Python数据分析库pandas ------ pandas
Posted 巴蜀秀才
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析库pandas ------ pandas相关的知识,希望对你有一定的参考价值。
数据转换
删除重复元素
DataFrame对象的duplicated()函数可用来检测重复的行,返回元素为布尔型的Series对象。 每个元素对
应一行,如果该行与其他行重复(也就是说该行不是第一次出现),则元素为True; 如果跟前面不重复,则元
素就为False。
返回元素为布尔值的Series对象用处很大,特别适用于过滤操作。通常,所有重复的行都需要从DataFrame
对象中删除。pandas库的drop_duplicates()函数实现了删除功能,该函数返回的是删除重复行后的DataFmme对
象。
1 dframe = pd.DataFrame({ \'color\': [\'white\',\'white\',\'red\',\'red\',\'white\'],\'value\': [2,1,3,3,2]})
2 print(dframe)
3 print(dframe.duplicated())
4 # 返回元素为布尔值的Series对象用处很大,特别适用于过滤操作。
5 print( dframe[dframe.duplicated()])
6 print(dframe.drop_duplicates())
7 输出:
8 color value
9 0 white 2
10 1 white 1
11 2 red 3
12 3 red 3
13 4 white 2
14 0 False
15 1 False
16 2 False
17 3 True
18 4 True
19 dtype: bool
20 color value
21 3 red 3
22 4 white 2
23 color value
24 0 white 2
25 1 white 1
26 2 red 3
用映射替换元素
要用新元素替换不正确的元素,需要定义一组映射关系。在映射关系中,旧元素作为键,新元素作为值。
DataFrame对象中两种旧颜色被替换为正确的元素。还有一种常见情况,是把NaN替换为其他值,比如0。
这种情况下,仍然可以用replace()函数,它能优雅地完成该项操作。
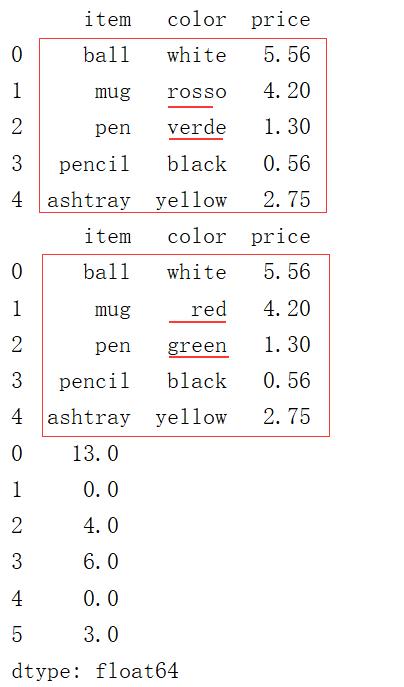
1 frame8 = pd.DataFrame({
2 \'item\': [\'ball\', \'mug\', \'pen\', \'pencil\', \'ashtray\'],
3 \'color\': [\'white\', \'rosso\', \'verde\', \'black\', \'yellow\'],
4 \'price\': [5.56, 4.20, 1.30, 0.56, 2.75]
5 })
6 print(frame8)
7 newcolors = {
8 \'rosso\': \'red\',
9 \'verde\': \'green\'
10 }
11 print(frame8.replace(newcolors))
12
13 ser = pd.Series([13, np.nan, 4, 6, np.nan, 3])
14 print(ser.replace(np.nan, 0))
输出结果:
用映射添加元素
下面只是部分功能的展示,详情请参考官方文档。
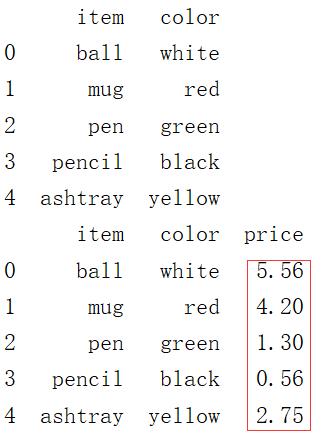
