python 文件处理
Posted foremost
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 文件处理相关的知识,希望对你有一定的参考价值。
1、打开文件open 函数
open函数最常用的使用方法如下:文件句柄 = open(\'文件路径\', \'模式\',编码方式)。 encode=\'\'
1、关于文件路径
#文件路径:
主要有两种,一种是使用相对路径,想上面的例子就是使用相对路径。
另外一种就是绝对路径, 如:C:/Users/Desktop/python/test.txt\'
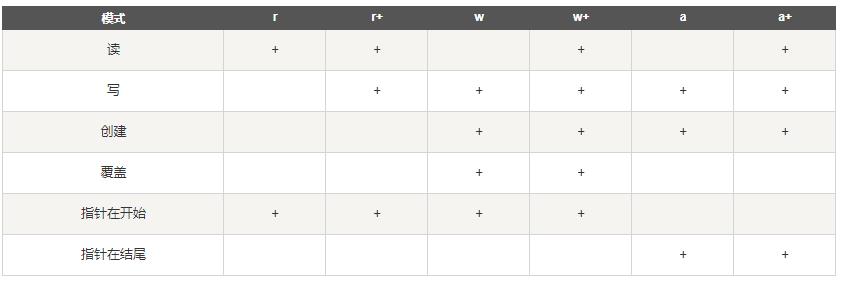
2、读取文件的各种方法说明:
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。(只读模式)指针在开头 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 (只读模式) 指针在开头 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 (读写模式)指针在开头 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。(删除原内容,写入,文件不存在就创建)指针在开头 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。指针在开头 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
# test.txt原文 :python,is,on,the,way
# 只读
f=open(\'test.txt\',\'r\')
print(f.read())# 输出 python,is,on,the,way# 读写
#读写
# 先写再度 此模式在最开始光标在最开始 f=open(\'test.txt\',\'r+\') f.write(\'java\') print(f.read()) #on,is,on, the, way f.close() 文本内容:# javaon,is,on,the,way 首先,以r 方式打开光标都会在最开始的位置,这时候执行f.write(\'java\'), 这时候就把原来的pyth 紧接着进行print(f.read())。就会把后面剩下的文本内容打印出来。所以输出就是:on,is,on, the, way 整个程序完成后, 整个文本内容就成了javaon,is,on,the,way (光标!!) 写入的光标依据输入字符串的长度往后移动,,空格,逗号等符号也算!被取代
python,is,on,the,way
当写入 java1234
最后文本中为 java1234s,on,the,way
#----------------------------------------------
#先读再写 读取之后光标停留在文本末尾
f=open(\'test.txt\',\'r+\')
f.read()
f.write("java1234")
f.write("aa")
f.write("bb")
f.write("cc")
f.write("dd")
先读再写的结果: python,is,on,the,wayjava1234aabbccdd
先读再写就是往读的后面依次添加,先写再读就是在文本最开始位置依次添加。
循环文件: f = open("text.txt",\'r\',encoding="utf-8") for line in f: print(line) f.close() 就是输出文件的内容
3、读取文件的三种操作
# ----------------------------------------------------------------------- 读取文件的三种操作 1、read() #一次性读取文本中全部的内容,以字符串的形式返回结果 文本里面是什么状态读取就是什么状态: 特点是:读取整个文件,将文件内容放到一个字符串变量中。劣势是:如果文件非常大,尤其是大于内存时,无法使用read()方法。read()直接读取字节到字符串中,包括了换行符 2、readline() #只读取每次读取第一行的内容,以字符串的形式返回结果 3、readlines() #读取文本所有内容,并且以列表的格式返回结果,一般配合for in使用 f = file.readlines() 读取文本,每行为一个元素:[\'beijing haha hhhhh kkkkkk lllll\'];在不同行的读取结果:[\'beijing\\n\', \'haha\\n\', \'hhhhh\\n\', \'kkkkkk lllll\'] #-------------------------------------------------------------------------------- text = file.read() # 结果为str类型 read()、.readline() 和 .readlines()。每种方法可以接受一个变量以限制每次读取的数据量,但它们通常不使用变量。
4、关闭文件:
不关闭占用内存资源,而且还可能导致其他不安全隐患。还有一种方法可以让我们不用去特意关注关闭文件。那就是 with open()
with open(\'test.txt\',\'a+\') as f: f.write(\'123\') print(f.readable())
