python基础二
Posted xihuxiangri
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python基础二相关的知识,希望对你有一定的参考价值。
一 基本数据类型
1 int 数字
#bit_length() 当十进制用二进制表示时,最少使用的位数 v = 11 data = v.bit_length() print(data)
2 bool 布尔值
布尔值就两种:True,False。就是反应条件的正确与否。
真 1 True。
假 0 False。
3 str 字符串
3.1 字符串的索引与切片。
索引即下标,就是字符串组成的元素从第一个开始,初始索引为0以此类推。
a = ‘我们都有一个家,名字叫中国‘ print(a[0]) print(a[3]) print(a[5]) print(a[7])
切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串(原则就是顾头不顾尾)。
s = "伊丽莎白鼠的溜肥肠还有挖掘机" #切片 [起始位置: 结束位置] 1.顾头不顾尾, 2.从左往右切 print(s[1:3]) # 从1切到3. 但是取不到3 [1,3) print(s[1:]) # 从1开始切. 切到结尾 print(s[:2]) # 从头切到2 print(s[:]) # 从头到尾 print(s[-3:-1]) # 只能从左往右切
注意;步长:如果是整数或者没写,则从左往右获取:如果是负数,则从右往左获取,默认是1
切片语法:str[start:end:step]
start:起始位置,
end:结束位置
step:步长
3.2 字符串常用方法。
#captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg=‘egon say hi‘ print(msg.title()) #每个单词的首字母大写 # 内同居中,总长度,空白处填充 ret2 = a1.center(20,"*") print(ret2) #数字符串中的元素出现的个数。 # ret3 = a1.count("a",0,4) # 可切片 # print(ret3) a2 = "hqw " # 前面的补全 # 默认将一个tab键变成8个空格,如果tab前面的字符长度不足8个,则补全8个,如果tab键前面的字符长度超过8个不足16个则补全16个,以此类推每次补全8个。 ret4 = a2.expandtabs() print(ret4) a4 = "dkfjdkfasf54" #startswith 判断是否以...开头 #endswith 判断是否以...结尾 # ret4 = a4.endswith(‘jdk‘,3,6) # 顾头不顾腚 # print(ret4) # 返回的是布尔值 # ret5 = a4.startswith("kfj",1,4) # print(ret5) #寻找字符串中的元素是否存在 # ret6 = a4.find("fjdk",1,6) # print(ret6) # 返回的找到的元素的索引,如果找不到返回-1 # ret61 = a4.index("fjdk",4,6) # print(ret61) # 返回的找到的元素的索引,找不到报错。 #split 以什么分割,最终形成一个列表此列表不含有这个分割的元素。 # ret9 = ‘title,Tilte,atre,‘.split(‘t‘) # print(ret9) # ret91 = ‘title,Tilte,atre,‘.rsplit(‘t‘,1) # print(ret91) #format的三种玩法 格式化输出 res=‘{} {} {}‘.format(‘egon‘,18,‘male‘) res=‘{1} {0} {1}‘.format(‘egon‘,18,‘male‘) res=‘{name} {age} {sex}‘.format(sex=‘male‘,name=‘egon‘,age=18) #strip name=‘*egon**‘ print(name.strip(‘*‘)) print(name.lstrip(‘*‘)) print(name.rstrip(‘*‘)) #replace name=‘alex say :i have one tesla,my name is alex‘ print(name.replace(‘aa‘,‘SB‘,1)) #####is系列 name=‘jinxin123‘ print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isdigit()) #字符串只由数字组成
isnumeric():可以进行中文识别
4 tuple 元组
元组被称为只读列表,即数据可以被查询,但不能被修改,所以,字符串的切片操作同样适用于元组。例:(1,2,3)("a","b","c")
元组俗称不可变的列表, 用( )表示,里面可以放任何类型的数据,可以查询,循环,切片.但是不可以改变.
