一文详解如何在 ChengYing 中通过产品线部署一键提升效率
Posted 数栈DTinsight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文详解如何在 ChengYing 中通过产品线部署一键提升效率相关的知识,希望对你有一定的参考价值。
在之前的内容当中,我们为大家介绍过 ChengYing 的安装原理、产品包制作等内容,本篇就延续之前的内容,和大家展开聊聊 ChengYing 产品线部署相关的设计。帮助对「一站式全自动化全生命周期大数据平台运维管家 ChengYing」感兴趣的开发者更好地了解和使用 ChengYing。
产品线部署简介
首先对 ChengYing 的产品线部署进行一个“自我介绍”,共分为三个部分:
● 支持用户自定义的产品线
在 ChengYing 中,是以组件包的维度部署服务,比如一个 zookeeper 的产品包,会预先定义好 ZK 的包上传到 ChengYing 的系统当中,再去选择要部署的服务以及给 ZK 编排部署机器,以此完成部署。
对于初学者来说,当需要部署多个服务,这些服务又有顺序依赖关系时,会不清楚部署的先后顺序,从而导致部署非常吃力。因此 ChengYing 支持使用 DAG(有向无环图)进行定义灵活可配的组件包部署顺序。目的是为了让熟悉和不熟悉的人都能够通过预定义产品线的形式同时部署多个组件包,从而大大提高部署效率。
● 支持服务的亲和性配置
根据组件包中不同服务的类型,结合主机角色信息自动进行服务主机编排。在接入主机到 ChengYing 系统中时,支持给主机打上对应的标签即角色,相应角色的组件会部署到相应角色的机器上。
● 一键自动部署组件包
基于组件包手动部署,同样的入口,选择不同的产品线部署方式之后,可一键按需迅速完成所需要的多个组件包的同时部署,提高部署效率。
产品线部署设计
接下来,通过代码设计的角度看看 ChengYing 对产品线部署是如何进行技术设计的。
什么是 DAG
DAG (有向无环图,Directed Acyclic Graph)是一种常用数据结构,仅就 DAG 而言,它已经在我们日常的各种工具中存在,如依赖系统、数据流系统、数据可视化等。当我们从任务编排的角度来看,DAG 面向普通人术语叫作工作流(Workflow)。
在图论中, 如果一个有向图无法从任意顶点出发经过若干条边回到该点, 则这个图就是一个有向无环图 (DAG 图)。
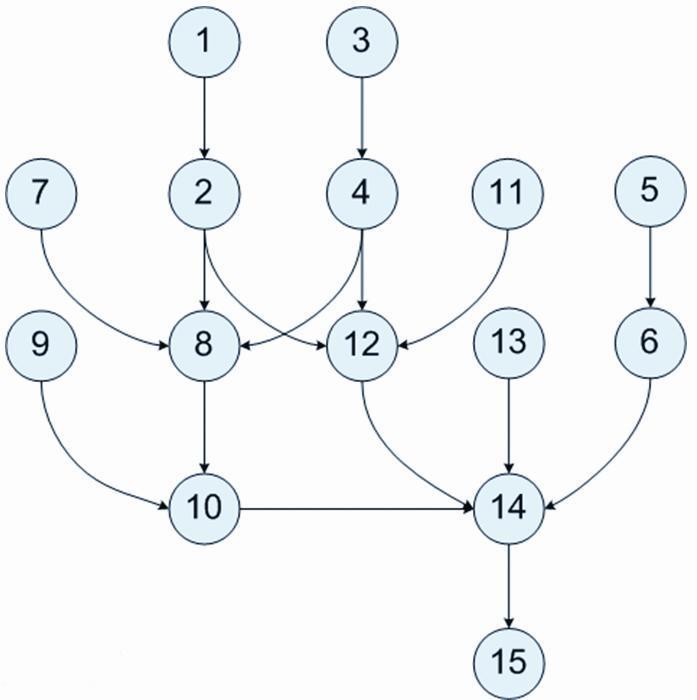
ChengYing 产品线部署设计的核心就是给定一组任务,按照自定义的方式安排它们的执行顺序,即 DAG。
产品线 DAG 定义
预先定义某一条产品线中每一个组件包的部署顺序,将其关系使用 DAG 的方式定义为 json 文件,平台自动解析 json 得到部署顺序从而实现自动部署的效果。

