阀权值是个啥概念?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阀权值是个啥概念?相关的知识,希望对你有一定的参考价值。
高好? 还是低的好?
各种阀门的优缺点,分别适用于哪些场合选择阀门主要依据是阀门的流量特性曲线,和阀权值等参数.球阀属于快开阀,一般用于有快开快关的场合,管径也比较小.闸阀阻力小,关闭后密闭性好,内漏少,常用于干管的关断;截止阀阻力大,阀权值高,所以用来调节末端的流量比较合适;碟阀体积小,可以调节阀瓣的形状来设计成不同流量特性的阀门,有关断,调节,管径也能做得很大,选择时有样本参照最好!
阀门的选择的主要依据是管路系统的要求要与阀门的流量特性曲线相适应,一般来讲截止阀主要用于流量的调节,但其自身的阻力较大,且盘根容易漏水;闸阀的阻力较小且关断性较好,但不利于流量的调节;球阀适用于快速关断系统,一般管径较小;蝶阀的体积小,结合截止阀、球阀的优点,既可调节,又有比较好的关断性,管径也比较大,适用范围比较广,分热水、冷水两种。
按按用途和作用分类
〈〉截断阀类 主要用于截断或接通介质流。包括闸阀、截止阀、隔膜阀、球阀、旋塞阀、
碟阀、柱塞阀、球塞阀、针型仪表阀等。
〈〉调节阀类 主要用于调节介质的流量、压力等。包括调节阀、节流阀、减压阀等。
〈〉止回阀类 用于阻止介质倒流。包括各种结构的止回阀。
〈〉分流阀类 用于分离、分配或混合介质。包括各种结构的分配阀和疏水阀等。
〈〉安全阀类 用于介质超压时的安全保护。包括各种类型的安全阀。
按主要参数分类
(一) 按压力分类
〈〉真空阀 工作压力低于标准大气压的阀门。
〈〉低压阀 公称压力PN 小于1.6MPa的阀门。
〈〉中压阀 公称压力PN 2.5~6.4MPa的阀门。
〈〉高压阀 公称压力PN10.0~80.0MPa的阀门。
〈〉超高压阀 公称压力PN大于100MPa的阀门。
(二) 按介质温度分类
〈〉高温阀 t 大于450C的阀门。
〈〉中温阀 120 C小于 t 小于450 C的阀门。
〈〉常温阀 -40 C小于 t 小于120 C的阀门。
〈〉低温阀 -100 C小于 t 小于-40 C的阀门。
〈〉超低温阀 t 小于-100 C的阀门。
(三) 按阀体材料分类
〈〉非金属材料阀门:如陶瓷阀门、玻璃钢阀门、塑料阀门。
〈〉金属材料阀门:如铜合金阀门、铝合金阀门、铅合金阀门、钛合金阀门、蒙乃尔合金阀门
铸铁阀门、碳钢阀门、铸钢阀门、低合金钢阀门、高合金钢阀门。
〈〉金属阀体衬里阀门:如衬铅阀门、衬塑料阀门、衬搪瓷阀门。
通用分类法
〈〉这种分类方法既按原理、作用又按结构划分,是目前国际、国内最常用的分类方法。一般分
闸阀、截止阀、节流阀、仪表阀、柱塞阀、隔膜阀、旋塞阀、球阀、蝶阀、止回阀、减压阀
安全阀、疏水阀、调节阀、底阀、过滤器、排污阀等。 参考技术A BP神经网络算法 简介:BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)
摘 要:BP神经网络算法是在BP神经网络现有算法的基础上提出的,是通过任意选定一组权值,将给定的目标输出直接作为线性方程的代数和来建立线性方程组,解得待求权,不存在传统方法的局部极小及收敛速度慢的问题,且更易理解。
关键词:固定权值;gauss消元法;BP算法
人工神经网络(artificial neural networks,ANN)系统是20世纪40年代后出现的,它是由众多的神经元可调的连接权值连接而成,具有大规模并行处理、分布式信息存储、良好的自组织自学习能力等特点,在信息处理、模式识别、智能控制及系统建模等领域得到越来越广泛的应用。尤其误差反向传播算法(Error Back-propagation Training,简称BP网络)可以逼近任意连续函数,具有很强的非线性映射能力,而且网络的中间层数、各层的处理单元数及网络的学习系数等参数可根据具体情况设定,灵活性很大,所以它在许多应用领域中起到重要作用。近年来,为了解决BP神经网络收敛速度慢、不能保证收敛到全局最小点,网络的中间层及它的单元数选取无理论指导及网络学习和记忆的不稳定性等缺陷,提出了许多改进算法。
1 传统的BP算法简述