如果元组只有一个元素(元素,)
tuple(3,)
空元组:tuple()
元组是一个可迭代对象,可使用for循环.
tu = ("马云","马化腾","雷军","异人夜") tu[0] = "呵呵" print(tu) 结果: File "E:/lx/00003.py", line 58, in <module> tu[0] = "呵呵" TypeError: ‘tuple‘ object does not support item assignment
tu = ("马云","马化腾","雷军","异人夜",["川普","pujing","金三胖",[1,2,3,4],"酋长"],"刘强东") tu[4][1] = tu[4][1].upper() print(tu) 结果: (‘马云‘, ‘马化腾‘, ‘雷军‘, ‘异人夜‘, [‘川普‘, ‘PUJING‘, ‘金三胖‘, [1, 2, 3, 4], ‘酋长‘], ‘刘强东‘)
5 list 列表
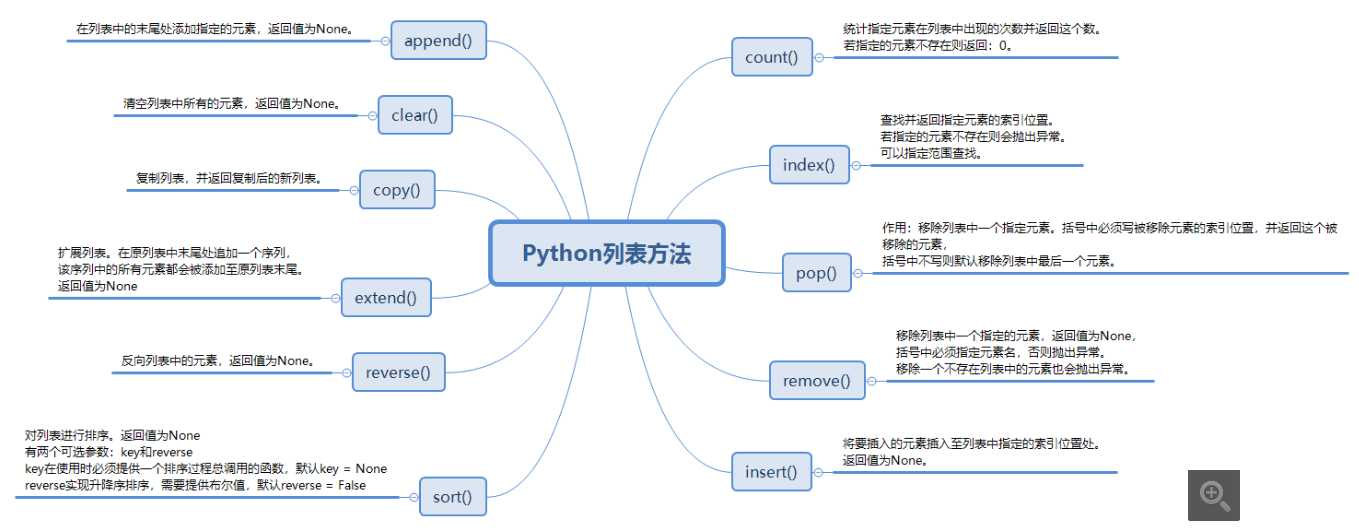
列表是python中的基础数据类型之一,其他语言中也有类似于列表的数据类型,比如js中叫数组,他是以[]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如:
li = [‘zhh’,123,Ture,(1,2,3,’zhangqiang’),[1,2,3,’小明’,],{‘name’:’lisi’}]
列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据,32位python的限制是 536870912 个元素,64位python的限制是 1152921504606846975 个元素。而且列表是有序的,有索引值,可切片,方便取值。
格式化输出

列表的增删改查
1增
append() 追加
insert(index, 元素) 在index位置添加元素
extend() 迭代添加
li = [1,‘a‘,‘b‘,2,3,‘a‘] # li.insert(0,55) #按照索引去增加 # print(li) # # li.append(‘aaa‘) #增加到最后 # li.append([1,2,3]) #增加到最后 # print(li) # # li.extend([‘q,a,w‘]) #迭代的去增 # li.extend([‘q,a,w‘,‘aaa‘]) # li.extend(‘a‘) # li.extend(‘abc‘) # li.extend(‘a,b,c‘) # print(li)
2删
pop(index) 按照位置删除元素
remove(元素) 直接删除元素
del 切片.
