python爬虫之新浪微博登录
Posted purplelavender
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之新浪微博登录相关的知识,希望对你有一定的参考价值。
fiddler 之前了解了一些常见到的反爬措施,JS加密算是比较困难,而微博的登录中正是用JS加密来反爬,今天来了解一下。
分析过程
首先我们去抓包,从登录到微博首页加载出来的过程。我们重点关注一下登录操作,其次是首页的请求,登录一般是POST请求。我们搜索一下:

得知登录的url为https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.19),然后点击WebForms菜单查看参数:
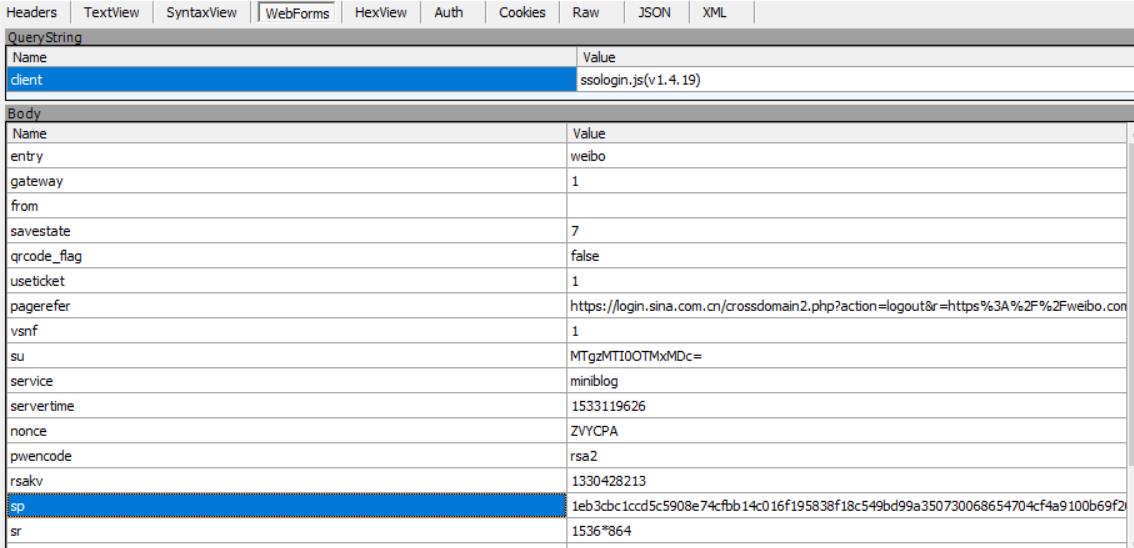
里面有很多参数要提交,一般的参数的值有3种情况:
- 参数值固定。一般我们多次抓包发现某个参数值不变,就认为是固定的;
- 参数值来自于之前服务器的响应。多次抓包发现参数值变化,此时我们可以把参数的值在fiddler中查找一下,看看能否在之前的响应中找到。例如这里的nonce、rsakv、servertime
- 参数值来自于js生成。如果多次抓包参数的值既不是固定,也不能在之前的响应中找到,那么最可能的结果是这个参数的值是由js代码生成。
我们在fiddler中查找nonce:

发现有一个前面的请求高亮了,说明这个参数之前就出现过。点击这个请求,在响应里查找这个值:
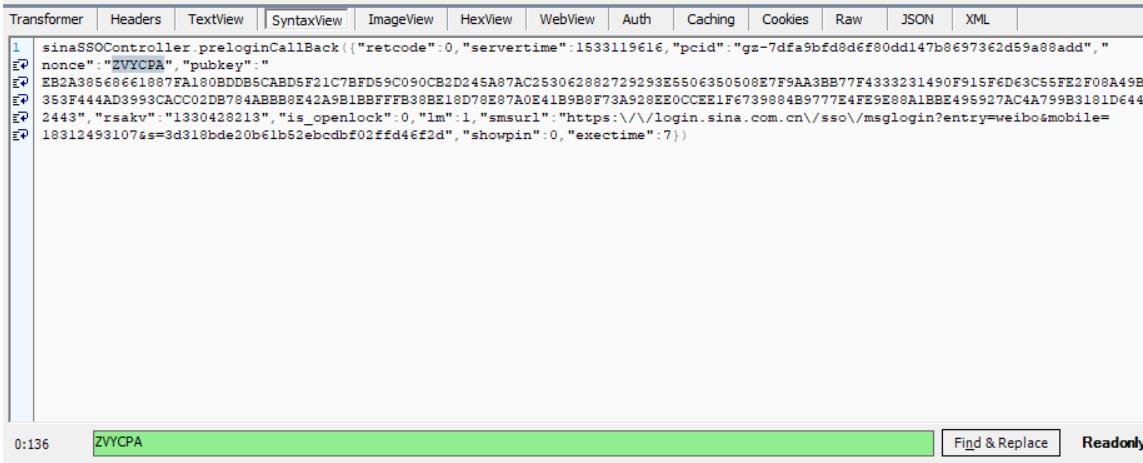
可以找到这个参数,所以我们要想登录,就得获取nonce的值,而要获取nonce的值,就要先请求这个找到的请求,这个请求的url为https://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=MTgzMTI0OTMxMDc%3D&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.19)&_=1533119627438,url中的su在后面会讲到,最后那个参数看起来像时间戳,我们可以先用时间戳模拟一下。而servertime、rsakv等必须的参数也都可以在这个响应中找到。
现在我们解决了大部分参数的问题,但是有两个难啃的骨头:sp和su,这两个值在之前的响应中找不到。而且我们会发现,我们登录输入的账号和密码没有出现在这些参数中,我们大胆猜测:su和sp就是账号和密码!那么我们怎么找到它们的值呢。答案是找到相应的JS代码,并用python重写它。
