Python 代码块 小数据池
Posted colin1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 代码块 小数据池相关的知识,希望对你有一定的参考价值。
一 代码块
什么是代码块???
Python程序是由代码块构造的。先举一个例子:
1 for i in ‘12334567‘: 2 print(i)
1 def func(): 2 print(‘Hello,world!‘)
1 class A: 2 name = ‘colin‘
从上面的例子可以称为代码块,虽然上面的缩进的内容都叫代码块,但是他们并不是python中严格定义的代码块。
那么,python中真正意义上的代码块又怎么定义?
因此,我们定义:一个模块,一个函数,一个类,一个文件等都是一个代码块。
此外,在电脑终端模式下,输入的每个命令我们也可以认为是一个代码块。如:

二 id, is , == 之间的关系
在Python中,id是什么?
我们可以理解为id是电脑的内存地址,当你利用id()内置函数去查询一个数据的内存地址,例如:
1 name = ‘colin‘ 2 print(id(name)) # 1986166776248
从上面的代码分析可知,当调用python中id()指令时,会输出变量name的内存地址,其地址位置为:1986166776248 ,第二次调用后,内存地址发生变化,为:1957356364216 。可知,变量在内存中地址是不固定的。
is 是什么? == 又是什么?
我们将is 用来判断两个变量的id值是否相等,而 ‘==’ 是表示该符号两边的数值是否相等。
如果内存地址相等,那么== 两边所指向的是同一个内存地址。
总的来说,我们总结为:如果is是True,那么== 一定是True

三 小数据池(缓存机制,驻留机制)
什么是小数据池?
小数据池也称为小整数缓存机制,或者称为驻留机制等等,主要是用于python对内存做的一个优化,通常将-5!~256的整数,以及一定规则的字符串,提前在内存中创建了池,容器,容器里固定的放入这些数。
小数据池的应用数据类型:整数,字符串,bool值。
而为什么要使用小数据池???
其优点主要有以下两点:
1. 节省内存,
2. 提高性能与效率。
python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
int:对于整数来说,小数据池的范围是-5~256 ,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。
str:字符串要从下面这几个大方向讨论:
1,字符串的长度为0或者1,默认都采用了驻留机制(小数据池)
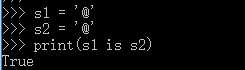
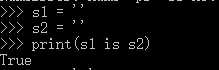
2,字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。

3,用乘法得到的字符串,分两种情况。
3.1 乘数为1时:
仅含大小写字母,数字,下划线,默认驻留。

含其他字符,长度<=1,默认驻留。
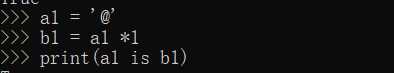
含其他字符,长度>1,默认驻留。

3.2 乘数>=2时:
仅含大小写字母,数字,下划线,总长度<=20,默认驻留。
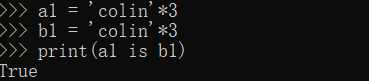
在大环境下的python3中:
str:内存(内部)编码方式为Unicode
bytes:python的基础数据类型之一,它和str相当于双胞胎,str拥有的所有方法,bytes类型都适用。
编码之间不能相互识别:
1. 由于编码之间不能相互识别。(由于:str 内部编码是以unicode方式。)
2. 网络传输,或者硬盘存储的01010101,必须是以非unicode编码方式的01010101.
如图:
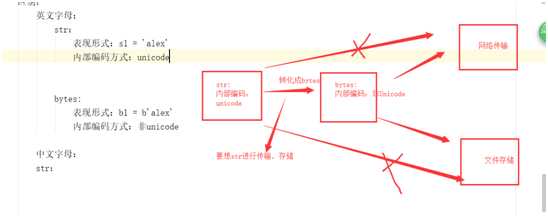
# str --------> bites encode 编码
1 s1 = ‘colin‘ 2 s2 = ‘明天‘ 3 b1 = s1.encode(‘utf-8‘) 4 print(b1) # b‘colin‘ 5 b2 = s2.encode(‘gbk‘) 6 print(b2) # b‘xc3xf7xccxec‘
# bytes --------> str decode 解码
1 b1 = b‘xc3xf7xccxec‘ # gbk的bytes 2 s2 = b1.decode(‘gbk‘) 3 print(s2) # 明天
本文大量引用的地址为:
http://www.cnblogs.com/jin-xin/articles/9439483.html#4039042
以上是关于Python 代码块 小数据池的主要内容,如果未能解决你的问题,请参考以下文章