BP算法是一种有监督式的学习算法,其主要思想是:输入学习样本,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能地接近,当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。具体步骤如下:
(1)初始化,随机给定各连接权〔w〕,〔v〕及阀值θi,rt。
(2)由给定的输入输出模式对计算隐层、输出层各单元输出
bj=f(■wijai-θj) ct=f(■vjtbj-rt)
式中:bj为隐层第j个神经元实际输出;ct为输出层第t个神经元的实际输出;wij为输入层至隐层的连接权;vjt为隐层至输出层的连接权。
dtk=(ytk-ct)ct(1-ct) ejk=〔■dtvjt〕 bj(1-bj)
式中:dtk为输出层的校正误差;ejk为隐层的校正误差。
(3)计算新的连接权及阀值,计算公式如下:
vjt(n+1)=vjt(n)+?琢dtkbj wij(n+1)=wij(n)+?茁ejkaik
rt(n+1)=rt(n)+?琢dtk θj(n+1)=θj(n)+?茁ejk
式中:?琢,?茁为学习系数(0<?琢<1,0<?茁<1)。
(4)选取下一个输入模式对返回第2步反复训练直到网络设输出误差达到要求结束训练。
传统的BP算法,实质上是把一组样本输入/输出问题转化为一个非线性优化问题,并通过负梯度下降算法,利用迭代运算求解权值问题的一种学习方法,但其收敛速度慢且容易陷入局部极小,为此提出了一种新的算法,即高斯消元法。
2 改进的BP网络算法
2.1 改进算法概述
此前有人提出:任意选定一组自由权,通过对传递函数建立线性方程组,解得待求权。本文在此基础上将给定的目标输出直接作为线性方程等式代数和来建立线性方程组,不再通过对传递函数求逆来计算神经元的净输出,简化了运算步骤。没有采用误差反馈原理,因此用此法训练出来的神经网络结果与传统算法是等效的。其基本思想是:由所给的输入、输出模式对通过作用于神经网络来建立线性方程组,运用高斯消元法解线性方程组来求得未知权值,而未采用传统BP网络的非线性函数误差反馈寻优的思想。
2.2 改进算法的具体步骤
对给定的样本模式对,随机选定一组自由权,作为输出层和隐含层之间固定权值,通过传递函数计算隐层的实际输出,再将输出层与隐层间的权值作为待求量,直接将目标输出作为等式的右边建立方程组来求解。
现定义如下符号(见图1):x (p)输入层的输入矢量;y (p)输入层输入为x (p)时输出层的实际输出矢量;t (p)目标输出矢量;n,m,r分别为输入层、隐层和输出层神经元个数;W为隐层与输入层间的权矩阵;V为输出层与隐层间的权矩阵。具体步骤如下:
(1)随机给定隐层和输入层间神经元的初始权值wij。
(2)由给定的样本输入xi(p)计算出隐层的实际输出aj(p)。为方便起见将图1网络中的阀值写入连接权中去,令:隐层阀值θj=wnj,x(n)=-1,则:
aj(p)=f(■wijxi(p)) (j=1,2…m-1)。
(3)计算输出层与隐层间的权值vjr。以输出层的第r个神经元为对象,由给定的输出目标值tr(p)作为等式的多项式值建立方程,用线性方程组表示为:
a0(1)v1r+a1(1)v2r+…+am(1)vmr=tr(1)a0(2)v1r+a1(2)v2r+…+am(2)vmr=tr(2) ……a0(p)v1r+a1(p)v2r+…+am(p)vmr=tr(p) 简写为: Av=T
为了使该方程组有唯一解,方程矩阵A为非奇异矩阵,其秩等于其增广矩阵的秩,即:r(A)=r(A┊B),且方程的个数等于未知数的个数,故取m=p,此时方程组的唯一解为: Vr=〔v0r,v2r,…vmr〕(r=0,1,2…m-1)
(4)重复第三步就可以求出输出层m个神经元的权值,以求的输出层的权矩阵加上随机固定的隐层与输入层的权值就等于神经网络最后训练的权矩阵。
3 计算机运算实例
现以神经网络最简单的XOR问题用VC编程运算进行比较(取神经网络结构为2-4-1型),传统算法和改进BP算法的误差(取动量因子α=0.001 5,步长η=1.653)
吊炸天的云原生,到底是个啥
云原生技术里有很多技术、概念和术语,不了解的人,往往弄不清楚而一头雾水,这些概念都是啥,之间是什么关系?
本文要说的就是这些。
本文更多是科普和扫盲,无意面面俱到,也无意深入细节。 本文适合一定IT基础的人阅读,完全的小白和门外汉,可能是看不懂的。
 完全看不懂的云原生
完全看不懂的云原生
云计算?云原生?