现在我们的难题到了怎么定位这俩个值的JS代码,我们之前学习Chrome调试的时候,学会了打断点,这个地方正是用断点的方式来找。我们每次登录都要点击页面的“登录”按钮,我们在填写完账号密码后,设置一个点击事件的断点,然后点击登录。这样请求在进行登录的时候会暂停,而su和sp参数也是这个时候被加密!

然后,我们用调试界面右上角的 这些功能键进行逐步分析。
这些功能键进行逐步分析。
注意:一般只是赋值的操作,我们可以跳过,如果是函数的执行,我们要到函数里面去看,特别是函数的参数是携带重要参数,要重点关注。在控制台界面,我们还可以查看某些参数的值。

另外,如果退出某个函数后,光标仍在这一行,说明这一行还有个函数,切不可直接下一步,很多关键信息就在这个函数里。
微博登录的JS定位过程就不细说了,我们最后定位到su和sp加密代码如下:
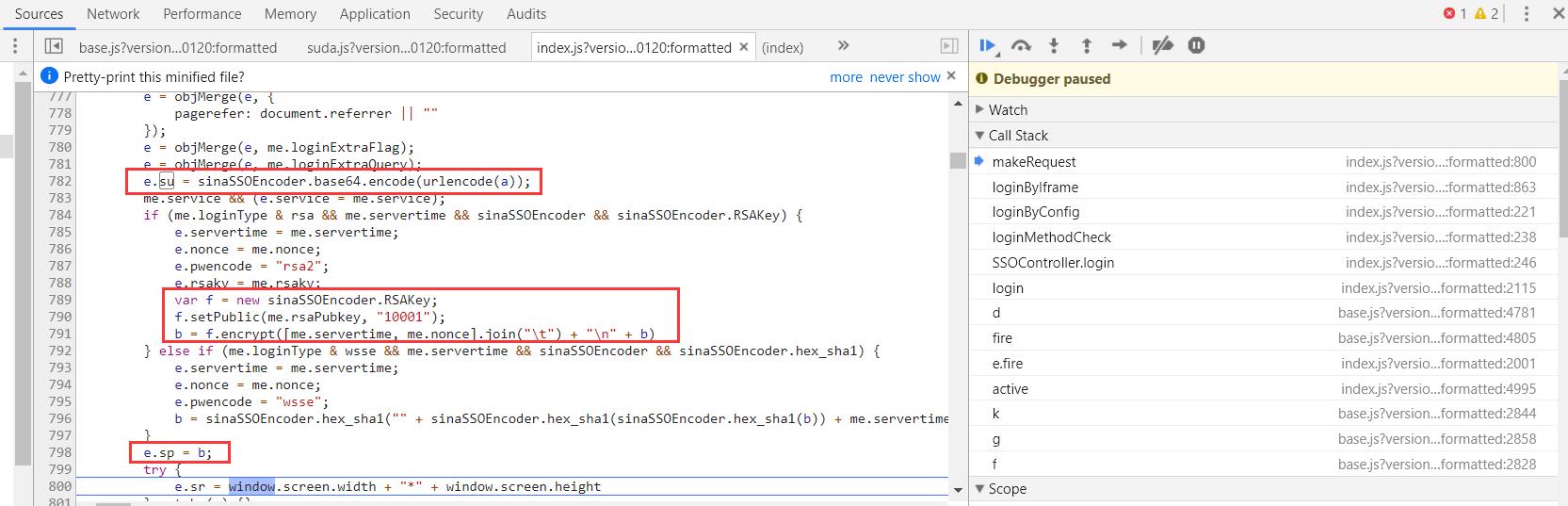
即su是用base64进行了编码,而sp是用rsa加密,我们把js代码用python代码实现即可。
目前,登录的问题解决了。现在看看请求首页的问题。我们逐个查看,可以知道首页的请求如下:
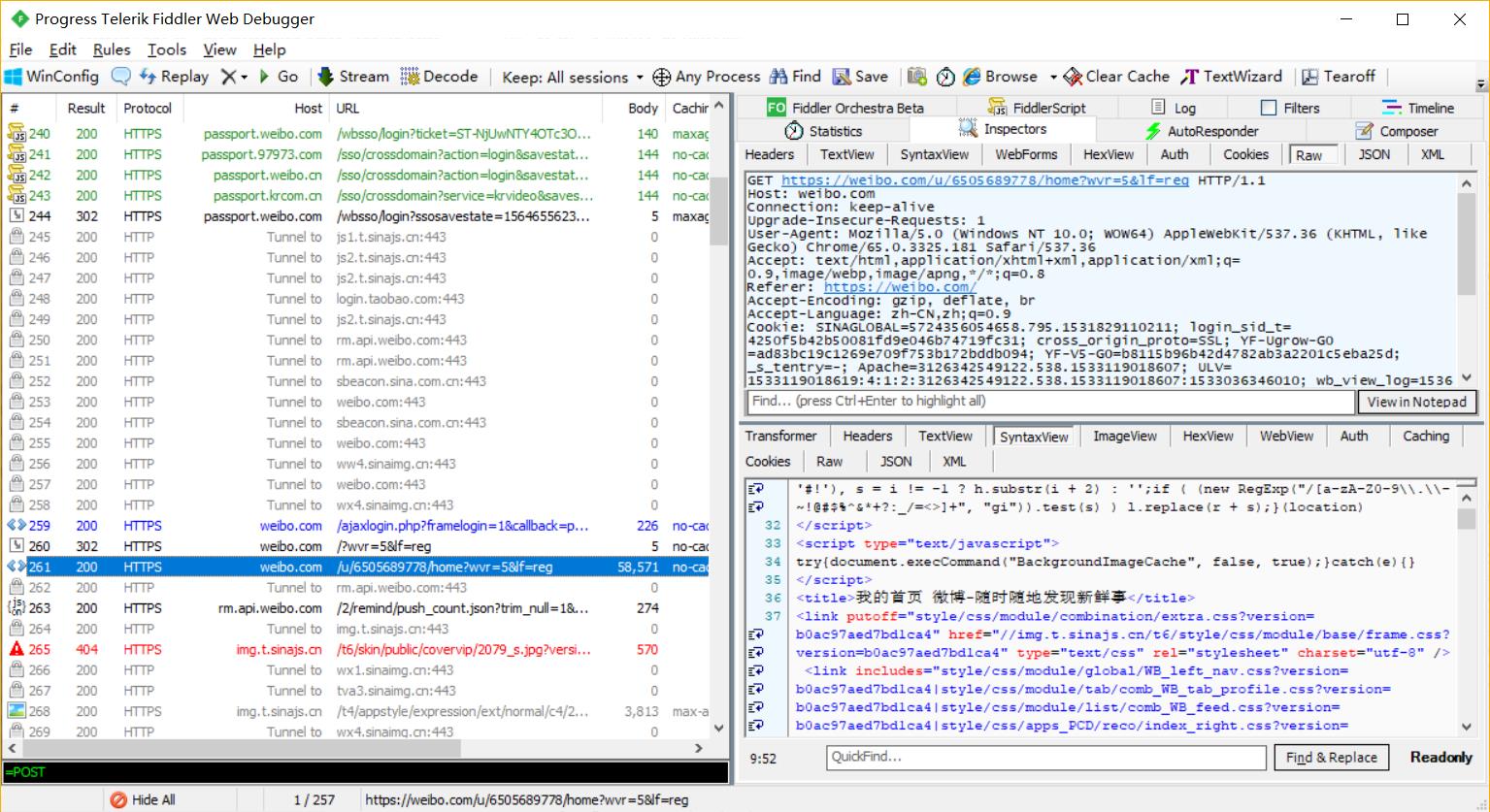
url为https://weibo.com/u/6505689778/home?wvr=5&lf=reg,而这个url里有个6505689778,这个值我们在fiddler中查找,在请求https://passport.weibo.com/wbsso/login?ticket=ST-NjUwNTY4OTc3OA%3D%3D-1533119623-gz-0DEAF5775E6F1D983147B0B96EE915B9-1&ssosavestate=1564655623&callback=sinaSSOController.doCrossDomainCallBack&scriptId=ssoscript0&client=ssologin.js(v1.4.19)&_=1533119634900的响应里能找到它的。
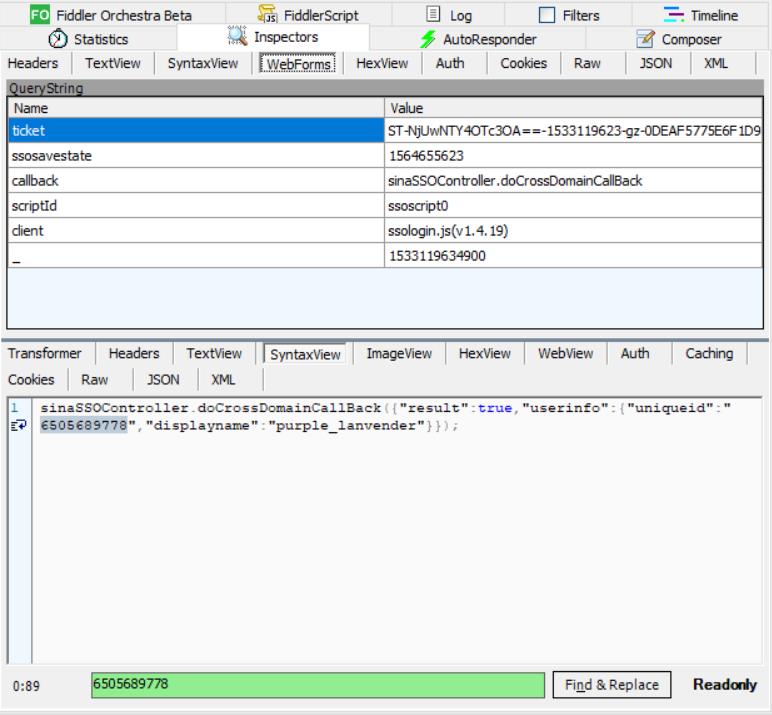
而请求这个页面,又要获取参数ticket、ssosavestate的值,我们再次查找,可以知道这两个值在另一个请求https://login.sina.com.cn/crossdomain2.php?action=login&entry=weibo&r=https%3A%2F%2Fpassport.weibo.com%2Fwbsso%2Flogin%3Fssosavestate%3D1564655623%26url%3Dhttps%253A%252F%252Fweibo.com%252Fajaxlogin.php%253Fframelogin%253D1%2526callback%253Dparent.sinaSSOController.feedBackUrlCallBack%2526sudaref%253