这不必调用f.close()方法。
5、写入文件
# 写入
# test.txt原文 :python,is,on,the,way
f=open(\'test.txt\',\'r+\')
# 前面加 r
print(f.read())
f.write(r\'this\\nis\\nhaiku\') #write(string)
print(f.read()) >>输出
python,is,on,the,way
this\\nis\\nhaiku
# 不加 r(r\'this\\nis\\nhaiku\')
输出:
python,is,on,the,way
this
is
haiku
#------------------------------------------------------------------------------------------------------------------
还有write、writelines方法,用法与上述方法对应类似,只不过write写入的对象时字符串(str),writelines写入的是列表(list),即:
obj.write(str)
obj.writelines(sequence)
向文件写入一个字符串或一个字符串列表,如果字符串列表中的元素需要换行要自己加入换行符
# writelines(list)写入时列表
list02 = ["11","test","hehe","44","55"]
obj.writelines(list02)
li1 = [\'1\',\'2\',\'3\',\'[1,2,3]\']
writelines 写入list 但 列表里面的每个元素必须是字符串的形式,否则会报错
with open(\'test.txt\',\'r+\',encoding=\'utf-8\') as file:
li1 = [\'1\',\'2\',\'3\']
f2 = file.writelines(li1) #写入后文本中显示: 123国人主要在亚洲 utf-8 一个中文占三个字节
f = file.read()
print(f) # 原先的test.txt:中国人主要在亚洲
6、read(size),size可以从文件中读取的字符数
以rb模式打开就是读取的字节数------------以r模式打开就是读取的字符数
1、f.read([size]):默认一次性读入打开的文件内容。如果有size参数,则指定每次读入字符数。注意,此处按字符来读入,一个汉字为一个字符
例如文本:123,。[]国人主要在亚洲 # 字符每写一个就算字符,英文,汉字,标点符号都算
f = file.read(8)# 0 读出为空,1才为第一个字符
print(f)
> 123,。[]国 (读取8个显示的结果)
2、f.readline([size]):一次读入一行文件内容
f = file.readline(8)
print(f)
> 123,。[]国 #size字符数
3、f.readlines([size]):将文件内容全部读入,保存在一个列表中,每行为一个元素。
文本中两行:
123,。[]国人主要在亚洲 (14个字符)
hdi0好
若
f = file.readlines(14) #(size<=14)
print(f)
>[\'123,。[]国人主要在亚洲\\n\'] 只显示第一行的内容
f = file.readlines(15) # 超过第一行字符数,则显示第二行的内容
print(f)
>
[\'123,。[]国人主要在亚洲\\n\', \'hdi0好\']
f.writ(str,encoding=):将str写入文件,可以指定写入的编码格式,默认为utf-8
f.writlines()
f.readable() : 判断是否可读,返回布尔值。如果是在只写模式下打开文件, 也是返回false
f.writable():判断是否可写
f.tell() : 返回当前光标位置
f.seek(offset,whence=0):将光标位置移至所需位置。offset为偏移量。whence定义开始偏移的位置。
0为从文件开头偏移。1为从当前位置开始偏移。2为从文件末尾开始偏移,---------默认为0。
def seek(self, *args, **kwargs): # real signature unknown
把操作文件的光标移到指定位置
*注意seek的长度是按字节算的, 字符编码存每个字符所占的字节长度不一样。
如“路飞学城” 用gbk存是2个字节一个字,用utf-8就是3个字节,因此以gbk打开时,seek(4) 就把光标切换到了“飞”和“学”两个字中间。
但如果是utf8,seek(4)会导致,拿到了飞这个字的一部分字节,打印的话会报错,因为处理剩下的文本时发现用utf8处理不了了,因为编码对不上了。少了一个字节
def truncate(self, *args, **kwargs): # real signature unknown
按指定长度截断文件
*指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉。
f.flush() 把文件从内存buffer里强制刷新到硬盘
清空文件内容 f.truncate() 注意:仅当以 "r+" "rb+" "w" "wb" "wb+"等以可写模式打开的文件才可以执行该功能。 七、删除文件 import os os.remove(file)
以上是关于python 文件处理的主要内容,如果未能解决你的问题,请参考以下文章