clear() 清空列表
# l1 = li.pop(1) #按照位置去删除,有返回值 # print(l1) # del li[1:3] #按照位置去删除,也可切片删除没有返回值。 # print(li) # li.remove(‘a‘) #按照元素去删除 # print(li) # li.clear() #清空列表
3 改
索引修改
切片修改
# 改 # li = [1,‘a‘,‘b‘,2,3,‘a‘] # li[1] = ‘dfasdfas‘ # print(li) # li[1:3] = [‘a‘,‘b‘] # print(li)
4. 查
for el in list:
el
lst = ["马化腾","马云","王健林","异人夜","刘强东"] for el in lst: #element(元素) print(el) 结果: 马化腾 马云 王健林 异人夜 刘强东
5 其他操作
count(数)(方法统计某个元素在列表中出现的次数)。
1 a = ["q","w","q","r","t","y"]
2 print(a.count("q"))
index(方法用于从列表中找出某个值第一个匹配项的索引位置)
1 a = ["q","w","r","t","y"] 2 print(a.index("r"))
sort (方法用于在原位置对列表进行排序)。
reverse (方法将列表中的元素反向存放)。
lst = [1,5,8,99,48,156,3,24,56] lst.sort() print(lst) lst.sort(reverse=True) print(lst) 结果; [1, 3, 5, 8, 24, 48, 56, 99, 156] [156, 99, 56, 48, 24, 8, 5, 3, 1]
lst = ["马云","马化腾","刘强东","雷军","异人夜"] lst.reverse() print(lst) 结果: [‘异人夜‘, ‘雷军‘, ‘刘强东‘, ‘马化腾‘, ‘马云‘]
6 列表的嵌套
lst = ["马云","马化腾","雷军","异人夜",["川普","pujing","金三胖",[1,2,3,4],"酋长"],"刘强东"] print(lst[2]) #找到雷军 print(lst[4][3][1]) #找到2 lst[4][1] = lst[4][1].upper() #将pujing变成大写,在放回去 print(lst) lst[4][0] = lst[4][0].replace("川普","特朗普") print(lst) #把川普换成特朗普 结果: 雷军 [‘马云‘, ‘马化腾‘, ‘雷军‘, ‘异人夜‘, [‘川普‘, ‘PUJING‘, ‘金三胖‘, [1, 2, 3, 4], ‘酋长‘], ‘刘强东‘] [‘马云‘, ‘马化腾‘, ‘雷军‘, ‘异人夜‘, [‘特朗普‘, ‘pujing‘, ‘金三胖‘, [1, 2, 3, 4], ‘酋长‘], ‘刘强东‘]
range
1. 使用range和for循环来获取列表中的索引.
for i in range(len(列表)):
i : 索引
列表[i] 元素
例:
lst = ("马云","马化腾","雷军","异人夜") #获取到列表的索引,拿到索引后,可以拿到元素. for i in range(len(lst)): print(i) #i就是lst的索引 print(lst[i]) 结果: 马化腾 雷军 异人夜
2.range可以进行切片
① .range(n) 从0到n-1
