python 爬虫新解
Posted 草木同朽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬虫新解相关的知识,希望对你有一定的参考价值。
关于python爬虫多个库的选择反反复复,总是不知道选择哪个,通过试过多个晚上的选择
- reques
- Beautifulsoup
以上两个库足够爬虫,已反爬虫网站数据的爬取。先上代码:
- 库的调用:

- 网页链接获取:
url=\'**********************\'
- 网页reques headers构建,主要是反爬虫网站的伪装,获取地址在network中的XHR中的request headers的User-Agent,如下所示:(任何一个json文件都可以)
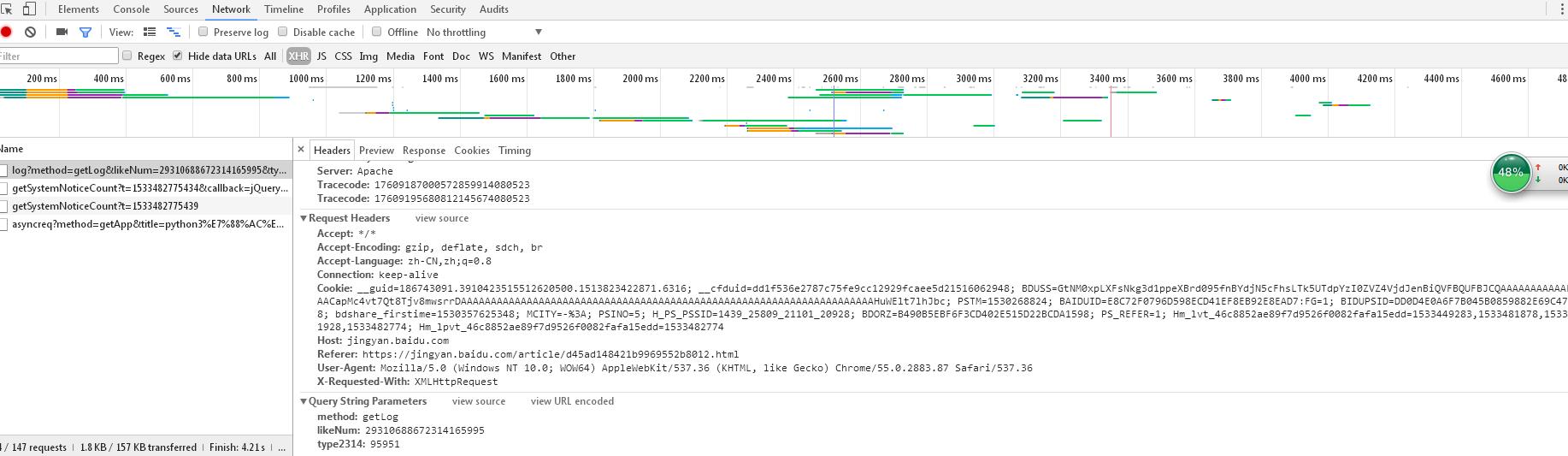
- 具体代码自己根据css或者是HTML格式去获取,正则表达式后面更新,个人具体代码如下所示:

- 输出如下所示:

以上是关于python 爬虫新解的主要内容,如果未能解决你的问题,请参考以下文章