1 frame9 = pd.DataFrame({
2 \'item\':[\'ball\',\'mug\',\'pen\',\'pencil\',\'ashtray\'],
3 \'color\':[\'white\',\'red\',\'green\',\'black\',\'yellow\']
4 })
5 print(frame9)
6 price = {
7 \'ball\' : 5.56,
8 \'mug\' : 4.20,
9 \'bottle1\' : 1.30,
10 \'scissors\' : 3.41,
11 \'pen\' : 1.30,
12 \'pencil\' : 0.56,
13 \'ashtray\' : 2.75
14 }
15 frame9[\'price\'] = frame9[\'item\'].map(price) # 这里是按‘item’的对应关系添加
16 print(frame9)
输出结果:
官方文档案例:
1 df = pd.DataFrame({
2 \'A\': [\'bat\', \'foo\', \'ibat\'],
3 \'B\': [\'abc\', \'bar\', \'xyz\']
4 })
5 # r\'^ba.$\'是匹配最后三个字符中前面量为ba的;$匹配结尾的
6 print(df.replace(to_replace=r\'^ba.$\', value=\'new\', regex=True))
输出结果:(上面关于正则的知识点请点击参考博客)

重命名轴索引
对于只有单个元素要替换的最简单情况,可以对传入的参数做进一步限定,而无需把多个变 量都写出来,
也避免产生多次赋值操作。对于多个元素替换最好用字典先写好。
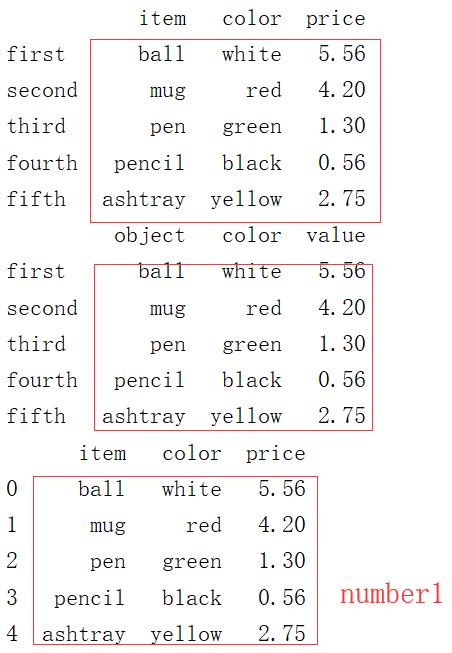
1 reindex = {
2 0:\'first\',
3 1:\'second\',
4 2:\'third\',
5 3:\'fourth\',
6 4:\'fifth\'
7 }
8 print(frame9.rename(reindex))
9 recolumn ={
10 \'item\':\'object\',
11 \'price\':\'value\'
12 }
13 print(frame9.rename(index=reindex,columns=recolumn)) # 不会改变原数据frame9
14 print(frame9)
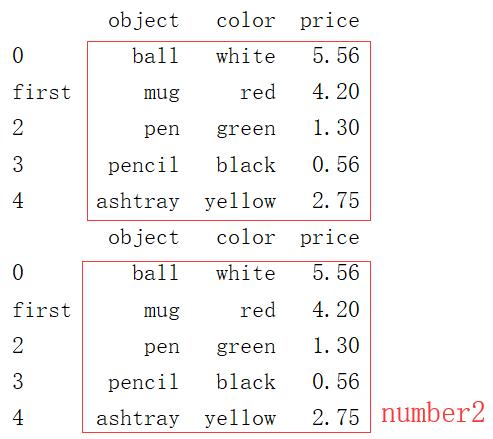
15 print(frame9.rename(index={1:\'first\'},columns={\'item\':\'object\'}))
16 # inplace=True用于指定在原数据frame9上面改
17 frame9.rename(index={1:\'first\'},columns={\'item\':\'object\'},inplace=True)
18 print(frame9)
输出结果:
离散化和面元划分
每个面元的出现次数,即每个类别有多少个元素,可使用value_counts()函数。
cut 是等差划分面元, qcut 是根据分位数划分面元。
1 ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
2 bins = [18, 25, 35, 60, 100]
3 # cut(x, bins, right=True, labels=None, retbins=False, precision=3,
