python基础-面向对象高级编程
Posted 雲淡風輕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python基础-面向对象高级编程相关的知识,希望对你有一定的参考价值。
Python允许使用多重继承,因此,MixIn就是一种常见的设计。
只允许单一继承的语言(如Java)不能使用MixIn的设计
如果查看内置函数的源码?比如len()的源码,为什么一个对象可以使用len()就必须在该对象的类的内部定义__len__方法
枚举类 Enum
@unique装饰器可以帮助我们检查保证没有重复值。
创建对象即创建对象过程
使用type()创建一个class对象,依次传入3个参数:(可以动态生成class)


type(\'Foo\',(object,), {\'func\': func})创建对象简单示例 def func(self): print \'hello wupeiqi\' Foo = type(\'Foo\',(object,), {\'func\': func}) #type第一个参数:类名 #type第二个参数:当前类的基类 #type第三个参数:类的成员 >>> def fn(self, name=\'world\'): # 先定义函数 ... print(\'Hello, %s.\' % name) ... >>> Hello = type(\'Hello\', (object,), dict(hello=fn)) # 创建Hello class >>> h = Hello() >>> h.hello() Hello, world. >>> print(type(Hello)) <class \'type\'> >>> print(type(h)) <class \'__main__.Hello\'>
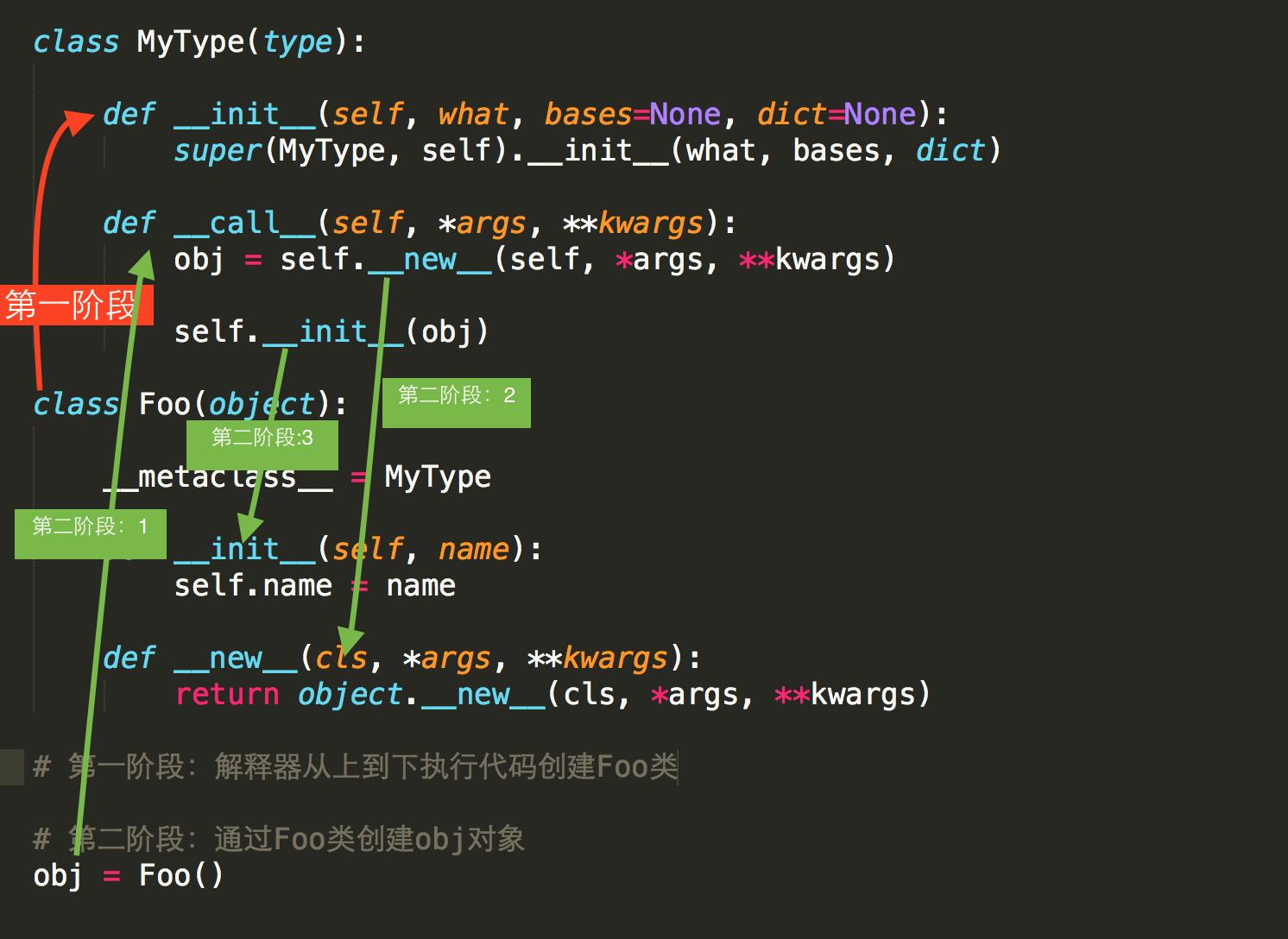
class MyType(type): def __init__(self, what, bases=None, dict=None): print(\'第一阶段 创建Foo类时被调用\', what, self) # 在MyType中,self就是MyType对象,即Foo类 # super(MyType, self).__init__(what, bases, dict)#简单的理解就是调用第一个参数的父类,第二个参数固定为self super().__init__(what, bases, dict) # 在python3中可以直接这样写 def __call__(self, *args, **kwargs): print(\'第二阶段\', self) obj = self.__new__(self, *args, **kwargs) # obj.__init__(*args, **kwargs) self.__init__(obj, *args, **kwargs) return obj \'\'\'创建类对象和创建普通对象一样,都是调用type的__call__方法,继而__call__方法依次调用__new__,__init__\'\'\' def __new__(cls, name, bases, attrs): print(\'第一阶段 创建Foo类时被调用\') # print(cls, name, bases, attrs) return type.__new__(cls, name, bases, attrs) class Foo(object, metaclass=MyType): def __init__(self, name): # 在第二阶段被调用 print(\'在第二阶段被调用\', ) self.name = name def __new__(cls, *args, **kwargs): # 在第二阶段被调用 print(\'在第二阶段被调用\', ) obj = object.