· product_line_name: 产品线名称(可预定义)
· product_line_version: 产品线版本(可预定义)
· product_serial: 组件包部署顺序(上图说明 DTBase 的 dependee 为0,表示没有依赖;DTFront 的 dependee 为1,表示依赖 id 为1的组件包)
产品线 DAG 源码分析
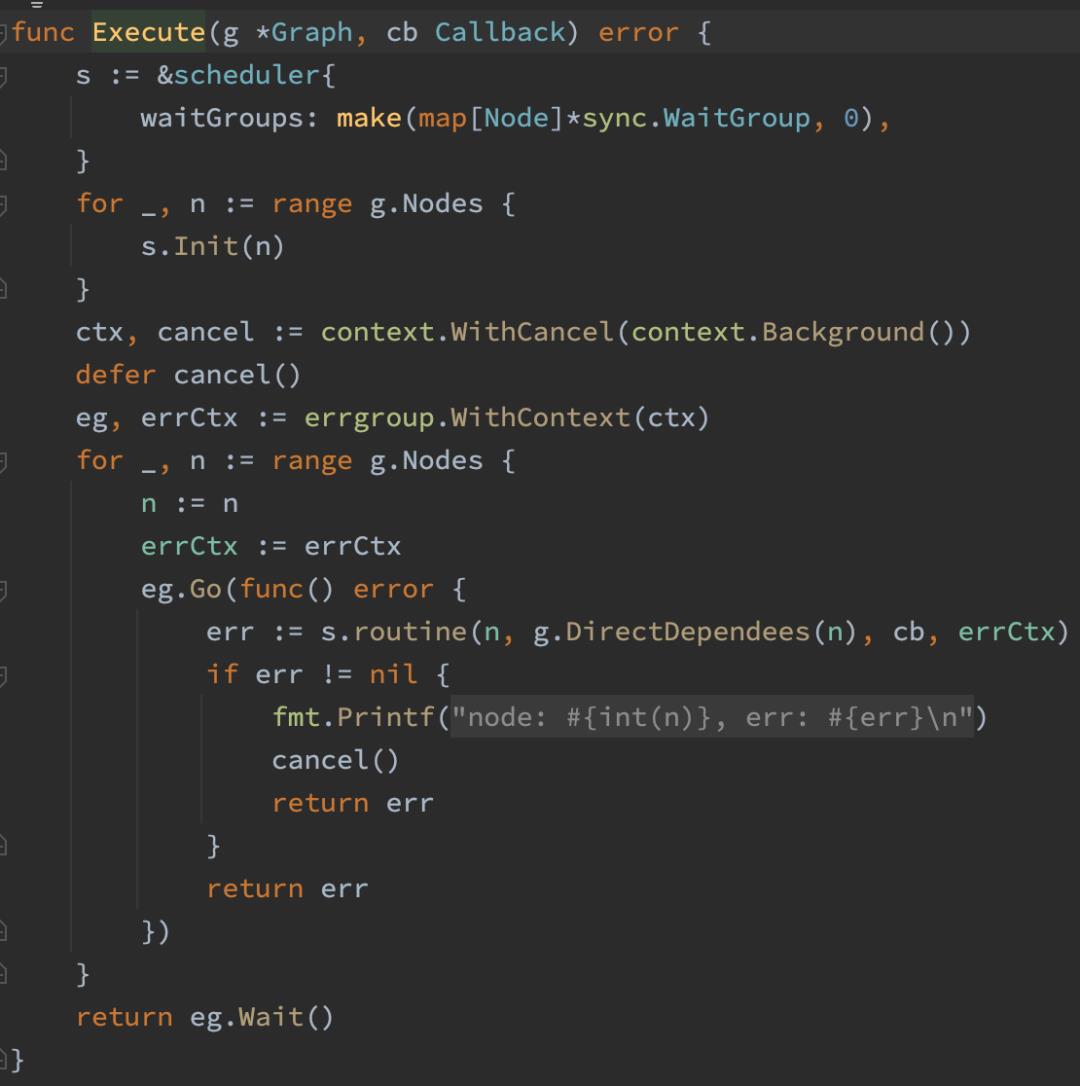
如果要对复杂对象排序的话,该排序必须包含 Len,Swap,Less 这三个方法。

