五三剑客之sedawk
Posted lichengbo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五三剑客之sedawk相关的知识,希望对你有一定的参考价值。
1. sed行天下
- 目标:
- 熟练通过sed命令,取行,替换操作,熟悉sed删除与增加
- 逐渐掌握sed替换中的特殊功能:反向应用(后向引用)
| 选项 | 含义 |
|---|---|
| -n | 取消默认输出,sed操作文件的时候会默认输出每一行 |
| -r | 让sed可以支持扩展正则,sed本身支持基础正则 |
| -i | 使用sed修改文件内容(危险),不进行文件输出 |
| -i.bak | 先对文件进行备份以.bak结尾,让后修改文件内容 |
| 指令 | |
|---|---|
| p | 显示/输出 |
| s | substitute替换 |
| d | 删除 |
| cai | a 在指定行后追加一行 i在指定行上面插入一行 c替换,把指定行的内容替换成........ |
1.1 sed 概述与执行流程
- sed命令,stream editor 流编辑器(认为文件,源源不断字符流)
- 格式:
- sed 选项 \'2p\' 文件
- sed 选项 \'s#oldboy#oldgirl#g\' 文件
- p和s是sed命令的指令
- g表示标记
- sed命令执行流程:找谁干啥。
- sed命令读取文件内容
- sed命令读取第一行后,进行处理(增删改查)
1.2 sed的查找功能
- 找行
- 根据内容找行
# 案例01 查很早文件的第二行
[root@lichengbo-nb /oldboy]# sed -n \'2p\' sed.txt #sed去某一行功能
102,zhangya,CTO
[root@lichengbo-nb /oldboy]# #-n 取消sed默认输出。
[root@lichengbo-nb /oldboy]# # p sed指令 print 显示/输出
# 案例02 查找文件中包含oldboy的行(类似于greo)
[root@lichengbo-nb /oldboy]# grep \'oldboy\' sed.txt
101,oldboy,CEO
[root@lichengbo-nb /oldboy]# sed -n \'/oldboy/p\' sed.txt #sed过滤功能
101,oldboy,CEO
# 案例03 过滤出文件中包含oldboy或lidao的行
[root@lichengbo-nb /oldboy]# sed -n \'/oldboy|lidao/p\' sed.txt
[root@lichengbo-nb /oldboy]# sed -rn \'/oldboy|lidao/p\' sed.txt
101,oldboy,CEO
103,lidao996,COO
110,lidao,COCO
# 案例04 过滤出文件从第二行到第五行的内容(范围)
[root@lichengbo-nb /oldboy]# sed -n \'2,5p\' sed.txt
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
sed -n \'从哪里开始,从哪里结束p\' sed.txt
# 案例05 过滤出文件中包含101的行到包含105的行(范围)
[root@lichengbo-nb /oldboy]# sed -n \'/101/,/105/p\' sed.txt
101,oldboy,CEO
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
sed -n \'/从哪里开始/,/从哪里结束/p\' sed.txt
sed命令查找小结
- 格式:sed -n \'条件p\' sed.txt
- sed查找中可用条件:
- 行号:sed -n \'2p\' sed.txt
- 行号范围:sed -n \'2,5p\' sed.txt
- 模糊过滤:类似于grep, sed -n \'/支持正则/p\' sed.txt 使用扩展正则加上-r即可
- 模糊过滤表示范围:sed -n \'/从哪里来/,/到哪里去/p\' sed.txt
1.3 sed的替换功能
- 目标:能够把文件内容进行替换于修改即可
#案例01 把文件中oldboy替换为oldgirl
[root@lichengbo-nb /oldboy]# sed \'s#oldboy#oldgirl#g\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
sed \'s#找谁#替换成什么#g\' sed.txt
#sed命令中,大部分修改的输出内容,文件内容并没有修改。(大部分时候,我们不需要修改文件内容)
[root@lichengbo-nb /oldboy]# sed -i \'s#oldboy#oldgirl#g\' sed.txt
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
#案例02 修改文件在内容前通过sed备份
[root@lichengbo-nb /oldboy]# sed \'s#lidao996#lidao007#g\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# sed -i.bak \'s#lidao996#lidao007#g\' sed.txt
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# cat sed.txt.bak
101,oldgirl,CEO
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# ll sed.txt*
-rw-r--r--. 1 root root 90 May 6 23:40 sed.txt
-rw-r--r--. 1 root root 90 May 6 23:28 sed.txt.bak
- 补充说明:sad替换时候的g是什么意思?