for i in range(10):
print(i)
②.range(m,n) 从m到n-1
③.range(m,n,q) 从m到n-1,每q个取1个
字典
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
字典(dictionary)是除列表意外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
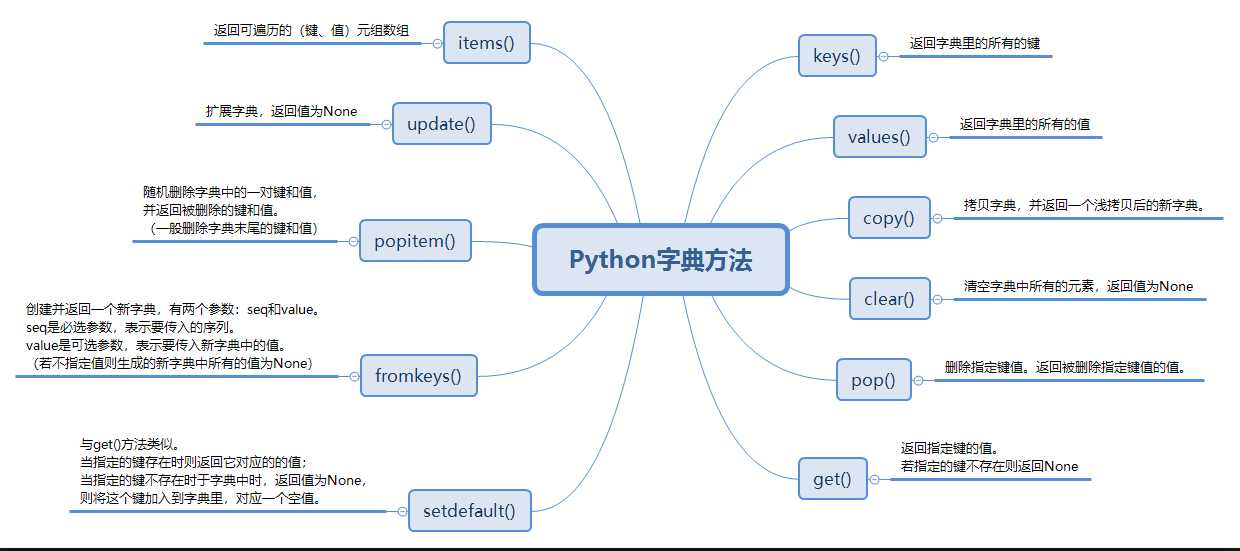
语法:
{key1:value,key2:value2....}
注意:key(键) 必须是不可变的(可哈希) , valve没有要求,可以是保存任何类型的数据.
增
dic[key] = value 在后面增加一个.
dic.setdefault(key,value) 如果键(key)在字典中不进行任何操作,不在则添加.
可以通过key进行查询,如果没有key返回None.
dic = {"猴子":"悟空","猪":"八戒","狗":"哮天犬","牛":"牛魔王"}
dic["大鹏"] = "浑天大圣" #在后面新增一个
print(dic)
dic.setdefault("蛟龙","覆海大圣")
print(dic)
dic.setdefault("猴子","悟空")
print(dic)
dic.setdefault("猴子","齐天大圣")
print(dic)
结果:
{‘猴子‘: ‘悟空‘, ‘猪‘: ‘八戒‘, ‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘, ‘大鹏‘: ‘浑天大圣‘, ‘蛟龙‘: ‘覆海大圣‘}
{‘猴子‘: ‘悟空‘, ‘猪‘: ‘八戒‘, ‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘, ‘大鹏‘: ‘浑天大圣‘, ‘蛟龙‘: ‘覆海大圣‘
{‘猴子‘: ‘悟空‘, ‘猪‘: ‘八戒‘, ‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘, ‘大鹏‘: ‘浑天大圣‘}
{‘猴子‘: ‘悟空‘, ‘猪‘: ‘八戒‘, ‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘, ‘大鹏‘: ‘浑天大圣‘}
2.删除:
pop(key) 有返回值,返回的是被删除的value.
del dic[key]
popitem() 随机删除(在python3.6版本中,删除字典中最后一个,不随机了)
clear () 清空字典.
dic = {"猴子":"悟空","猪":"八戒","狗":"哮天犬","牛":"牛魔王"}
dic.pop("猴子")
print(dic)
del dic["猪"]
print(dic)
dic.popitem()
print(dic)
dic.clear()
print(dic)
结果:
{‘猪‘: ‘八戒‘, ‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘}
{‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘}
{‘狗‘: ‘哮天犬‘}
{}
改:
dic[key] = value 强制修改
dic.update(dic1) 把dic1中的内容更新到dic中,如果key重名,则修改替换,如果不存在,则新增.
