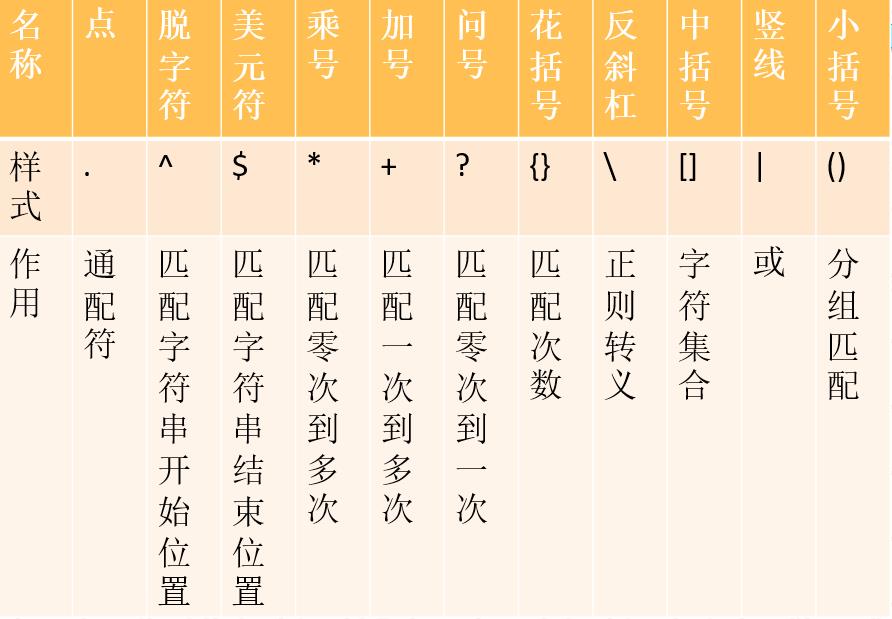
. 通配符,匹配除 \\n 外所有的字符
import re st1 = "\\nthis is pig \\n do you know?" ss1 = re.findall(".", st1) print(ss1)
结果
[\'t\', \'h\', \'i\', \'s\', \' \', \'i\', \'s\', \' \', \'p\', \'i\', \'g\', \' \', \' \', \'d\', \'o\', \' \', \'y\', \'o\', \'u\', \' \', \'k\', \'n\', \'o\', \'w\', \'?\']
^ 匹配字符串开始的位置
import re st2 = "this is pig \\n do you know?" ss2 = re.findall("^th", st2) print(ss2) ss2 = re.findall("^doyou", st2) print(ss2)
结果
[\'th\'] []
$ 匹配字符串结束位置
import re st3 = "this is pig \\n do you know" ss3 = re.findall("ow$", st3) print(ss3) ss3 = re.findall("pig$", st3) print(ss3)
结果
[\'ow\'] []
* 匹配前面的正则0次到无穷次
import re st4 = "this is pig \\n do you know?" ss4 = re.findall("i*", st4) print(ss4) ss4 = re.findall("is*", st4)
* 匹配复数 不存在空字符 print(ss4)
结果
[\'\', \'\', \'i\', \'\', \'\', \'i\', \'\', \'\', \'\', \'i\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\'] [\'is\', \'is\', \'i\']
+ 匹配前面的正则1次到无穷次
import re st5 = "this is pig \\n do you know?" ss5 = re.findall("i+", st5) print(ss5) ss5 = re.findall("is+", st5) print(ss5)
结果
[\'i\', \'i\', \'i\'] [\'is\', \'is\']
? 匹配前面的正则0次到1次
import re st6 = "this is pig \\n do you know?" ss6 = re.findall("i?", st6) print(ss6) ss6 = re.findall("is?", st6) print(ss6)
结果
[\'\', \'\', \'i\', \'\', \'\', \'i\', \'\', \'\', \'\', \'i\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\', \'\'] [\'is\', \'is\', \'i\']
{} 匹配次数
{N,} 匹配前面的正则 N到无穷次
{,M} 匹配前面的正则 0到M次
{N,M} 匹配前面的正则 N到M次
注: N和M皆为正整数
import re st7 = "aa^&*aaa^&*aaaa^&*aaaaa^&*aaaaaa" s1 = re.findall(r"a{1,}", st7) print(s1) s2 = re.findall(r"a{,3}", st7) print(s2) s3 = re.findall(r"a{1,4}", st7) print(s3)
结果
[\'aa\', \'aaa\', \'aaaa\', \'aaaaa\', \'aaaaaa\'] [\'aa\', \'\', \'\', \'\', \'aaa\', \'\', \'\', \'\', \'aaa\', \'a\', \'\', \'\', \'\', \'aaa\', \'aa\', \'\', \'\', \'\', \'aaa\', \'aaa\', \'\'] [\'aa\', \'aaa\', \'aaaa\', \'aaaa\', \'a\', \'aaaa\', \'aa\']
\\ 正则转义符
\\d 匹配数字
\\s 匹配空白符号
\\w 匹配字母、数字、下划线、汉字
\\b 单词边界
import re st8 = "this is 12 dog 3 \\n45 \\t6 你_好*^acfun" a1 = re.findall(r"\\d", st8) print(a1) a2 = re.findall(r"\\s", st8) print(a2) a3 = re.findall(r"\\w", st8) print(a3) a4 = re.findall(r"\\bac", st8) print(a4)
结果
[\'1\', \'2\', \'3\', \'4\', \'5\', \'6\'] [\' \', \' \', \' \', \' \', \' \', \'\\n\', \' \', \' \', \'\\t\', \' \'] [\'t\', \'h\', \'i\', \'s\', \'i\', \'s\', \'1\', \'2\', \'d\', \'o\', \'g\', \'3\', \'4\', \'5\', \'6\', \'你\', \'_\', \'好\', \'a\', \'c\', \'f\', \'u\', \'n\'] [\'ac\']