- s 替换
- g 全局替换global,开启全局替换,让sed把每一行中匹配的内容替换掉,默认只替换这一行中第一个匹配的内容。
#sed全局替换,演示案例。
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# sed \'s#[109]##g\' sed.txt
,oldgirl,CEO
2,zhangya,CTO
3,lidao6,COO
4,yy,CFO
5,feixue,CIO
,lidao,COCO
[root@lichengbo-nb /oldboy]# sed \'s#[109]##\' sed.txt
01,oldgirl,CEO
02,zhangya,CTO
03,lidao996,COO
04,yy,CFO
05,feixue,CIO
10,lidao,COCO
1.4 sed的替换功能之反向引用
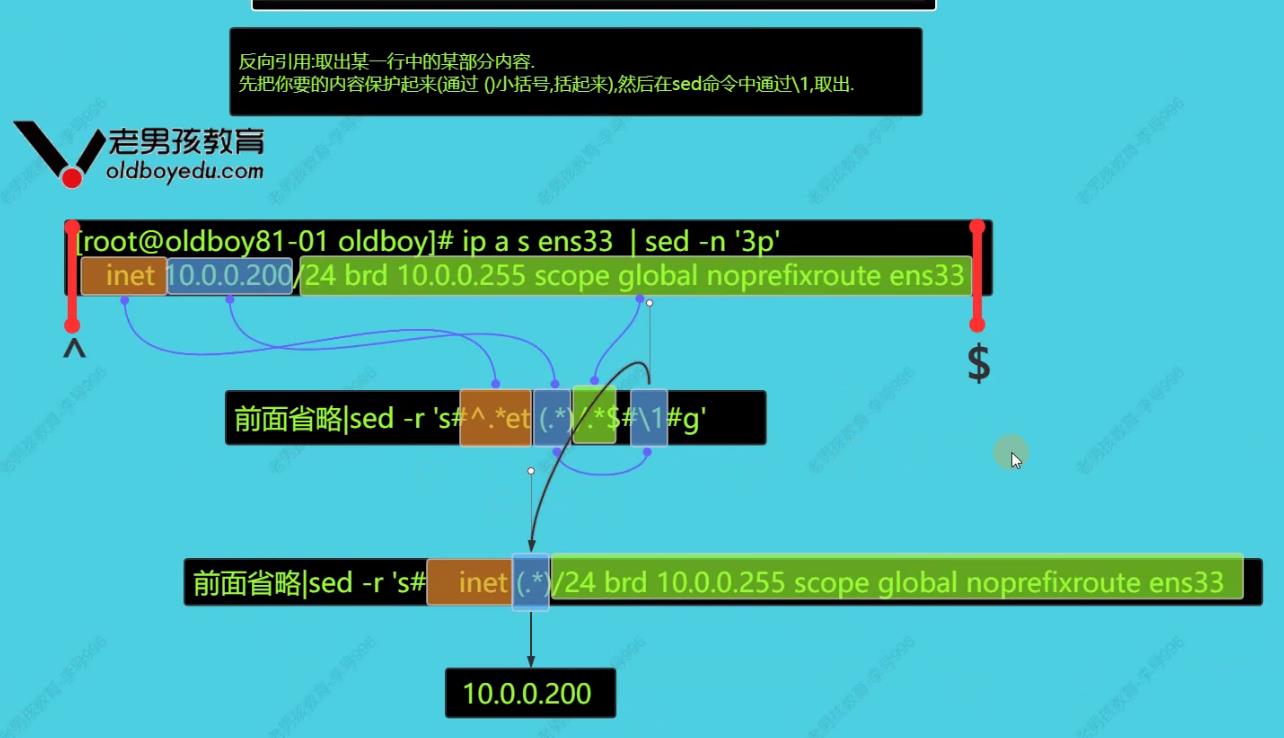
- 目标:取出ip地址,任何想要的内容
#演示案例
[root@lichengbo-nb /oldboy]# echo 123456 | sed \'s#123456#<123456>#g\'
<123456>
[root@lichengbo-nb /oldboy]# #后面连个#之间想用 前面两个#之间的内容。 后向引用
[root@lichengbo-nb /oldboy]#
[root@lichengbo-nb /oldboy]# echo 123456 | sed -r \'s#(.*)#<\\1>#g\'
<123456>
[root@lichengbo-nb /oldboy]# #反向引用使用流程:
[root@lichengbo-nb /oldboy]# #先把你要的内容通过正则,....匹配出来并加上
[root@lichengbo-nb /oldboy]# #先把你要的内容通过正则,....匹配出来并加上()保护(分组)
[root@lichengbo-nb /oldboy]# #sed 后面两#之间调用(引用) \\1\\2\\3.....
如果想匹配数字部分,更加精确,反向引用的一般需要修改 正则部分即可
#如果只给数字两边加上<>?