__new__(cls, ) # 在python3.5中,是不需要传入*args, **kwargs的,这和python2.7不同 return obj obj = Foo("allen") \'\'\' 第一阶段:创建Foo类 第二阶段:通过Foo类创建obj对象 总结:创建类和普通对象都一样,都是调用type的__call__方法,继而__call__方法依次调用__new__、__init__; __new__返回对象(那么当然可以在__new__方法中为对象附加属性)、__init__初始化对象 创建类调用type的__new__方法,创建普通对象,调用继承的父类的__new__方法 (或者说都是调用父类的__new__方法,只不过当__new__方法是从type中继承时,调用type形式的__new__方法 当__new__方法是从object中继承时,调用的是object形式的__new__方法) “__new__”方法在Python中是真正的构造方法(创建并返回实例),通过这个方法可以产生一个”cls”对应的实例对象,所以说” __new__”方法一定要有返回 对于”__init__ “方法,是一个初始化的方法,“self”代表由类产生出来的实例对象,” __init__”将对这个对象进行相应的初始化操作 https://blog.csdn.net/brucewong0516/article/details/79124550 \'\'\' \'\'\' help(type) class type(object) | type(object_or_name, bases, dict) | type(object) -> the object\'s type | type(name, bases, dict) -> a new type \'\'\' print(type) # <class \'type\'> print(object) # <class \'object\'> print(isinstance(type, object)) # True print(isinstance(object, type)) # True print(issubclass(type, object)) # True print(issubclass(object, type)) # False print(type(type)) # <class \'type\'> print(type(object)) # <class \'type\'>
下图应该是python2.7的,python3已经有所不同。但示意的路径基本是正确的。
class super(object) | super(type, obj) -> bound super object; requires isinstance(obj, type) | super(type) -> unbound super object | super(type, type2) -> bound super object; requires issubclass(type2, type) https://blog.csdn.net/sunwukong_hadoop/article/details/80175292 http://www.cnblogs.com/testview/p/4651198.html?utm_source=tuicool&utm_medium=referral super()#没有钻石继承问题时,可以直接这样写。有钻石继承问题时,这么写会不会有错误呢?? super(type, obj) super(Leaf, self).__init__()的意思是说: 获取self所属类的mro, 也就是[Leaf, Medium1, Medium2, Base] 从mro中Leaf右边的一个类开始,依次寻找__init__函数。这里是从Medium1开始寻找 一旦找到,就把找到的__init__函数绑定到self对象,并返回 从这个执行流程可以看到,如果我们不想调用Medium1的__init__,而想要调用Medium2的__init__,那么super应该写成:super(Medium1, self)__init__() super(Leaf, cls).__new__(cls)的意思是说: 获取cls这个类的mro,这里也是[Leaf, Medium1, Medium2, Base] 从mro中Leaf右边的一个类开始,依次寻找__new__函数 一旦找到,就返回“非绑定”的__new__函数
单例模式存在的目的是保证当前内存中仅存在单个实例,避免内存浪费!!!