下面这段源码是 DAG 执行的核心逻辑,对于源码的具体解析可以前往视频进行观看:
https://www.bilibili.com/video/BV1KV4y1Q7KP/?spm_id_from=333.999.0.0
源码本身已经全部开源,可以前往 ChengYing 的 Github 进行学习:
https://github.com/DTStack/chengying
服务亲和性配置
服务亲和性的定义指以预选、优选、选定的机制完成将每个新的服务绑定至为其选出的目标节点上。
在 k8s 中,支持节点和 Pod 两个层级的亲和性、反亲和性调度,通过配置亲和与反亲和的规则,允许指定硬性限制和软性限制,即偏好。
比如将前端的 Pod 和后端的 Pod 部署在一起,这样可以减少网络延迟。或是某一类型的服务部署在某一类型的节点上,不同的应用部署在不同的节点上等。
定义节点亲和性规则时有两种类型的节点亲和性规则 :硬亲和性 required 和软亲和性 preferred。硬亲和性实现的是强制性规则,它是 Pod 调度时必须要满足的规则,而在不存在满足规则的节点时 , Pod 对象会被置为 Pending 状态。
而软亲和性规则实现的是一种柔性调度限制,它倾向于将 Pod 对象运行于某类特定的节点之上,而调度器也将尽量满足此需求,但在无法满足调度需求时它将退而求其次地选择一个不匹配规则的节点。
类似于 k8s,ChengYing 中的服务亲和性和反亲和性也进行了相应的字段设置:
· orchestration.affinity:数组,自动编排角色亲和性【可选】, 但是没有该字段的话,该服务将无法参与自动编排
· orchestration.anti_affinity:数组,自动编排角色反亲和性 【可选】
使用场景
下面来为大家介绍如何在 ChengYing 中使用产品线的部署。
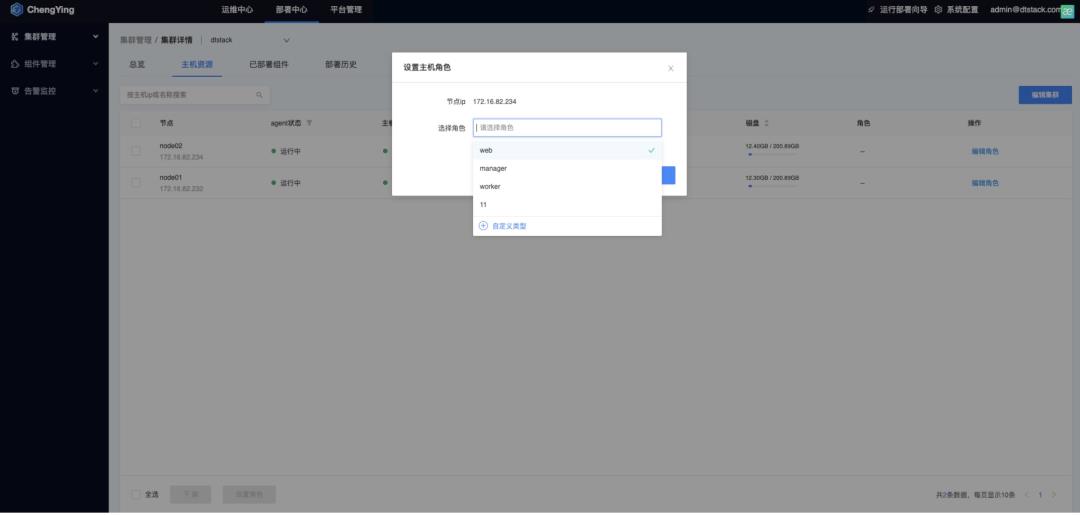
设置主机角色
在【部署中心】-【集群管理】-【集群详情】中,可以给节点编辑对应角色。
上传产品线
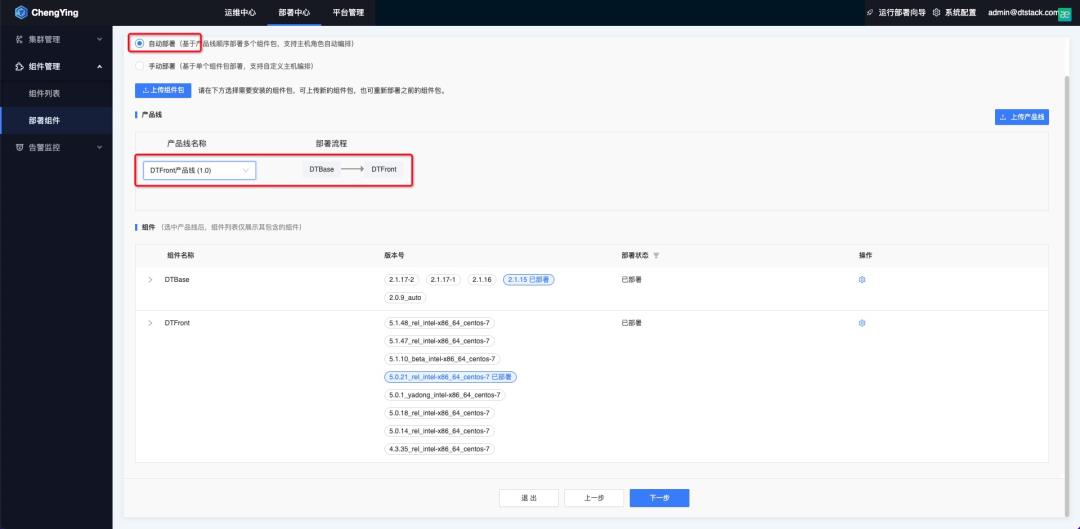
角色完成定义之后,就可以在【部署中心】进行部署。支持自动部署(基于产品线顺序部署多个组件包,支持主机角色自动编排),手动部署(基于单个组件包部署,支持自定义主机编排)。