[root@lichengbo-nb /oldboy]# echo 1..10
1 2 3 4 5 6 7 8 9 10
[root@lichengbo-nb /oldboy]# echo 1..10 |sed -r \'s#([0-9])#<\\1>#g\'
<1> <2> <3> <4> <5> <6> <7> <8> <9> <1><0>
[root@lichengbo-nb /oldboy]# echo 1..10 |sed -r \'s#([0-9]+)#<\\1>#g\'
<1> <2> <3> <4> <5> <6> <7> <8> <9> <10>
#案例
#第一步:明确目标
#第二步:取行 第三行
#第三步:通用后向引用,先保护,然后通过\\1取这个ip地址
[root@lichengbo-nb /oldboy]# ip a s ens33 |sed -n \'3p\' | sed -r \'s# inet (.*)/24 brd 10.0.0.255 scope global noprefixroute ens33#\\1#g\'
10.0.0.200
[root@lichengbo-nb /oldboy]# ip a s ens33 |sed -n \'3p\' | sed -r \'s#^.*et (.*)/.*$#\\1#g\'
10.0.0.200
#案例02 调换/etc/passwd 第一列和最后一列。
#思路
#通过sed命令+正则 把第一列,中间部分,最后一列 匹配出来
#把这几个部分通过()括起来(分组)
#通过\\3\\2\\1 输出
[root@lichengbo-nb /oldboy]# sed -r \'s#(^.*)(:x.*:)(.*)$#\\3\\2\\1#g\' passwd
/bin/bash:x:0:0:root:/root:root
/sbin/nologin:x:1:1:bin:/bin:bin
/sbin/nologin:x:2:2:daemon:/sbin:daemon
/sbin/nologin:x:3:4:adm:/var/adm:adm
/sbin/nologin:x:4:7:lp:/var/spool/lpd:lp
/bin/sync:x:5:0:sync:/sbin:sync
/sbin/shutdown:x:6:0:shutdown:/sbin:shutdown
/sbin/halt:x:7:0:halt:/sbin:halt
/sbin/nologin:x:8:12:mail:/var/spool/mail:mail
/sbin/nologin:x:11:0:operator:/root:operator
/sbin/nologin:x:12:100:games:/usr/games:games
/sbin/nologin:x:14:50:FTP User:/var/ftp:ftp
/sbin/nologin:x:99:99:Nobody:/:nobody
/sbin/nologin:x:192:192:systemd Network Management:/:systemd-network
/sbin/nologin:x:81:81:System message bus:/:dbus
/sbin/nologin:x:999:998:User for polkitd:/:polkitd
/sbin/nologin:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:tss
/sbin/nologin:x:173:173::/etc/abrt:abrt
/sbin/nologin:x:74:74:Privilege-separated SSH:/var/empty/sshd:sshd
/sbin/nologin:x:89:89::/var/spool/postfix:postfix
/sbin/nologin:x:38:38::/etc/ntp:ntp
/bin/bash:x:998:996::/home/system:system
/bin/bash:x:1112:1112::/home/hotblood:hotblood
/sbin/nologin:x:1222:1222::/home/mariadb:mariadb
/bin/bash:x:1223:1223::/home/lichengbo:lichengbo
1.5sed的删除功能
- d :删除,以行为单位进行删除
#案例01 删除文件的第三行
[root@lichengbo-nb /oldboy]# sed \'3d\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# sed \'1,3d\' sed.txt
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
#案例02 删除oldboy或lidao的行
[root@lichengbo-nb /oldboy]# sed -r \'/oldboy|lidao/d\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
104,yy,CFO
105,feixue,CIO
#案例03 企业生成案例 去掉/etc/ssh/sshd_config文件中的空行或注释行
#方法一:
[root@lichengbo-nb /oldboy]# egrep -v \'^$|^#\' sshd_config
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_key
SyslogFacility AUTHPRIV
AuthorizedKeysFile .ssh/authorized_keys
PasswordAuthentication yes
ChallengeResponseAuthentication no
GSSAPIAuthentication yes
GSSAPICleanupCredentials no
UsePAM yes
X11Forwarding yes
AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES
AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT
AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE
AcceptEnv XMODIFIERS
Subsystem sftp /usr/libexec/openssh/sftp-server
#方法二
[root@lichengbo-nb /oldboy]# sed -r \'/^$|^#/d\' sshd_config
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_key
SyslogFacility AUTHPRIV
AuthorizedKeysFile .ssh/authorized_keys
PasswordAuthentication yes
ChallengeResponseAuthentication no
GSSAPIAuthentication yes
GSSAPICleanupCredentials no
UsePAM yes
X11Forwarding yes
AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES
AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT
AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE
AcceptEnv XMODIFIERS
Subsystem sftp /usr/libexec/openssh/sftp-server
#方法三:
[root@lichengbo-nb /oldboy]# awk \'!/^$|^#/\' sshd_config
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_key
SyslogFacility AUTHPRIV
AuthorizedKeysFile .ssh/authorized_keys
PasswordAuthentication yes
ChallengeResponseAuthentication no
GSSAPIAuthentication yes
GSSAPICleanupCredentials no
UsePAM yes
X11Forwarding yes
AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES
AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT
AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE
AcceptEnv XMODIFIERS
Subsystem sftp /usr/libexec/openssh/sftp-server
1.6 sed的增加功能
#案例01 指定行追加内容
[root@lichengbo-nb /oldboy]# sed \'5a 106,hotblood,UFO\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
106,hotblood,UFO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# sed \'5i 106,hotblood,UFO\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
106,hotblood,UFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# sed \'5c 106,hotblood,UFO\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
106,hotblood,UFO
110,lidao,COCO
#案例02 在最后一行后面追加
[root@lichengbo-nb /oldboy]# sed \'$a 106,hotblood,UFO\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
106,hotblood,UFO
#案例03 在最后一行后面追加多行
[root@lichengbo-nb /oldboy]# sed \'$a 111\\n222\\n333\\n\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
111
222
333

2.awk霸天下
- 目标:
- 近期:使用awk进行过滤,取行,取列
- 长远:使用awk进行过滤,取行,取列,统计计算。
| 选项 | 含义 |
|---|---|
| -F | 指定分隔符 |
| 指令 | |
|---|---|
| 输出、显示 | |
| NR== | 行号 |
| $NF | 最后一列 |
| $数字 | 取第几列 |
2.1 awk概述
1)awk名字
- 3个作者
- awk算是一门语言,单行脚本语言
2)awk格式
-
awk -F: \'NR==1print $1,$3\' /etc/passwd
-
awk 选项 \'条件动作\' /etc/passwd
-
条件:哪一行,过滤什么内容
-
动作:pirnt输出与显示
2.2 awk执行流程
2.3 awk取行
#案例01 取出sed.txt的第二行
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# awk \'NR==2\' sed.txt
102,zhangya,CTO
#awk \'行号 等于 2\' sed.txt
#NR awk内置变量
Number of record 记录号(行号)
#案例02 取出sed.txt中包含oldboy或lidao的行
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# awk \'/odlboy|lidao/\' sed.txt
103,lidao007,COO
110,lidao,COCO
#案例03 取出文件第2行到第5行
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# awk \'NR>=2&&NR<=5\' sed.txt
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
#案例04 去除文件第3行到最后一行内容
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# awk \'NR>=3\' sed.txt
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
#案例05 取出包含oldboy的行到lidao的行
[root@lichengbo-nb /oldboy]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@lichengbo-nb /oldboy]# awk \'/old/,/lidao/\' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao007,COO
2.4 awk取列
- 目标
- 熟练取出指定的内容或部分(取列)
#案例01 取出ls -lh命令中的第一列和第3列
[root@lichengbo-nb /oldboy]# ll -h | awk \'print $1,$3\'
total
-r-xr--r--. 1000
drwxrwxrwx. lichengbo
-rw-r--r--. root
---xr--r--. 1000
lrwxrwxrwx. 1000
-rw-r--r--. root
-rw-r--r--. root
-rw-r--r--. root
-rw-r--r--. root
-rw-------. root
-rw-r--r--. root
#注意:awk中 $数字 只有一个意思,取列
#案例02 取出/etc/passwd每一行内容,加上行号
[root@lichengbo-nb /oldboy]# awk \'print NR,$0\' /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
18 abrt:x:173:173::/etc/abrt:/sbin/nologin
19 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
20 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
21 ntp:x:38:38::/etc/ntp:/sbin/nologin
22 system:x:998:996::/home/system:/bin/bash
23 hotblood:x:1112:1112::/home/hotblood:/bin/bash
24 mariadb:x:1222:1222::/home/mariadb:/sbin/nologin
25 lichengbo:x:1223:1223::/home/lichengbo:/bin/bash
#案例03 取出/etc/passwd第1列和第3列
awk取列,默认以空格,连续空格或tab键空格分隔
如果想更改或指定新的分隔符就要加-F选项,-F指定分隔符
[root@lichengbo-nb /oldboy]# awk -F: \'print $1,$3\' /etc/passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 99
systemd-network 192
dbus 81
polkitd 999
tss 59
abrt 173
sshd 74
postfix 89
ntp 38
system 998
hotblood 1112
mariadb 1222
lichengbo 1223
#案例04 取出ip.txt文件中ip(10.0.0.200)地址
#方法一:
[root@lichengbo-nb /oldboy]# awk \'print $2\' ip.txt | awk -F\'/\' \'print $1\'
10.0.0.200
#方法二:
[root@lichengbo-nb /oldboy]# awk -F\'inet |/24\' \'print $2\' ip.txt
10.0.0.200
[root@lichengbo-nb /oldboy]# echo awk -F\'[ /]+\' \'print $3\' ip.txt
10.0.0.200
#先用-F \'[ /]+\' 先用正则匹配出连续出现的空格或/ 然后交给awd -F作为分隔符
#案例05 取出/etc/passwd第1列,第3列和最后一列
[root@lichengbo-nb /oldboy]# awk -F: \'print $1,$3,$NF\' /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