云原生就是“云+原生”(cloud + native)。一般而言,“云”更关注IaaS,也就是基础设施层面(如计算、存储、网络);“原生”更关注PaaS层面(如容器、微服务)。之所以叫“原生”,是因为它一生下来是给云用的,可谓是生在云里,长在云里。
一位学者可能会说:“云计算是一种灵活提供基础IT资源的架构,云原生是一种在云计算上创建和运行应用程序的方法。”这话没有什么错,但也没有什么用,因为太抽象了。
在词汇使用上,据我观察,“云计算”和“云原生”基本上已经混为一谈了,我从来没有见过一个人说“云原生”的时候,另一个人站出来说“不对,这个是云计算”,反之亦然。
唯一的区别是:人们以前爱说“云计算”,现在爱说“云原生”。
毕竟,新词总是高大上一点嘛。
所以,这块不要太纠结。
云原生带来什么好处
其实这等同一个问题:为什么要上云。
好处有很多,我本人觉得最重要的有3点:
7个字:隔离、弹性、自动化。
1、隔离:在传统架构中,一个网络配置错误可能导致整个DC故障,一个模块出问题可能会导致整个应用系统故障。而且往往很难定位和隔离。云原生通过VPC、容器、微服务这些能力,把网络、操作系统、应用系统以虚拟或拆分的方式隔离开来,做到互不影响。一个部分的运行、变更或故障,不会影响其他部分,这就安全多了。
2、弹性:应用系统在服务能力紧张时,需要扩容,比如增加机器的内存和CPU,或是部署新的实例并做负载均衡,在传统环境下,这需要一定的工作量,尤其是需要运维人员的安装和配置。云原生在一开始设计时,就考虑了如何更方便、更快捷、更安全地扩容,比如虚机、容器的快速生成,自动地扩容和负载均衡。这样,以前是几个小时的事,现在稍稍动动手指就可以了,几分钟或者更少的时间搞定。
3、自动化:不管是部署还是变更、维护,如果一项工作涉及多个步骤,需要多项配置,甚至需要多个团队配合,那就会很繁琐,很复杂,对使用者的要求就会很高,出错的概率就会变大。如果只需一条指令、一个按键就能完成相关工作,那就是高度的自动化。云原生的很多设计,就是以尽可能少的指令,完成尽可能复杂的操作。
自动化通过什么方式呈现给用户?一是图形化界面,让各类用户(平台租户、运营人员、运维人员、开发人员)都可以简单上手操作,比如租户(就是客户)点点鼠标就能申请一台虚机或是一台网关;二是命令行界面,让喜欢命令行的人可以直接或者写脚本调用;三是API,让程序员可以写程序任意编排操作。这样,各种不同技能基础的人,都能够尽自己能力实现尽可能的自动化。
云原生的本质,就是IT全过程的软件化,也即“软件定义everything”在IT行业得以实现,而且是规模化和自动化的实现。原先冗长、复杂、颇费时费力的技术工作和体力活,现在可以轻轻松松搞定。
说这么多,现在略略见识一下:
kubectl create deployment nginx --image=nginx --replicas=2
kubectl set image deployment/nginx nginx=nginx:latest以上是两条kubernetes命令,其中,第一条命令部署两个nginx容器,第二条命令则让它们更新成一个最新的镜像版本。
看,这多么简单。
云原生的基础知识
考虑扫盲性质,现在说一点最基础的东西。
1、虚机:虚机是在物理服务器之上虚拟出来的具有完整功能的计算机。人们可以通过云平台创建虚机并安装操作系统,对其扩容,并在不停机的情况下将其迁移到另一台物理机上。
2、裸金属:裸金属即云纳管的物理机。裸金属不参与虚拟化,不提供虚机,但一样可以被云管理,可以被云自动化地分配、回收和管理。
3、存储:云可以提供块存储(如IPSAN)、文件存储(如NAS)、对象存储(OBS)。并且都提供界面、命令行和API给用户,让用户可以非常便利的使用和管理存储。通过对存储的资源池化和虚拟化,抹平了不同设备的差异,用户不再需要学习具体的存储设备知识、指令和配置方法。