Dweibo.com%26display%3D0%26ticket%3DST-NjUwNTY4OTc3OA%3D%3D-1533119623-gz-39B6B6D3D3979D6DA2860B54E4E61A01-1%26retcode%3D0&login_time=1533119622&sign=0db5e9f42ceb691c&sr=1536%2A864的响应里。
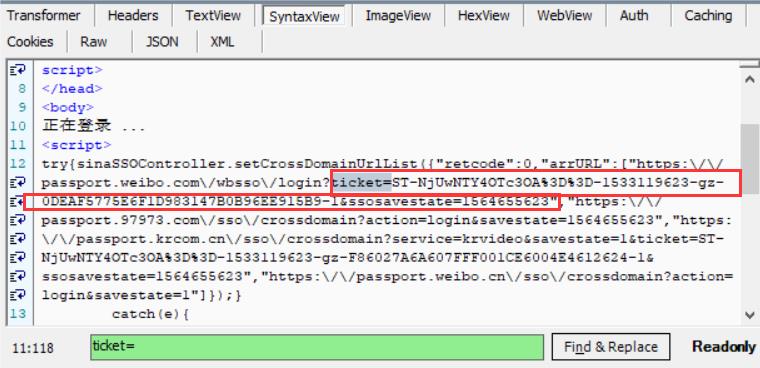
那么这个很长的url怎么来的呢,我们再次查找,可以得知它就在登录之后响应里。

到了这里,步骤已经走通了!
我们理一下步骤:
1、先把账号、密码加密后的密文得到
2、请求https://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=MTgzMTI0OTMxMDc%3D&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.19)&_=1533119627438得到nonce、rsakv等参数
3、构造参数并请求登录的url:https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.19),在响应里得到跳转的url
4、请求跳转的url:https://login.sina.com.cn/crossdomain2.php?action=login&entry=weibo&r=https%3A%2F%2Fpassport.weibo.com%2Fwbsso%2Flogin%3Fssosavestate%3D1564655623%26url%3Dhttps%253A%252F%252Fweibo.com%252Fajaxlogin.php%253Fframelogin%253D1%2526callback%253Dparent.sinaSSOController.feedBackUrlCallBack%2526sudaref%253Dweibo.com%26display%3D0%26ticket%3DST-NjUwNTY4OTc3OA%3D%3D-1533119623-gz-39B6B6D3D3979D6DA2860B54E4E61A01-1%26retcode%3D0&login_time=1533119622&sign=0db5e9f42ceb691c&sr=1536%2A864,得到ticket、ssosavestate参数的值