nobody 99 /sbin/nologin
systemd-network 192 /sbin/nologin
dbus 81 /sbin/nologin
polkitd 999 /sbin/nologin
tss 59 /sbin/nologin
abrt 173 /sbin/nologin
sshd 74 /sbin/nologin
postfix 89 /sbin/nologin
ntp 38 /sbin/nologin
system 998 /bin/bash
hotblood 1112 /bin/bash
mariadb 1222 /sbin/nologin
lichengbo 1223 /bin/bash
# $NF 最后一列
2.5 awk 行与列综合(awk过滤进阶)
-
awk可以完成,某一列中包含/不包含内容
#示例:取出passwd中第三列以1或2开头的内容 passwd awk -F: \'$3 ~ /^[12]/\' /etc/passwd #案例01 过滤出passwd中第3列以0-3结尾的,显示第1列和第3列内容 #方法一: 分步骤 [root@lichengbo-nb /oldboy]# awk -F: \'$3 ~ /[0-3]$/\' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin abrt:x:173:173::/etc/abrt:/sbin/nologin hotblood:x:1112:1112::/home/hotblood:/bin/bash mariadb:x:1222:1222::/home/mariadb:/sbin/nologin lichengbo:x:1223:1223::/home/lichengbo:/bin/bash [root@lichengbo-nb /oldboy]# awk -F: \'$3 ~ /[0-3]$/\' /etc/passwd | awk -F: \'print $1,$3\' root 0 bin 1 daemon 2 adm 3 operator 11 games 12 systemd-network 192 dbus 81 abrt 173 hotblood 1112 mariadb 1222 lichengbo 1223 #方法二: [root@lichengbo-nb /oldboy]# awk -F: \'$3~/[0-3]$/ print $1,$3\' /etc/passwd root 0 bin 1 daemon 2 adm 3 operator 11 games 12 systemd-network 192 dbus 81 abrt 173 hotblood 1112 mariadb 1222 lichengbo 1223 #案例02 过滤出/etc/passwd中第3列大于0小于1000的内容,显示第1列和第3列 [root@lichengbo-nb /oldboy]# awk -F: \'$3>0 && $3<1000 print $1,$3\' /etc/passwd | column -t bin 1 daemon 2 adm 3 lp 4 sync 5 shutdown 6 halt 7 mail 8 operator 11 games 12 ftp 14 nobody 99 systemd-network 192 dbus 81 polkitd 999 tss 59 abrt 173 sshd 74 postfix 89 ntp 38 system 998 #案例03 过滤出网卡配置文件中的ip地址 /etc/sysconfig/network-scripts/ifcfig-ens33 #方法一: [root@lichengbo-nb /oldboy]# awk -F= awk -F= \'NR==16 print $2\' /etc/sysconfig/network-scripts/ifcfg-ens33 10.0.0.200 #方法二: [root@lichengbo-nb /oldboy]# awk -F= \'/IPADDR/ print $2\' /etc/sysconfig/network-scripts/ifcfg-ens33 10.0.0.200
2.6 awk统计计算功能
- BEGIN和END
| 特殊条件(模式) | 含义 | 应用场景 |
|---|---|---|
| BEGIN | BEGIN内容会在awk读取文件之前执行 | 1.里面进行使用 2.进行计算,不需要读取文件内容 3.创建或修改awk变量 |
| END | END内容会在awk读取文件之后执行 | 1.awk在读取文件的时候进行统计与计算,最后统计完成END输出最终结果 |
1)BEGIN (了解)
#计算
[root@lichengbo-nb /oldboy]# awk \'BEGINprint 1/3\'
0.333333
[root@lichengbo-nb /oldboy]# awk \'BEGINprint 1/3,1-3,1+3,3*3,2^10\'
0.333333 -2 4 9 1024
#修改 awk的变量
awk \'BEGINFS=":" NR==1print $1\' passwd
2) END熟练掌握
#案例01 统计/etc/passwd的行数
[root@lichengbo-nb /oldboy]# awk \'i++ENDprint i\' /etc/passwd
25
#案例02 统计/etc/passwd中可登录用户数量
[root@lichengbo-nb /oldboy]# awk \'/bash$/ c++ ENDprint c\' /etc/passwd
4
#案例03 统计/etc/services文件中空行的数量
[root@lichengbo-nb /oldboy]# awk \'/^$/ k++ ENDprint k\' /etc/services
17
#案例04 生产工作案例 统计access.log中一共用了多了流量
[root@lichengbo-nb /oldboy]# awk \'sum=sum+$1 ENDprint sum\' liu.log
86372
#案例04 生产工作案例统计access.log中一共用了多少流量
awk \'sum-sum+$10 ENDprint sum/1024^3"GB"\' access.log
linux12shell编程 --> 三剑客之awk命令
文章目录
三剑客之sed命令
一 、awk简介
1.awk来源
awk命名源自于它的三大作者名字的首字母,分别是Alfred Aho、Brian Kernighan、Peter Weinberger。(gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展)。
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入、一个
或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix
下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。
awk的处理文本和数据的方式是这样的,它逐行扫描文件,从第一行到最后一行,寻找匹配的特定
模式的行,并在这些行上进行你想要的操作。如果没有指定处理动作,则把匹配的行显示到标准输出(
屏幕),如果没有指定模式,则所有被操作所指定的行都被处理
2、awk的两种语法格式
awk [options] 'commands' filename
awk [options] -f awk-script-file filename
3、awk选项options
-F 定义字段分隔符,默认的分隔符是空格或制表符(tab)
4、awk的命令commands总共由三部分组成
BEGIN{} {} END{}
读所有行之前做的事情 读一行处理一行 所有读完之后要做的事情
5、格式省略项
可以省略BEGIN{} 和END{},只进行{}行处理,并且{}行处理前可以加匹配,匹配成功后再处理
awk 'pattern' filename 示例:awk -F: '/root/' /etc/passwd
awk '{action}' filename 示例:awk -F: '{print $1}' /etc/passwd
awk 'pattern{action}' filename 示例:awk -F: '/root/{print $1,$3}' /etc/passwd
示例:awk 'BEGIN{FS=":"} /root/{print $1,$3}' /etc/passwd
其他命令 |awk 'pattern'