比如在openstack中,用如下命令创建一个叫my_volume的卷,大小为10G,然后通过命令将这个创建好的卷连接到虚拟服务器my_server上。
openstack volume create --size 10 my_volume
openstack server add volume myserver my_volume看,这多么简单!作为一个完全不懂存储的人,我也可以轻而易举做到。
可以说,云的用户,就是在抽象层或者说逻辑层工作,底层细节完全可以不了解。
4、网络:云提供虚拟的网络,用户并不用实际购买和独占网络设备,就可以在云里构建出一个个互相隔离的虚拟网络分区,组织他的多台虚机。这通过创建虚拟私有网络(VPC)、虚拟子网、虚拟路由器、虚拟NAT网关等来实现。用户不再需要和底层的网络设备打交道,用户只需要在云平台里“创建”和“配置”即可。
5、容器:容器可视为轻量级的虚拟机,它把应用“集装箱”化,应用程序和自己需要的依赖(Depends)打包在一起,自成一体。容器可以在各种操作系统中部署,不受具体宿主机影响。比起虚机,它更轻量,更方便、可以秒级启动。
以上这些是最基本的概念,相对靠基础设施一些,再往上走,就会遇到更“云原生”一些的概念:微服务、服务网格、函数计算、DevOps等,这些更靠近开发一些。
下面,我们继续,部分概念会再次说起。
云原生中最重要的概念
搞明白下面这些概念及其关系,你就心里有底了。
1、虚机
虚机(VM,Virtual Machine,或称虚拟机 )是在一台物理机(又称宿主机)上虚拟出来的计算机,目的是提高计算机硬件资源的利用率。这通过物理机上安装VMM(Virtual Machine Manager,虚拟机管理器)来实现。VMM给虚机分配调度相应的资源(内存、CPU、网络、磁盘等),加载虚机的操作系统,并调度给虚机最终所需的物理资源。大体而言,一台物理机可以虚拟出10台虚拟机。
 虚机、VMM、物理机关系示意图
虚机、VMM、物理机关系示意图
和容器相比,虚机还是有些笨重的,由于虚机镜像包含了整个操作系统,所以通常有几个GB大小。虚机启动时间通常是1分钟或几分钟。
虚机镜像是包含一台计算机的操作系统、安装的软件、数据和配置等信息的文件。镜像文件通常被用来作为虚拟机的模板,以便在需要时快速地创建多台相同内容的虚拟机。
正是因为虚机还不够敏捷便利,速度也不够快,所以才产生了容器技术。
2、容器
在一个操作系统中,通过进程隔离、内存隔离、文件隔离、用户隔离、网络隔离等技术,形成一个个互相隔离的运行空间,每个空间里运行着应用程序和其所依赖的程序及库,这就是容器。
这样,多个容器共享同一个操作系统,但又互相隔离。容器通常不大,可以秒级启动,非常迅捷。
容器实现了完全的可移植性,在支持容器的任何操作系统或环境上都可以兼容运行。因为容器里的软件和所需要的库依赖是封装好的,和所在宿主机的库是互相隔离的,不需要像以前那样,要在宿主机上做各种安装和适配。
在Linux操作系统中,早有通过命名空间(namespace)和控制组(control group)实现应用程序隔离的方法,使得一个或多个进程的CPU,内存,磁盘I / O和网络使用可以隔离开来互不影响,此即Linux容器(LXC)技术。但对用户而言,LXC并不易用。Docker把这些较为复杂的容器功能封装起来,形成对用户友好的操作命令或图形界面,才使得容器流行起来。
3、容器编排
在大型系统中,需要大量的容器同时运行,直接管理一个个容器有点麻烦,如果能以更优雅更自动化的方法就更好了,这就出现了容器编排工具,有好几种容器编排工具,但是毫无疑问,Kubernetes(简称k8s)这些年最流行的容器编排工具。