5、请求https://passport.weibo.com/wbsso/login?ticket=ST-NjUwNTY4OTc3OA%3D%3D-1533119623-gz-0DEAF5775E6F1D983147B0B96EE915B9-1&ssosavestate=1564655623&callback=sinaSSOController.doCrossDomainCallBack&scriptId=ssoscript0&client=ssologin.js(v1.4.19)&_=1533119634900得到uniqueid参数
6、请求首页:https://weibo.com/u/6505689778/home?wvr=5&lf=reg
OK,至此,我们已成功登录了微博,后面你要获取微博上的数据,可以自行请求。
实现代码
import requests import rsa import time import re import random import urllib3 import base64 from urllib.parse import quote from binascii import b2a_hex urllib3.disable_warnings() # 取消警告 def get_timestamp(): return int(time.time()*1000) # 获取13位时间戳 class WeiBo(): def __init__(self,username,password): self.username = username self.password = password self.session = requests.session() #登录用session self.session.headers={ \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36\' } self.session.verify = False # 取消证书验证 def prelogin(self): \'\'\'预登录,获取一些必须的参数\'\'\' self.su = base64.b64encode(self.username.encode()) #阅读js得知用户名进行base64转码 url = \'https://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su={}&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.19)&_={}\'.format(quote(self.su),get_timestamp()) #注意su要进行quote转码 response = self.session.get(url).content.decode() # print(response) self.nonce = re.findall(r\'"nonce":"(.*?)"\',response)[0] self.pubkey = re.findall(r\'"pubkey":"(.