python3+selenium入门13-操作cookie
Posted 梦忆安凉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3+selenium入门13-操作cookie相关的知识,希望对你有一定的参考价值。
可以把cookie理解为自己账户的身份证。因为http协议是无状态的,上一个请求和下一个请求没有关系。但是有时需要有关联。比如登录之后,才能进行操作这样的设置。这个就是cookie在起作用。登录成功时,服务器会给浏览器一个cookie,浏览器会解析存在本地。然后同一个网站,下一次请求时就会把这个cookie带上,告诉服务器是哪个用户在操作。在关闭浏览器时cookie有效期结束。
WebDriver提供了一些用来操作cookie的方法:
get_cookies():获得cookie所有信息,返回的是一个字典
get_cookie(key):获取返回cookie中,某一个key的值
add_cookie(cookie_dict):手动添加cookie,需要传一个字典进去,用cookie_dict来接收,字典的键必须要有‘name’和‘value’
delete_cookie(name):删除cookie信息,name是要删除的cookie名称
delete_all_cookies():删除所有cookie信息
一般就add_cookie比较常用。可以用这个来绕过登录。下面来看用cookie登录百度的实例
因为很多网站现在通过selenium去模拟登录的话,都会有安全提示,要求验证是否本人登录啥的。所以先通过手动登录一下来拿到cookie。然后再来实验绕过登录。
打开百度首页,点击登录按钮跳转到登录页面,把用户名密码输完了之后。F12呼出开发者工具,然后点击登录。
![]() ?
?
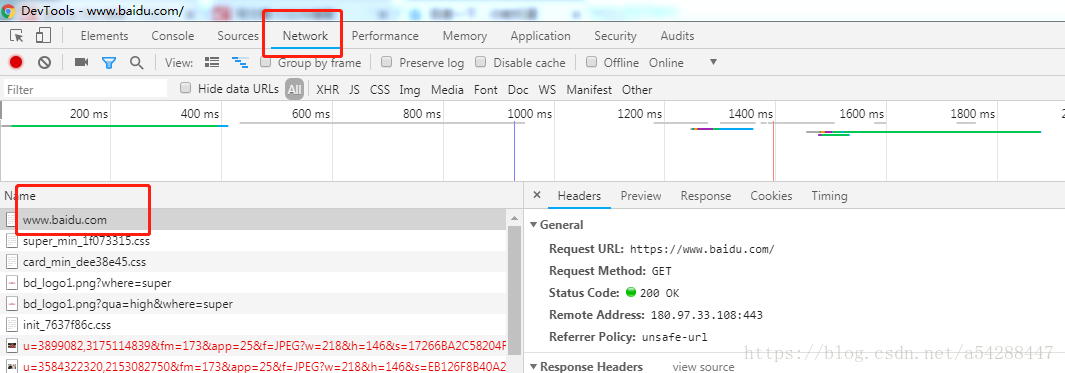
登录成功后,找到www.baidu.com这个请求。看下右侧然后往下拉
![]() ?
?
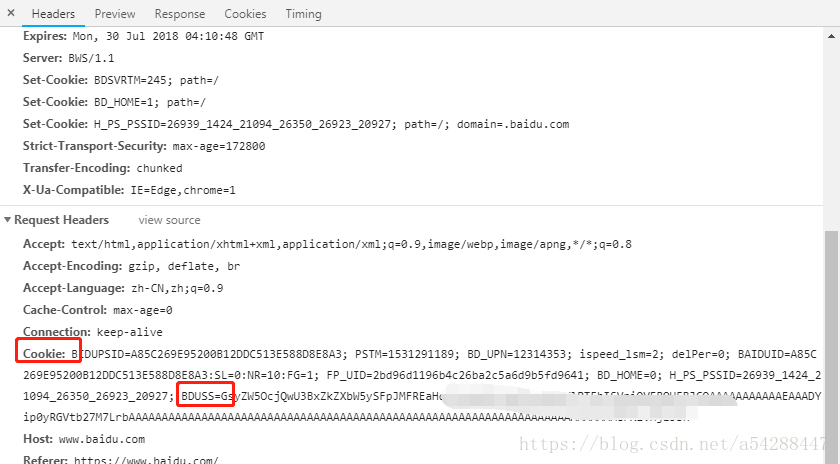
找到Cookie。我们需要的是最后BDUSS键值对的信息。
add_cookie也可以这样写
以上是关于python3+selenium入门13-操作cookie的主要内容,如果未能解决你的问题,请参考以下文章