所谓
编排(orchestration),就是统揽全局式的规划、组织、部署、管理等,把众多复杂的元素管理地井然有序,达到管理者所指定和预期的目标。
k8s提供了许多强大的功能,例如部署容器、自动扩容、负载均衡、应用更新、故障恢复和容器监控等。总之,它能让用户更轻松、更便利地部署、调度和监控容器。用户可以通过描述性的文件,描述k8s应部署容器的规格、个数和关系,指定服务端口,将多个容器组织成一个应用,并能根据容器的负载情况自动地扩展容器的数量。
比如下面两句话,就能将nginx容器扩容到5个。
kubectl scale deployment web-server --replicas=5
kubectl rollout restart deployment/web-server4、VPC
VPC(Virtual Private Cloud,虚拟私有云)是在云中构建出来的一个独立的、隔离的虚拟网络环境,一朵云中,可以有多个VPC。
虽然名字里带个“云”字,但人们更喜欢称之为“虚拟私有网”,因为它更多的特性是网,然后才是其上的虚机、容器等。
用户可以在VPC中自主规划 IP 地址,创建子网,并使用虚拟交换机vSwitch、虚拟路由器vRouter、虚拟负载均衡vLB等网络组件,还能通过网络ACL、安全组、虚拟防火墙vFW等方式,实现网络内虚机的隔离保护。
比起虚机和容器,虚拟网络会更让人难以理解一些,如果想快速扫盲,见我下一篇文章《让人懵懂的云网络,里面原来是这些》。
5、微服务(Microservices)
微服务是一种架构,在这种架构中,把原先应用系统中的各个功能模块独立出来,形成一个个服务,跑在不同的虚机或容器中,然后用标准化的方法互相调用。这些服务原先是耦合在一台机器里的,现在都独立出来了,人们也就能独立地开发、部署和管理它们了。
微服务架构的目标是让每个服务都尽可能简单、单一,每个服务只执行特定的业务逻辑,并且具备良好的横向扩展能力。各服务之间通过简单、轻量的通信协议(如REST、gRPC等)进行通信。
微服务的好处是,一、便于隔离,一个服务坏了也不会影响其他服务,不像以前都在一个机器里,一坏就感染一片;二、便于扩容,一个服务如果形成性能瓶颈,就对那个服务扩容,多弄几个容器运行它。不像以前那样,要对整个应用系统扩容。三、便于维护,每个服务都可以独立地开发、部署、运维,一个服务只由一个小团队专门负责。在另一个层面上讲,小团队的管理,也显然要比大团队容易。
在微服务架构中,常遇到两个概念:API网关和服务网格。
API网关提供集中式的服务请求处理,集成了反向代理、负载均衡、SSL卸载、身份认证、限流熔断、超时重试、流量监控、日志统计等功能,适合处理来自外部的流量(南北向)。在客户端和后台服务之间可以存在一个或多个功能不同的API网关。最受欢迎的网关代理是Nginx、HAProxy和Envoy。
对于系统内部复杂的服务间调用(东西向),为了避免瓶颈,还是以分布式的方法通信比较好,这就是近年来比较火的服务网格。
6、服务网格(Service Mesh)
由于服务总是要处理请求,遇到网络不好的时候,就需要重连或做超时处理,这样,每个服务都需要实现请求重试、超时处理、断路器等机制。如果每个服务都写这样的机制,就有点不经济。如果服务还是用不同语言实现的,这些部分也得用不同语言实现,就很不经济了。
服务网格的想法是将这种通用的功能从每个服务中抽出来,最早的做法是给服务提供SDK(便于服务集成通用功能)
,后来逐渐演变为由独立的代理来完成通用功能:在每个服务旁边运行一个代理(sidecar),sidecar作为一个单独的容器与应用容器放在k8s的同一个Pod中(Pod是k8s调度的最小单元,里面可以有1个或多个容器)