class Foo(object): __instance__ = None def __new__(cls, *args, **kwargs): if cls.__instance__: return cls.__instance__ else: # cls.__instance__ = Foo() #这时就不能用这种形式了,有死循环 cls.__instance__ = object.__new__(cls) return cls.__instance__ obj1 = Foo() # 这种对象获取方式更熟悉一些 obj2 = Foo() print(obj1, obj2)
class Foo(object): __instance__ = None @classmethod def instance(cls): if cls.__instance__: return cls.__instance__ else: cls.__instance__ = Foo() # cls.__instance__ = object.__new__(cls) return cls.__instance__ obj1 = Foo.instance() #这种方法获取对象需要通过类使用类方法 obj2 = Foo.instance() print(obj1,obj2)
(1) 在__init__.py文件中 表示形式: __all__=["module_a","module_b"] 在使用 from package_name import * 时 , 表示import 该package 中的 两个module及 两个module相关的类、方法等。 (2) 在普通的*.py中 表示形式: __all__=["class_name","function_name"] 在使用 from module_name import * 时,表示import 该module中的__all__中所列出的。 使用注意事项: (1) 在普通的*.py中, 使用__all__ 时,可以使用__all__列出的 类、函数、变量等,不使用__all__时会使用module中的所有不以下划线开头的成员。 (2)__all__只能影响到 from import * 这种import 方式, 对于from import 的 import 方式没有影响。 (3) __all__ 的数据类型:List or Tuple (不确定, 待验证其他) __all__暴露接口用的”白名单“,from module_name import *时生效 __all__ 也是对于模块公开接口的一种约定,比起下划线,__all__ 提供了暴露接口用的”白名单“。一些不以下划线开头的变量(比如从其他地方 import 到当前模块的成员)可以同样被排除出去。
__init__,构造方法,通过类创建对象时,自动触发执行。 __del__,析构方法,当对象在内存中被释放时,自动触发执行。 __call__ 对象后面加括号,触发执行。对象()就会调用__call__方法,注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()() __slots__,可以来限制该class实例能添加的属性;该属性不能被继承 __metaclass__,其用来指定该类由 谁 来实例化创建 __new__,是用于生成实例化对象的(被定义为静态方法,至少需要传递一个参数cls,cls表示需要实例化的类);本身是一个类方法,先于__init__()执行,返回一个实例,可以改变实例化行为 __module__ 表示当前操作的对象在那个模块 __class__ 表示当前操作对象的类是什么----或者说:是由哪个类来生成这个对象的,貌似和type()一模一样 __bases__ 表示该类的父类是什么 __name__,返回该对象的原始name,特殊:py文件.__name__,直接运行该py文件时,__name__ == __main__ __doc__,用于访问模块定义的文档注释;表示类的描述信息 __dict__,以字典的形式返回类或对象中的所有成员 __dir__,当对对象使用dir()时,若对象有方法__dir__(),则调用该方法。如果没有,则最大限度地手机该对象的信息:(dir([object])函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。返回一个包含字符串的list) __file__ 是用来获得模块所在的路径的,这可能得到的是一个相对路径 __len__,定义__len__后,该类的对象才可以正确使用len() __str__,打印对象时,默认打印的是__repr__的返回值;设置__str__后,print(对象)则执行__str__方法,打印__str__的返回值 __repr__, 在命令行调试时,输入对象,默认输出的是对象的信息及内存地址 __str__()返回用户看到的字符串,而__repr__()返回程序开发者看到的字符串,也就是说,__repr__()是为调试服务的。 __iter__,如果一个类想被用于for ... in循环,就必须实现一个__iter__()方法,该方法返回一个迭代对象 __next__,调用该迭代对象的循环的下一个值,直到遇到StopIteration错误时退出循环。 __getitem__,要表现得像list那样按照下标取出元素及切片功能,需要实现__getitem__()方法; __setitem__,把对象视作list或dict来对集合赋值。 __delitem__,用于删除某个元素。 __getslice__、__setslice__、__delslice__ 该三个方法用于分片操作,如:列表 obj[-1:1] # 自动触发执行 __getslice__ obj[0:1] = [11,22,33,44] # 自动触发执行 __setslice__ del obj[0:2] # 自动触发执行 __delslice__ 实现类之间的大小比较 __lt__()<; __le__()<=; __gt__()>; __ge__()>=; __eq__()=; __ne__()!= __enter__() and __exit__() 实例方法,用于使实例支持上下文管理(with as). 前者在开始时调用必须返回实例对象self, 后者在结束或者产生错误时调用,__exit__()的参数中exc_type, exc_value, traceback用于描述异常 __getattr__,当调用对象不存在的属性时,Python解释器会试图调用__getattr__(self, \'不存在属性\')来尝试获得属性 利用完全动态的__getattr__,我们可以写出一个链式调用: class Chain(object): def __init__(self, path=\'\'): self._path = path def __getattr__(self, path): return Chain(\'%s/%s\' % (self._path, path)) def __str__(self): return self._path __repr__ = __str__ >>> Chain().status.user.timeline.list \'/status/user/timeline/list\' 要学会拓展,__mappings__应该指的映射关系;__table__数据库的表名?
廖雪峰-面向对象高级编程-使用元类-metaclass及自定义ORM框架-待复习
http://www.cnblogs.com/wupeiqi/p/4766801.html
https://www.cnblogs.com/maskice/p/6493404.html (查漏补缺)
以上是关于python基础-面向对象高级编程的主要内容,如果未能解决你的问题,请参考以下文章