*?)"\',response)[0] self.rsakv = re.findall(r\'"rsakv":"(.*?)"\',response)[0] self.servertime = re.findall(r\'"servertime":(.*?),\',response)[0] return self.nonce,self.pubkey,self.rsakv,self.servertime def get_sp(self): \'\'\'用rsa对明文密码进行加密,加密规则通过阅读js代码得知\'\'\' publickey = rsa.PublicKey(int(self.pubkey,16),int(\'10001\',16)) message = str(self.servertime) + \'\\t\' + str(self.nonce) + \'\\n\' + str(self.password) self.sp = rsa.encrypt(message.encode(),publickey) return b2a_hex(self.sp) def login(self): url = \'https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.19)\' data = { \'entry\': \'weibo\', \'gateway\': \'1\', \'from\':\'\', \'savestate\': \'7\', \'qrcode_flag\': \'false\', \'useticket\': \'1\', \'pagerefer\': \'https://login.sina.com.cn/crossdomain2.php?action=logout&r=https%3A%2F%2Fweibo.com%2Flogout.php%3Fbackurl%3D%252F\', \'vsnf\': \'1\', \'su\': self.su, \'service\': \'miniblog\', \'servertime\': str(int(self.servertime)+random.randint(1,20)), \'nonce\': self.nonce, \'pwencode\': \'rsa2\', \'rsakv\': self.rsakv, \'sp\': self.get_sp(), \'sr\': \'1536 * 864\', \'encoding\': \'UTF - 8\', \'prelt\': \'35\', \'url\': \'https://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack\', \'returntype\': \'META\', } response = self.session.post(url,data=data,allow_redirects=False).text # 提交账号密码等参数 redirect_url = re.findall(r\'location.replace\\("(.