运行,它们共享相同的网络。sidecar处理流入或流出的请求和响应流量,实现路由、安全和监控等功能。
比如:Istio服务网格在服务的每个应用容器旁运行Envoy代理作为sidecar,所有sidecar都受微服务控制平面管理。
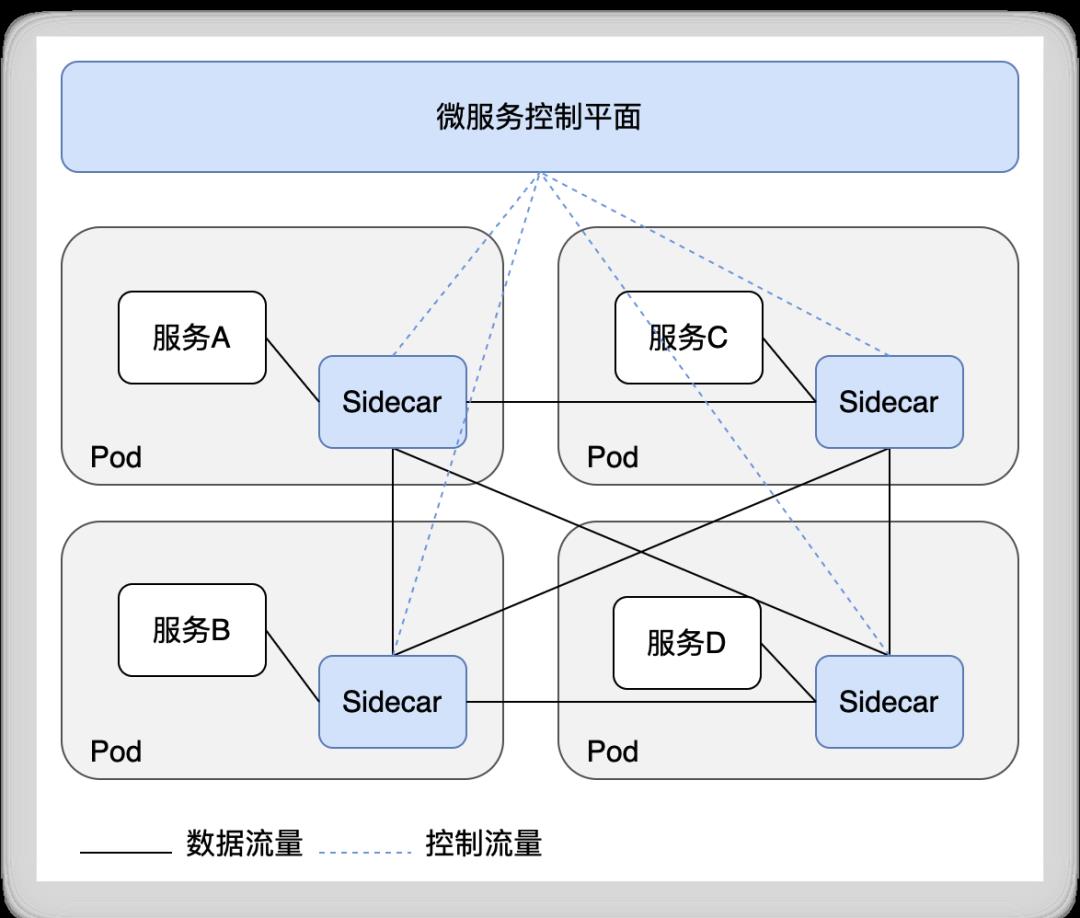 由Sidecar组成的服务网格
由Sidecar组成的服务网格
注:Sidecar是一种形象的比喻,原意是摩托车旁的边车。
 真正的sidecar
真正的sidecar
这种分离让开发人员能够很集中精力在业务上,而真正不再考虑非业务功能,所有服务所共需的通用能力,都放在sidecar里来做。
就好像开车的就专心开车,通信和作战交给边车上的队友。
7、无服务器(serverless)
“无服务器”并非真的没有服务器,而是说用户(比如开发人员)完全不用关心服务器的事,不用申请服务器、存储和网络。用户只关心自己的程序,所有和资源相关的琐事都由云提供商处理。代码执行时,云提供商会启动资源,代码执行结束时,释放资源。用户只为使用时间付费,而不为闲置容量付费。
这提法更像是一个理念,更像是一个产品营销话术,而不像一项新技术,因为“无服务器”的背后无非还是虚机、容器、微服务这些,只是用户可以不管这些,这些都由云服务商提供,用户把精力放在自己的程序上就好。
函数即服务(Function as a Service,FaaS)是最常被提起的无服务器架构,虽然它只是serverless的一种。使用FaaS,用户将函数放到云上(将代码作为zip文件或容器镜像上传),在需要的时候,通过HTTP调用即可,用户只需为函数的执行时间付费,函数所在容器,以及所需的RunTime,都由云服务商调度和管理。常见的FaaS产品AWS Lambada、Azure Functions和谷歌的Cloud Functions。
显然,这种一会运行一会关闭的函数,只适合那种一过性的运算,那种很简单的、无状态的运算,比如简单计算、更新记录、发送消息、写入数据这种。
除了FaaS,还有别的serverless,比如serverless DB,它不需要用户手动维护和配置服务器资源,而是自动扩展和伸缩。
总之,只要是用户原先要考虑服务器而现在不用考虑服务器的服务,都是Serverless。
8、基础设施即代码(IaC)
程序员大多是不太爱碰硬件的,他们喜欢沉溺在软件的思维里。当他们不得不接触和管理硬件的时候(比如被轮岗或是种种原因),他们就决心用软件的方式来管理这些硬件。
基础设施即代码(Infrastructure as Code,IaC)用编程语言描述他们要运维和管理的基础设施(服务器、网络设备、存储设备等硬件),这样,部署和管理笨重的硬件设备,无非也就是在电脑面前敲几句代码而已,不再需要像以前那样吭哧吭哧地猛干了。
这是硬件维护人员多年以来梦寐以求的自动化。现在,人们只是写一个脚本,用脚本去部署服务器,并配置各种网络、存储、负载均衡器等任何基础设施服务。然后,只是执行这个脚本,就可以在完全不同的AZ(AZ即可用区,后面会介绍)中部署一套高度一致的基础设施。以前,这样的任务需要数人、数周才能完成。现在,几个小时就可以完成。
基础设施即代码,换句话说,即,软件定义基础设施。
9、DevOps
DevOps(它是“Development”和“Operations”的缩写),就是从开发到运维,整个过程自动化。自动化地编译、测试、构建容器、上传容器、部署、发布、监控、告警等,如果发现了Bug或问题,团队能够迅速迭代这一过程,修改代码,然后又是自动化的编译、测试、部署、发布等,一天可以来上这么10次!