其他命令 |awk '{action}'
其他命令 |awk 'pattern{action}'
# 匹配pattern可以是:/正则表达式/也可以是条件,如下
示例:df -P |awk '$4 > 999999{print $0}' # 也可以省略{print $0}
模式pattern还可以是其他,详解第五章节
二 、awk工作原理
awk -F: '{print $1,$3}' /etc/passwd
(1)awk会接收一行作为输入,并将这一行赋给awk的内部变量$0,每一行也可称为一个记录,行的边界是以换行符作为结束
(2)然后,刚刚读入的行被以:为分隔符分解成若干字段(或域),每个字段存储在已编号的变量中,编号从$1开始,最多达100个字段
注意:如果未指定行分隔符,awk将使用内置变量FS的值作为默认的行分隔符,FS默认值为空格
(3)使用print函数打印,如果$1$3之间没有逗号,它俩在输出时将贴在一起,应该在$1,$3之间加逗号,该逗号与awk的内置变量OFS保持一致,OFS默认为空格,于是以空格为分隔符输出$1和$3
我们可以指定:awk -F: 'BEGIN{OFS="-"}{print $1,$3}' /etc/passwd
(4)输出之后,将从文件中获取另一行,然后覆盖给$0,继续(2)的步骤将该行内容分隔成字段。。。继续(3)的步骤
该过程一直持续到所有行处理完毕
# NF:段数
# NR:行号
# FS:输入分隔符
# OFS:输出分隔符
三、 记录与字段相关内部变量
$0: 保存当前行的内容 # awk -F: '{print $0}' /etc/passwd
NR: 记录号,每处理完一条记录,NR值加1 # awk -F: '{print NR, $0}' /etc/passwd
NF: 保存记录的字段数,$1,$2...$100 # awk -F: '{print $0,NF}' /etc/passwd
FS: 输入字段分隔符,默认空格 # awk -F: '/alice/{print $1, $3}' /etc/passwd
# awk -F'[ :\\t]' '{print $1,$2,$3}' /etc/passwd
# awk 'BEGIN{FS=":"} {print $1,$3}' /etc/passwd
OFS:输出字段分隔符 # awk -F: '/root/{print $1,$2,$3,$4}' /etc/passwd
# awk -F: 'BEGIN{OFS="+++"} /^root/{print $1,$2,$3,$4}' /etc/passwd
# awk 'BEGIN{OFS="-";FS=":"}/root/{print NR,$0,NF}' /etc/passwd
四 、格式化输出
================print函数===================
[root@egon ~]# date | awk '{print "月:",$2,"\\n年:",$1}'
月: 09月
年: 2020年
[root@egon ~]#
[root@egon ~]# awk -F: '{print "用户名:",$1,"用户id:",$3}' /etc/passwd
================printf函数===================
[root@egon ~]# awk -F: '{printf "用户名:%s 用户id:%s\\n",$1,$3}' /etc/passwd
[root@egon ~]# awk -F: '{printf "|%-15s| %-10s| %-15s|\\n", $1,$2,$3}' /etc/passwd
%s 字符类型
%d 数值类型
占15格的字符串
- 表示左对齐,默认是右对齐
printf默认不会在行尾自动换行,加\\n
五、 模式pattern与动作action
awk 'pattern{action}' filename
pattern可以是如下6个模式:
1、正则表达式
# 匹配整行
awk -F: '/egon/{print $1,$3}' /etc/passwd
awk '/^root/' /etc/passwd
# 匹配一行的某个字段
# awk '$0 ~ /^root/' /etc/passwd
[root@openvpn awk]# cat passwd.txt |awk -F: '$1 ~/root/{print NR,$0}'
1 root:x:0:0:root:/root:/bin/bash
# awk '$1 !~ /bash$/' /etc/passwd # 取反
2、比较表达式
比较表达式指的是使用关系运算符来比较数字以及字符串,只有当条件为真,才执行指定的动作
关系运算符
运算符 含义 示例
< 小于 x<y
<= 小于或等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y
~ 正则表达式匹配 x~/y/
!~ 正则表达式不匹配 x!~/y/
示例:
# awk -F: '$3 == 0' /etc/passwd
# awk -F: '$3 < 10' /etc/passwd
# awk -F: '$7 == "/bin/bash"' /etc/passwd
# awk -F: '$1 == "root" ' /etc/passwd
3、条件表达式
# awk -F: '{if($3>300) {print $0}}' /etc/passwd
# awk -F: '{if($3>300) {print $3} else{print $1}}' /etc/passwd
# awk -F: '{if($3>300) {max=$3;print max} else{max=$1;print max}}' /etc/passwd
# awk -F: '{max=($3>300) ? $3 : $1; print max}' /etc/passwd
# awk -F: '{if($3>$4) {max=$3;print max} else{max=$4; print max}}' /etc/passwd
# awk -F: '{max=($3 > $4) ? $3: $4; print max}' /etc/passwd
相当于:
if ($3 > $4)
max=$3
else
max=$4
4、算数运算
+ - * / %(模) ^(幂2^3)
可以在模式中执行计算,awk都将按浮点数方式执行算术运算
# awk -F: '$3 * 10 > 500' /etc/passwd
# 例题
# 月薪*12 大于100000工资
[root@openvpn awk]# cat 1.awk
mm:16000:25
ping:12000:21
tom:8000:31
[root@openvpn awk]# awk -F: '$2*12 >100000{print $1}' 1.awk
mm
ping
# 取奇数行
[root@openvpn awk]# cat passwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@openvpn awk]# awk -F: 'NR % 2 != 0{print NR,$1}' passwd.txt
1 root
3 daemon
5 lp
7 shutdown
9 mail
# 指定输出
[root@openvpn awk]# cat 1.awk
mm:16000:25
ping:12000:21
tom:8000:31
[root@openvpn awk]# awk -F: '{print NR,$1}' 1.awk
1 mm
2 ping
3 tom
[root@openvpn awk]# awk -F: 'BEGIN{OFS="-----"}{print NR,$1}' 1.awk
1-----mm
2-----ping
3-----tom
# 指定输出内容格式
[root@openvpn awk]# cat 1.awk
mm:16000:25
ping:12000:21
tom:8000:31
[root@openvpn awk]# awk -F: 'BEGIN{OFS="---"}{printf "行号:%s---用户名:%s\\n",NR,$1}' 1.awk
行号:1---用户名:mm
行号:2---用户名:ping
行号:3---用户名:tom
[root@openvpn awk]# awk -F: 'BEGIN{OFS="---"}{print "行号:"NR,"用户名:"$1}' 1.awk
行号:1---用户名:mm
行号:2---用户名:ping
行号:3---用户名:tom
5、逻辑运算和复合模式
&& 逻辑与 a&&b
|| 逻辑或 a||b
! 逻辑非 !a
示例:
# awk '$2 > 5 && $2 <= 15' filename
# awk '$3 == 100 || $4 > 50' filename
# awk '!($2 < 100 && $3 < 20)' filename
6、范围模式
# 正则
awk '/root/,/egon/' filename
说明:
awk将显示从root首次出现的行到egon首次出现的行这个范围内的所有行,包括两个边界在内。如果没有找到egon,awk将继续打印各行直至文件末尾。
如果打印完root到egon的内容之后,又出现了root, awk就又一次开始显示行,直至找到下一个egon或文件末尾。
[root@openvpn ~]# cat a.txt
1111root
2222root22222
egon123123123123
4444
5555
6666
root7777
1asf
asdfasdf
egon
7788
[root@openvpn ~]# awk '/root/,/egon/{print NR,$0}' a.txt
1 1111root
2 2222root22222
3 egon123123123123
7 root7777
8 1asf
9 asdfasdf
10 egon
[root@openvpn ~]#
# 行号
awk -F: 'NR>=1 && NR <=3{print $1}' test.txt
六 、awk示例
# awk '/west/' datafile
# awk '/^north/' datafile
# awk '/^(no|so)/' datafile
# awk '{print $3,$2}' datafile
# awk '{print $3 $2}' datafile
# awk '{print $0}' datafile
# awk '{print "Number of fields: "NF}' datafile
# awk '/northeast/{print $3,$2}' datafile
# awk '/E/' datafile
# awk '/^[ns]/{print $1}' datafile
# awk '$5 ~ /\\.[7-9]+/' datafile
# awk '$2 !~ /E/{print $1,$2}' datafile
# awk '$3 ~ /^Joel/{print $3 " is a nice guy."}' datafile
# awk '$8 ~ /[0-9][0-9]$/{print $8}' datafile
# awk '$4 ~ /Chin$/{print "The price is $" $8 "."}' datafile
# awk '/Tj/{print $0}' datafile
# awk '{print $1}' datafile2
# awk -F: '{print $1}' datafile2
# awk '{print "Number of fields: "NF}' datafile2
# awk -F: '{print "Number of fields: "NF}' datafile2
# awk -F"[ :]" '{print $1,$2}' datafile2
# awk '$7 == 5' datafile
# awk '$2 == "CT" {print $1, $2}' datafile
# awk '$7 != 5' datafile
# awk '$7 < 5 {print $4, $7}' datafile
# awk '$6 > .9 {print $1,$6}' datafile
# awk '$8 <= 17 {print $8}' datafile
# awk '$8 >= 17 {print $8}' datafile
# awk '$8 > 10 && $8 < 17' datafile
# awk '$2 == "NW" || $1 ~ /south/ {print $1, $2}' datafile
# awk '!($8 == 13){print $8}' datafile
# awk '/southem/{print $5 + 10}' datafile
# awk '/southem/{print $8 + 10}' datafile
# awk '/southem/{print $5 + 10.56}' datafile
# awk '/southem/{print $8 - 10}' datafile
# awk '/southem/{print $8 / 2 }' datafile
# awk '/southem/{print $8 / 3 }' datafile
# awk '/southem/{print $8 * 2 }' datafile
# awk '/southem/{print $8 % 2 }' datafile
# awk '$3 ~ /^Suan/ {print "Percentage: "$6 + .2 " Volume: " $8}' datafile
# awk '/^western/,/^eastern/' datafile
# awk '{print ($7 > 4 ? "high "$7 : "low "$7)}' datafile //条件运算符
# awk '$3 == "Chris" {$3 = "Christian"; print}' datafile //赋值运算符
# awk '/Derek/ {$8 += 12; print $8}' datafile //$8 += 12等价于$8 = $8 + 12
# awk '{$7 %= 3; print $7}' datafile //$7 %= 3等价于$7 = $7 % 3
七 、awk流程控制
==条件判断
if语句:
格式
{if(表达式){语句;语句;...}}
awk -F: '{if($3==0) print $1 " is administrator."}' /etc/passwd
awk -F: '{if($3>0 && $3<500){count++; print $1}} END{print count}' /etc/passwd //统计系统用户数
if...else语句:
格式
{if(表达式){语句;语句;...}else{语句;语句;...}}
awk -F: '{if($3==0){print $1} else {print $7}}' /etc/passwd
awk -F: '{if($3>0) {count++} else{i++}' /etc/passwd
awk -F: '{if($3>0){count++} else{i++}} END{print "管理员个数: "i "\\n系统用户数: "count}' /etc/passwd
if...else if...else语句:
格式
{if(表达式){语句;语句;...}else if(表达式){语句;语句;...}else if(表达式){语句;语句;...}else{语句;语句;...}}
awk -F: '{if($3==0){i++} else if($3>499){k++} else{j++}} END{print i; print k; print j}' /etc/passwd
awk -F: '{if($3==0){i++} else if($3>499){k++} else{j++}} END{print "管理员个数: "i; print "普通用个数: "k; print "系统用户: "j}' /etc/passwd
==循环
while:
awk -F: '{i=1; while(i<=10) {print $0; i++}}' /etc/passwd //将每行打印10次
for:
awk -F: '{for(i=1;i<=10;i++) print $0}' /etc/passwd //将每行打印10次
==数组(索引或key对应值)
# awk -F: '{username[++i]=$1} END{print username[1]}' /etc/passwd
root
# awk -F: '{username[i++]=$1} END{print username[1]}' /etc/passwd
bin
# awk -F: '{username[i++]=$1} END{print username[0]}' /etc/passwd
root
# awk -F: '{username[x++]=$1} END{for(i=0;i<NR;i++) print i,username[i]}' /etc/passwd
0 root
1 bin
2 daemon
3 adm
4 lp
5 sync
6 shutdown
7 halt
...