只要把产品线和产品包的亲和性与反亲和性全部定义好之后,开发者进入这个页面会非常一目了然,每一个节点上分配了哪些服务,先后进行怎样的部署等,一键就可以完成这些繁琐的工作,极大提升部署效率。
视频课程&PPT获取
视频课程:
https://www.bilibili.com/video/BV1KV4y1Q7KP/?spm_id_from=333.999.0.0
课件获取:
https://www.dtstack.com/resources/1037
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
开源项目丨一文详解一站式大数据平台运维管家 ChengYing 如何部署 Hadoop 集群
课件获取:关注公众号 “数栈研习社”,后台私信 “ChengYing” 获得直播课件
视频回放:点击这里
ChengYing 开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下海洋同学的直播分享《ChengYing 部署 Hadoop 集群实战》
一、Hadoop 集群部署准备
在部署集群前,我们需要做一些部署准备,首先我们需要按照下载 Hadoop 产品包:
● Mysql
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Mysql_5.7.38_centos7_x86_64.tar
● Zookeeper
● Hadoop
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hadoop_2.8.5_centos7_x86_64.tar
● Hive
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Hive_2.3.8_centos7_x86_64.tar
● Spark
https://dtstack-opensource.oss-cn-hangzhou.aliyuncs.com/chengying/Spark_2.1.3-6_centos7_x86_64.tar
接着我们可以将下载好的产品包直接通过 ChengYing 界面上传,具体路径是:部署中心 — 组件管理 — 组件列表 — 上传组件安装包:

可以通过两种模式上传产品包:
本地上传方式
产品包在先下载到本机电脑存储中,点击本地上传,选在产品包上传。

网络上传模式
直接填写产品包网络地址上传(ChengYing 的网络需要和产品包网络互通)。


Hadoop 集群部署流程
做完准备后,我们可以开始进入集群部署,Hadoop 集群部署流程包括以下步骤:

集群部署顺序说明
- 首先需要部署 Mysql 和 zookeeper,因为 Hadoop 需要依赖 zookeeper,Hive 元数据存储使用的是 Mysql;
- 其次需要部署 Hadoop,Hive
- 最后部署 Spark,因 Spark 依赖 hivemetastore
PS:部署顺序是不可逆的
Hadoop 集群部署角色分布


产品包标准部署流程

- 选择需要部署的产品包,点击部署按钮,然后选择对应需要部署的集群,默认集群为 dtstack,集群名称可配置;
- 下一步选择需要部署的服务,默认产品包下的服务都会部署,可以根据实际需求部署,在此阶段可以对服务的配置文件进行修改,例如:修改 Mysql 连接超时时间等;
- 最后点击部署,等待部署完成。
Mysql 服务部署流程演示
接下来我们以 Mysql 服务部署流程来为大家实际演示下整体流程:
● 第一步:选择集群


● 第二步:选择产品包

● 第三步:选择部署节点

● 第四步:部署进度查看


● 第五步:部署后状态查看


Hadoop 集群使用与运维
集群部署完毕后,若有需求可以进行配置变更操作。
● 配置修改
例如:如果需要操作修改 yarn 的配置文件,可以先选择 yarn-site.xml 文件,可以在搜索框搜索需要修改的配置文件 key,如 cpu_vcores。

● 配置保存

● 配置下发

Taier 对接 Hadoop 操作流程
ChengYing 除了可自动部署运维外,还可以对接 Taier 部署 Hadoop 集群,Taier 是一个大数据分布式可视化的 DAG 任务调度系统,旨在降低 ETL 开发成本、提高大数据平台稳定性,大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
利用 ChengYing 部署管理 Taier 服务,可以做到实时监控 Taier 的服务状态,随时界面修改 Taier 配置等。Taier 对接 Hadoop 集群的操作流程如下:

- 首先需要在 Taier 控制台选择多集群配置,新增一个集群;
- 然后配置 sftp、资源调度组件、存储组件和计算组件;
- 配置完成后需要保存并且测试连通性。
注意事项:
在对接过程中,sftp 主机需要和 Taier 网络相通,并且 sftp 配置主机的路径需要存在,如果不存在,需要手动创建。
Taier 的部署网络需要与 Hadoop 网络相通,如果运行任务,需要在 Taier 所在节点加入 Hadoop 集群的 Host 配置;编译 /etc/hosts 文件,增加 IP Hostname。
● 第一步:配置公共组件
首先进入 Taier 登陆界面,点击控制台,新增集群,然后进入多集群管理界面,配置公共组件,选择 SFTP,进入 SFTP 配置界面。

● 第二步:配置 SFTP
然后配置 SFTP 的 host,认证方式,默认采用用户名密码方式,输入用户名和密码,并且输入 path 路径,此路径需要在主机上存在,如果不存在,需要手动创建一个 SFTP 路径.

● 第三步:资源调度组件配置
需要到部署 Hadoop 服务器到 /opt/dtstack/Hive/hive_pkg/conf 目录下获取 hive-site.xml 文件,下载到本地;
到 /opt/dtstack/Hadoop/Hadoop_pkg/etc/Hadoop 目录下获取 hdfs-site.xml、core-site.xml、yarn-site.xml 文件,下载到本地;
这四个文件压缩成一个 zip 包,上传这个压缩包。

● 第四步:计算组件配置
选择计算组件模块,选择需要对接的计算引擎 Hive 和 Spark,选择 Hive 和 Spark 的版本,填写对应的 jdbc(jdbc:hive://ip:port/)连接串,然后点击保存,测试连通性。
注意:jdbcurl 中 ip 分别为 Hive 组件的 hiveserver2 和 Spark 中的 thrifterserver 所在节点 ip。

● 第五步:配置 Hive 和 Spark
以下是配置完成 Hive 和 Spark 组件后,测试连通性的状态。
注意:本地演示环境 Hadoop 未开启安全,Hive 和 Spark 只需要配置 jdbcurl 即可。

Hadoop 集群近期规划
最后和大家聊聊 Hadoop 集群近期规划,近期主要有三大规划:
● 产品包制作
制作 ChengYing 部署产品包的流程及实践。
● ChunJun&Taier 产品包
制作可以用 ChengYing 部署的 Taier 和 chunjun 的产品包
● Hadoop 运维
通过 ChengYing 运维大数据集群;
通过 ChengYing 一键开启 Hadoop 集群安全。
袋鼠云开源框架钉钉技术交流qun30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
以上是关于一文详解如何在 ChengYing 中通过产品线部署一键提升效率的主要内容,如果未能解决你的问题,请参考以下文章