*?)"\\);\',response)[0] # 微博在提交数据后会跳转,此处获取跳转的url result = self.session.get(redirect_url,allow_redirects=False).text # 请求跳转页面 ticket,ssosavestate = re.findall(r\'ticket=(.*?)&ssosavestate=(.*?)"\',result)[0] #获取ticket和ssosavestate参数 uid_url = \'https://passport.weibo.com/wbsso/login?ticket={}&ssosavestate={}&callback=sinaSSOController.doCrossDomainCallBack&scriptId=ssoscript0&client=ssologin.js(v1.4.19)&_={}\'.format(ticket,ssosavestate,get_timestamp()) data = self.session.get(uid_url).text #请求获取uid uid = re.findall(r\'"uniqueid":"(.*?)"\',data)[0] print(uid) home_url = \'https://weibo.com/u/{}/home?wvr=5&lf=reg\'.format(uid) #请求首页 html = self.session.get(home_url) html.encoding = \'utf-8\' print(html.text) def main(self): self.prelogin() self.get_sp() self.login() if __name__ == \'__main__\': username = \'xxxxxxxxx\' # 微博账号 password = \'xxxxxxxxx\' # 微博密码 weibo = WeiBo(username,password) weibo.main()
结果:
以上是关于python爬虫之新浪微博登录的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫开源项目代码,爬取微信淘宝豆瓣知乎新浪微博QQ去哪网等 代码整理
新浪微博python爬虫分享(一天可抓取 1300 万条数据),超级无敌