dic = {"猴子":"悟空","猪":"八戒","狗":"哮天犬","牛":"牛魔王"}
dic["猴子"] = "齐天大圣"
print(dic)
dic = {"猴子":"悟空","猪":"八戒","狗":"哮天犬","牛":"牛魔王"}
dic1 = {"覆海大圣":"蛟魔王","混天大圣":"鹏魔王","猪":"悟能"}
dic1.update(dic)
print(dic1)
结果:
{‘猴子‘: ‘齐天大圣‘, ‘猪‘: ‘八戒‘, ‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘}
{‘覆海大圣‘: ‘蛟魔王‘, ‘混天大圣‘: ‘鹏魔王‘, ‘猪‘: ‘八戒‘, ‘猴子‘: ‘悟空‘, ‘狗‘: ‘哮天犬‘, ‘牛‘: ‘牛魔王‘}
查:
get(key) 查看,没有返回None,可以指定返回的内容
dic[key] 查看,没有这个键时查询会报错.
setdefault(key) 查看,没有返回None.
for 循环: for i in dic: #for 循环默认是获取字典中的键.
print(i)
dic = {"猴子":"悟空","猪":"八戒","狗":"哮天犬","牛":"牛魔王"}
print(dic.get("猴哥","叫哥"))
print(dic.get("猴子"))
print(dic["猪"])
print(dic.setdefault("牛"))
print(dic.setdefault("大鹏"))
结果;
叫哥
悟空
八戒
牛魔王
None
for i in dic: print(i) 结果; 猴子 猪 狗 牛 大鹏
字典的其他操作
keys 获取到所有的键存在一个高仿的列表中.
values 获取到所有的值存在一个高仿的列表中.
items 获取到所有的键值对元组的形式存在一个高仿的列表中.
dic = {"猴子":"悟空","猪":"八戒","狗":"哮天犬","牛":"牛魔王"}
print(dic.keys())
print(dic.values())
print(dic.items()) #高仿列表
for i in dic.keys():
print(i)
for i in dic: #获取到字典中的每一个键
print(i)
for i in dic.values(): #获取到字典中的每一个值
print(i)
for i in dic.items():
print(i)
结果:
dict_keys([‘猴子‘, ‘猪‘, ‘狗‘, ‘牛‘])
dict_values([‘悟空‘, ‘八戒‘, ‘哮天犬‘, ‘牛魔王‘])
dict_items([(‘猴子‘, ‘悟空‘), (‘猪‘, ‘八戒‘), (‘狗‘, ‘哮天犬‘), (‘牛‘, ‘牛魔王‘)])
猴子
猪
狗
牛
猴子
猪
狗
牛
悟空
八戒
哮天犬
牛魔王
(‘猴子‘, ‘悟空‘)
(‘猪‘, ‘八戒‘)
(‘狗‘, ‘哮天犬‘)
(‘牛‘, ‘牛魔王‘)
2.解构(解包):
a,b = 1,2
a,b = (1,2)
a,b = [1,2]
dic = {"猴子":"悟空","猪":"八戒","狗":"哮天犬","牛":"牛魔王"}
a,b = "12" #将后面解构打开按位置赋值给变量,支持--字符串,列表,元组
print(a)
print(b)
for a,b in dic.items():
print(a)
print(b)
结果:
2
猴子
悟空
猪
八戒
狗
哮天犬
牛
牛魔王
dic1 = {} dic = dic1.fromkeys([1, 2, 3], ‘abc‘) print(dic) 结果: {1: ‘abc‘, 2: ‘abc‘, 3: ‘abc‘}
字典的嵌套
#将熊大的年龄改成19岁 dic = { ‘name‘:‘汪峰‘, ‘age‘:43, ‘wife‘:{ ‘name‘:‘国际章‘, ‘age‘:39, ‘salary‘:100000 }, ‘baby‘:[ {‘name‘:‘熊大‘,‘age‘:18}, {‘name‘:‘熊二‘,‘age‘:15}, ] } dic["baby"][0]["age"] = 19 print(dic) 结果: {‘name‘: ‘汪峰‘, ‘age‘: 43, ‘wife‘: {‘name‘: ‘国际章‘, ‘age‘: 39, ‘salary‘: 100000}, ‘baby‘: [{‘name‘: ‘熊大‘, ‘age‘: 19}, {‘name‘: ‘熊二‘, ‘age‘: 15}]}
以上是关于python基础二的主要内容,如果未能解决你的问题,请参考以下文章