在2009年O’Reilly Velocity大会上两个Flickr员工做了题为《10+ Deploys Per Day: Dev and Ops Cooperation at Flickr》的演讲1,引起了轰动,随后得以蓬勃发展。
当然,这需要多种工具和多个脚本的有机衔接。
以前,这一过程冗长,开发团队和运维团队的配合并不容易。因为他们有着不同的部门和领导,有着不同的文化,他们的目标和利益并不一致。从开发到上线,这个过程中,有着各种流程和审批,1天能有10次发布?开玩笑,10天能有1次就不错了。现在可好,全都自动化了,一个小团队,从开发到发布,全都干了,还很快,运维人员几乎都不用动手,或者几乎都不需要出现。
本质上,DevOps是搞开发的人终于帮助搞运维的人,把运维那摊子事给自动化了(搞运维的人,通常不太擅长写代码)
。我想,这肯定是哪个公司,非要逼得开发人员去搞运维,所以他们没办法,只能自己拿起看家本事造福自己了。开发那一段的自动化,早在近二十年前,他们搞敏捷开发的时候就搞差不多了,他们早早就搞了CI(持续集成)
,然后又搞了CD(持续部署)
,这十年,他们通过前面说的容器、微服务、k8s等技术,再加上一些新方法、新工具,把运维这一段也搞定了,他们终于打通了任督二脉。
崇拜DevOps的人会说远远不止这些,是的,他们往DevOps里装了种种思想、理念和方法论,以至于人们似乎已经忘了它本来想致力于什么。我以前写过一篇文章讲如何从高层把握DevOps2的实质,有兴趣可以看看。
下面这张图有助于你从全貌上概览一下,这只是一种框架,引自3,篇幅有限,此处不细解释。
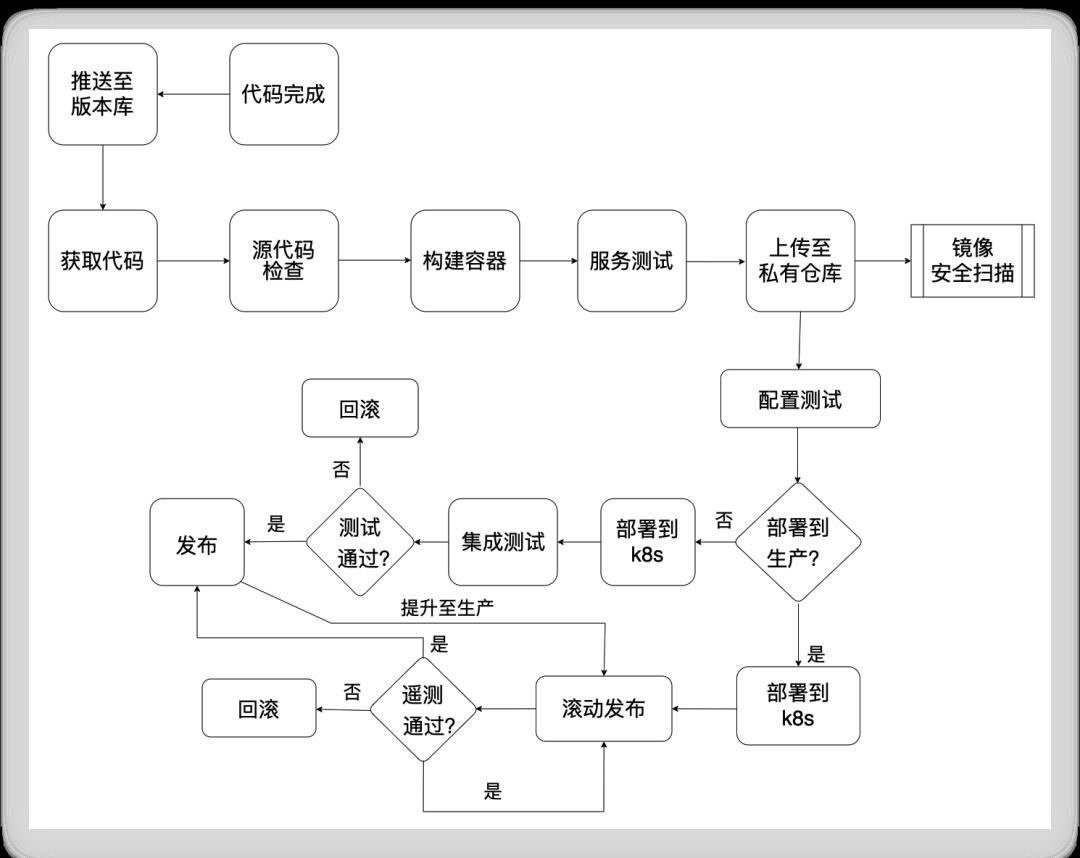 一种DevOps工作模型
一种DevOps工作模型
滚动发布是一种发布软件更新的方法。软件新版本先在小范围内发布,没有什么问题的话,再慢慢扩展到更大的范围。这样,一开始如果有问题,受影响的也只是少数用户。类似概念和叫法有灰度发布、金丝雀发布。以前矿工下矿前,为防范探洞里有有毒气体,会先放一只金丝雀进去,看金丝雀能否活下来,金丝雀发布得名于此。
更深一步:云计算背后的东西
下面的内容有点偏底层技术了。
如果你不想了解更多,跳过这章就好。
1、云平台和云管平台
当“云管平台”(Cloud Management Platform)这个说法在n年前第一次介绍给我时,我当时还真有点懵。
我心想,云平台(Cloud Platform)不就是Openstack这些东西吗,怎么又冒出来一个“云管”平台?