\\ 正则转义符
\\D 匹配数字以外的字符
\\S 匹配空白符号以外的字符
\\W 匹配字母、数字、下划线、汉字以外的字符
\\B 非单词边界
import re st1 = "this is 12 dog 3 \\n45 \\t6 你_好*^acfun" s1 = re.findall(r"\\D", st1) print(s1) s2 = re.findall(r"\\S", st1) print(s2) s3 = re.findall(r"\\W", st1) print(s3) s4 = re.findall(r"\\Bcf", st1) print(s4)
结果
[\'t\', \'h\', \'i\', \'s\', \' \', \'i\', \'s\', \' \', \' \', \'d\', \'o\', \'g\', \' \', \' \', \'\\n\', \' \', \' \', \'\\t\', \' \', \'你\', \'_\', \'好\', \'*\', \'^\', \'a\', \'c\', \'f\', \'u\', \'n\'] [\'t\', \'h\', \'i\', \'s\', \'i\', \'s\', \'1\', \'2\', \'d\', \'o\', \'g\', \'3\', \'4\', \'5\', \'6\', \'你\', \'_\', \'好\', \'*\', \'^\', \'a\', \'c\', \'f\', \'u\', \'n\'] [\' \', \' \', \' \', \' \', \' \', \'\\n\', \' \', \' \', \'\\t\', \' \', \'*\', \'^\'] [\'cf\']
[] 字符集合,匹配在这中间的所有字符
. % * + ? () {} 在中括号里面仅表示符号本身
^ 在中括号里面表示取反
st9 = "this is 12 dog 3 \\n45 \\t6 你_好*^acfun" t1 = re.findall(r"[132]", st9) print(t1) t2 = re.findall(r"[^i]", st9) print(t2)
结果
[\'1\', \'2\', \'3\'] [\'t\', \'h\', \'s\', \' \', \'s\', \' \', \'1\', \'2\', \' \', \'d\', \'o\', \'g\', \' \', \'3\', \' \', \'\\n\', \'4\', \'5\', \' \', \' \', \'\\t\', \'6\', \' \', \'你\', \'_\', \'好\', \'*\', \'^\', \'a\', \'c\', \'f\', \'u\', \'n\']
| 或
import re st10 = "this is 12 dog 3 \\n45 \\t6 你_好*^acfun" st10 = re.findall(r"1|333", st10) print(st10)
结果
[\'1\']
() 分组匹配,只会返回括号中匹配的内容
import re st11 = "this is 12 dog 3 \\n45 \\t6 你_好*^acfun" w1 = re.findall(r"1(\\d)", st11) print(w1) w2 = re.findall(r"t(\\w)", st11) print(w2) w3 = re.findall(r" (.)", st11) print(w3)
结果
[\'2\'] [\'h\'] [\'i\', \'1\', \'d\', \'3\', \' \', \'你\']
贪婪:寻找最长的匹配;会产生回溯
非贪婪:寻找最短的匹配
import re st12 = "<table><tr><td>表格1</td</tr></table>这里是末尾" s12 = re.findall(r"<.*>", st12) # 贪婪
# 运行机制:匹配到第一个字符,回溯到最后向前找,找到拿全部,返回 print(s12) s22 = re.findall(r"<.*?>", st12) # 非贪婪 print(s22)
结果
[\'<table><tr><td>表格1</td</tr></table>\'] [\'<table>\', \'<tr>\', \'<td>\', \'</td</tr>\', \'</table>\']
到这里,我们的元字符就整理完毕了,看到这里。距离我们的应用还很远,那么小编在这里再写个现实中的例子。
小编是测试, 再用Jmeter 正则表达式取json串的时候遇到的问题,见下:
{"status":0,"registerTenantId":"","statusText":"??????","developInfo":"","detailStatus":"","detailStatusText":"","detailErrors":[],"data":"{\\"id\\":150074004,\\"entityId\\":409}","entityName":"","copyPriceMap":""}
那么我要取出 json 中的id 值, 因为是json{str}, jmeter不支持python语法,所有书写如下:
"data".+":(\\d+),

作者:含笑半步颠√
出处:https://www.cnblogs.com/lixy-88428977/
欢迎转载,但请在文章页面明显位置给出原文链接。
以上是关于python_正则表达式的主要内容,如果未能解决你的问题,请参考以下文章