# awk -F: 'BEGIN{x=1} {user[x++]=$1} END{for(i=1;i<=NR;i++) {print i,user[i]} }' /etc/passwd
# awk -F: 'BEGIN{j=1} {if($3<5){user[j++]=$1}} END{for(i=1;i<j;i++) {print i,user[i]} }' /etc/passwd
# awk -F: 'BEGIN{i=1} {username[i]=$1;i++}'
# awk -F: 'BEGIN{i=1} $3<10{username[i]=$1;++i} END{for(j=1;j<i;j++){print j,username[j]}}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
9 mail
10 admin
========================================================
# awk -F: '{username[++x]=$1} END{for(i=1;i<=NR;i++) {print i,username[i]}}' passwd1
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
9 mail
10 uucp
# awk -F: '{username[++x]=$1} END{for(i in username) {print username[i]} }' passwd1
adm
lp
sync
shutdown
halt
mail
uucp
root
bin
daemon
》》》》》》》》》》》》key:value《《《《《《《《《《《《
# awk -F: '{user_id[$1]=$3} END{for(i in user_id) {print i,user_id[i]}}' passwd1
bin 1
uucp 10
mail 8
sync 5
shutdown 6
adm 3
daemon 2
halt 7
root 0
lp 4
========================================================
统计用户名为4个字符的用户:
[root@openvpn ~]# awk -F: '$1~/^....$/{count++; print $1} END{print "count is: " count}' /etc/passwd
root
sync
halt
mail
news
uucp
nscd
vcsa
pcap
sshd
dbus
jack
count is: 12
[root@openvpn ~]# awk -F: 'length($1)==4{count++; print $1} END{print "count is: "count}' /etc/passwd
root
sync
halt
mail
news
uucp
nscd
vcsa
pcap
sshd
dbus
jack
count is: 12
# 例题
# 判断系统是否是那个用户
[root@openvpn awk]# cat id.sh
#! /bin/bash
x=0
y=0
z=0
for uid in `awk -F: '{print $3}' /etc/passwd`
do
if [ $uid -eq 0 ];then
let x++
elif [ $uid -ge 1 ] && [ $uid -le 999 ];then
let y++
else
let z++
fi
done
printf "管理员数:%s 系统用户:%s 普通用户:%s\\n" $x $y $z
[root@openvpn awk]# ./id.sh
管理员数:1 系统用户:26 普通用户:1
作业
1. 取得网卡IP(除ipv6以外的所有IP)
2. 获得内存使用情况
3. 获得磁盘使用情况
4. 清空本机的ARP缓存
5. 打印出/etc/hosts文件的最后一个字段(按空格分隔)
6. 打印指定目录下的目录名
[root@openvpn dir1]# arp -a |awk -F"[()]" '{print "arp -d", $2}'
arp -d 192.168.15.26
arp -d 192.168.15.44
arp -d 192.168.15.28
arp -d 192.168.15.130
arp -d 192.168.15.90
arp -d 192.168.15.18
arp -d 192.168.15.129
[root@openvpn dir1]# arp -a |awk -F"[()]" '{print "arp -d " $2}' |sh
[root@openvpn ~]# awk -F: '{print $7}' /etc/passwd
[root@openvpn ~]# awk -F: '{print $NF}' /etc/passwd
[root@openvpn ~]# awk -F: '{print $(NF-1)}' /etc/passwd
[root@openvpn ~]# ll |grep '^d'
drwxr-xr-x 104 root root 12288 09-22 05:37 192.168.15.61
drwxr-xr-x 2 root root 4096 10-30 15:47 apache_log
drwxr-xr-x 2 root root 4096 10-30 15:23 awk
drwxr-xr-x 2 root root 4096 10-24 09:09 Desktop
drwxr-xr-x 12 root root 4096 10-08 06:12 LEMP_Soft
drwxr-xr-x 2 root root 4096 10-24 07:38 scripts
drwxr-xr-x 6 root root 4096 2012-03-29 uplayer
drwxr-xr-x 7 root root 4096 10-23 04:53 vmware
[root@openvpn ~]#
[root@openvpn ~]# ll |grep '^d' |awk '{print $NF}'
192.168.15.61
apache_log
awk
Desktop
LEMP_Soft
scripts
uplayer
vmware
awk脚本:
user1.awk
BEGIN {
FS=":"
}
{
if($3==0){
print $1
}
else{
print $7
}
}
user2.awk
BEGIN{
FS=":"
OFS="\\t\\t"
print "username\\tuid"
print "-------------------"
}
{if($3==0){
print $1,$3;i++
}
}
END{
print "-------------------"
print "total users is: "i
}
八 、练习题
已知一个变量 msg="I am a teacher, my name is egon",打印字符长度小于3的单词
# 方式一:
[root@egon /]# for i in $msg;do [ ${#i} -lt 3 ] && echo $i;done
I
am
a
my
is
# 方式二:
[root@egon /]# echo $msg |xargs -n1 |awk '{if(length<3) print}'
I
am
a
my
is
# 方式三:
[root@egon /]# echo $msg |awk '{for(i=1;i<=NF;i++) if(length($i)<3) print $i}'
I
am
a
my
is
# 方式四:
[root@egon /]# echo $msg |egrep -wo '[a-z]{1,3}'
am
a
my
is
以上是关于五三剑客之sedawk的主要内容,如果未能解决你的问题,请参考以下文章