4 # include_lowest=False, duplicates=\'raise\')
5 cat = pd.cut(ages, bins)
6 print(cat, "\\n-----* 1 *-----\\n")
7 # cat.codes 输出每个元素对应的面元编码
8 print(cat.codes, "\\n-----* 2 *-----\\n")
9 print(pd.value_counts(cat), "\\n-----* 3 *-----\\n") # 查看每个面元中元素的数量
10 cuts = pd.cut(ages, bins, right=False) # 使用right=False可以修改开端和闭端
11 print(cuts, "\\n-----* 4 *-----\\n")
12 cut1 = pd.cut(ages, bins, right=False, labels=list(\'abcd\'))
13 print(cut1, "\\n-----* 5 *-----\\n")
14
15 print(pd.cut(ages, 5), "\\n-----* 6 *-----\\n") # 如果cut传入的是数字n,那么就会均分成n份。
16 print(pd.value_counts(pd.cut(ages, 4)), "\\n-----* 7 *-----\\n")
17 # qcut
18 # qcut(x, q, labels=None, retbins=False, precision=3, duplicates=\'raise\')
19 # 基于分位数的离散化函数。将变量离散成
20 # 基于等级或基于样本分位数的相等大小的面元。
21 print(pd.qcut(ages, 5), "\\n-----* 8 *-----\\n")
22 print(pd.value_counts(pd.qcut(ages, 4)), "\\n-----* 9 *-----\\n")
输出结果:



异常值检测和过滤
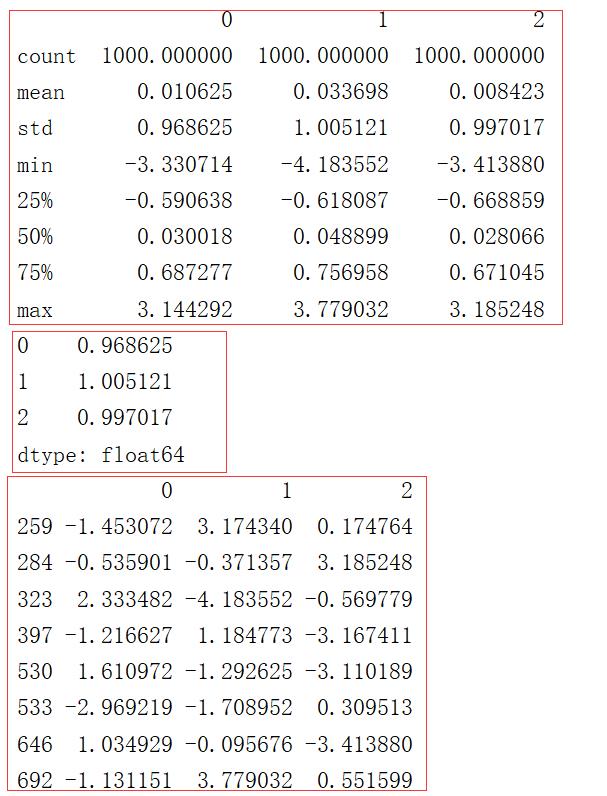
假设将比标准差大3倍的元素视作异常值。用std()函数就可以求得DataFrame对象每一列的标准差。
1 data = pd.DataFrame(np.random.randn(1000,3))
2 print(data.describe())
3 print(data.std())
4 print(data[(np.abs(data)>(3*data.std())).any(1)]) # 过滤条件 any(1)只要有一个大于3*sigma就满足条件
排序
1 nframe = pd.DataFrame(np.arange(25).reshape(5,5))
2 new_order = np.random.permutation(5) #乱序整数[0-4] 如果是100 [0-99]
3 print(nframe.take(new_order)) #排序
4 print(np.random.permutation(100))
5 print(nframe.take([3,4,2])) #只对一部分排序
6 sample = np.random.randint(len(nframe),size =3) #随机整数
7 print(nframe.take(sample))
输出结果:

以上是关于Python数据分析库pandas ------ pandas的主要内容,如果未能解决你的问题,请参考以下文章