后来才弄明白,原来还是有点不同的。
云平台更多是指云计算平台,偏技术层面,提供计算、存储、数据库、网络、安全等基础设施服务,供客户在云上部署和运行应用程序。比如OpenStack提供IaaS,Docker和Kubernetes提供PaaS等,这些都属于云平台。
云管平台从名称上就能看出来,侧重于管理,侧重于多云、混合云、异构云场景下的统一管理。它给用户提供统一的运营控制台和运维控制台。所谓运营控制台,就是为用户提供登录、资源开通、使用、配置等功能,并且达到“自服务”的水平;所谓运维控制台,就是让运维人员可以对物理资源状况进行监控和管理。
所谓“
自服务”,是指客户可以通过平台界面或API,自行创建和管理虚拟机、存储空间、网络资源和其他云服务,而无需其他专业人员参与,自己点点鼠标,想要的东西就出现了,就能用了。
两者之间有一个明显的不同是:云管平台可以管理多云以及一朵云中的多个Region,而云平台通常只能管理本Region内的资源。
在我看来,云平台更偏技术一些,更靠近基础设施一些,云管平台则在云平台的基础上又做了一次封装,以更简便易用的方式将云服务提供给用户。
不过,正如“云计算”和“云原生”这两个词已经被人们混用,“云平台”和“云管平台”往往也被混用起来了,你听他说“云平台”,其实他很大概率是在说“云管平台”。
2、地域(Region)
Region即一朵云内某个物理区域中基础设施服务的集合。不同Region之间的物理资源(计算、存储、网络)是完全隔离不共享的。
一朵云里可以有多个Region,每个Region可位于不同的城市的DC(数据中心)
中,也可以位于同一个城市的不同DC中。不同DC能否放在一个Region中,关键看时延,如果时延超过 2ms,就应该在不同的Region中,因为同一Region内对时延有较高要求。
不同Region之间的时延也应该在100ms之内4,因为云管平台对Region的命令下发和信息上报时延也有要求。
不同Region之间的通信使用“云连接”,通过“专线网关”实现,这个网关可以是软件的,也可以是硬件交换机(又称专线交换机),这块见我下篇关于云网络的文章。
每个Region中包含数个独立的,物理分隔开的AZ,每个AZ可以有独立的供电,制冷。
3、可用区(AZ)
可用区(Available Zone,AZ)可以简单理解(虽然并非总是如此)
为机房及其内的计算、存储和网络资源。一个Region内有多个机房,每个机房就是一个AZ。不同AZ使用不同的电力和制冷,使用独立的计算、存储和网络资源(但网络是互通的)
。这样,即便一个AZ不可用了,另一个还是可用的。AZ内通信时延要小于0.25ms。
AZ中的A就是可用(Available)的意思,一般而言,不同AZ使用独立的电力、制冷、机房模块等基础环境。应用系统如果要实现高可用,应该同时部署多份在不同的可用区内,这样,一个AZ坏了,还有另一个AZ可以提供服务。
裸金属和不同CPU架构的物理机,通常部署在不同的AZ;同一个AZ内,又可以根据不同性能属性划分不同的主机组(host aggregate),便于管理员进一步按组分发虚机5。不同主机组提供不同的主机资源,但存储和网络资源是共享的。
VPC的子网是可以跨AZ的。比如在同一个子网中,VM1在AZ1,VM2在AZ2,他们可以同时承担Web服务器功能,这样,即便整个AZ1不可用了,VM2仍然能够提供服务。
4、SDN
传统的网络设备是分布式和去中心化的,每台设备可以通过自主学习和人工配置,知道如何转发数据包,而不需要一个集中式的控制设备。SDN则像各个网络设备的软件大脑,让各网络设备不再用自主学习和人工配置,而是由大脑下达命令,告诉各设备应该怎么转发数据包。
SDN(Software Defined Network)就是软件定义网络,那个大脑被称为SDN控制器。
SDN为什么要把原先的分布式运行改为集中控制呢?因为如果每个网络设备都要人工配置和管理,就会太麻烦,容易出错,不易于统一集中管控。如果能力足够,那就不如一起管了算了。
在虚拟网络里,像虚拟交换机、虚拟路由器、虚拟网关等等,这些虚拟网络设备,都受SDN统一管理。
5、网络资源池
网络资源池由一组网络硬件设备(如交换机、路由器等)构成,为上层的虚拟网络、虚机、存储等提供底层的通信功能。
说起来有点复杂,大体而言,应用系统在虚拟网络(Overlay)上跑,虚拟网络基于隧道技术在物理网络(Underlay)上跑。
从技术上讲,Overlay的二层数据包封装在Underlay的三层报文中传输,到达目的地之后再解封装得到Overlay的二层报文。实际上,这是一种“L2 over L3”的隧道封装技术,目前主流的隧道封装协议为VxLAN。
如果Overlay的网络数据封装和路由都是软件实现的,那就是软件SDN(又称主机Overlay),如果是硬件网络设备做的,那就是硬件SDN(又称网络Overlay)。
一个Region需要一套网络资源池,提供该Region内共用(多AZ、多VPC共用)的底层数据包转发,该资源池是由跨机房模块(也即跨AZ)的多组Leaf+Spine模块组成,跨机房模块的网络交换通过一组Core节点(Super Spine)交换机实现。
在主机Overlay这种主流场景下,网络资源池中的网络设备并不关心上层是哪个VM要和哪个VM通信,它们只是忠实地转发数据包而已,它们不会去关心隧道里的虚拟网络通信。
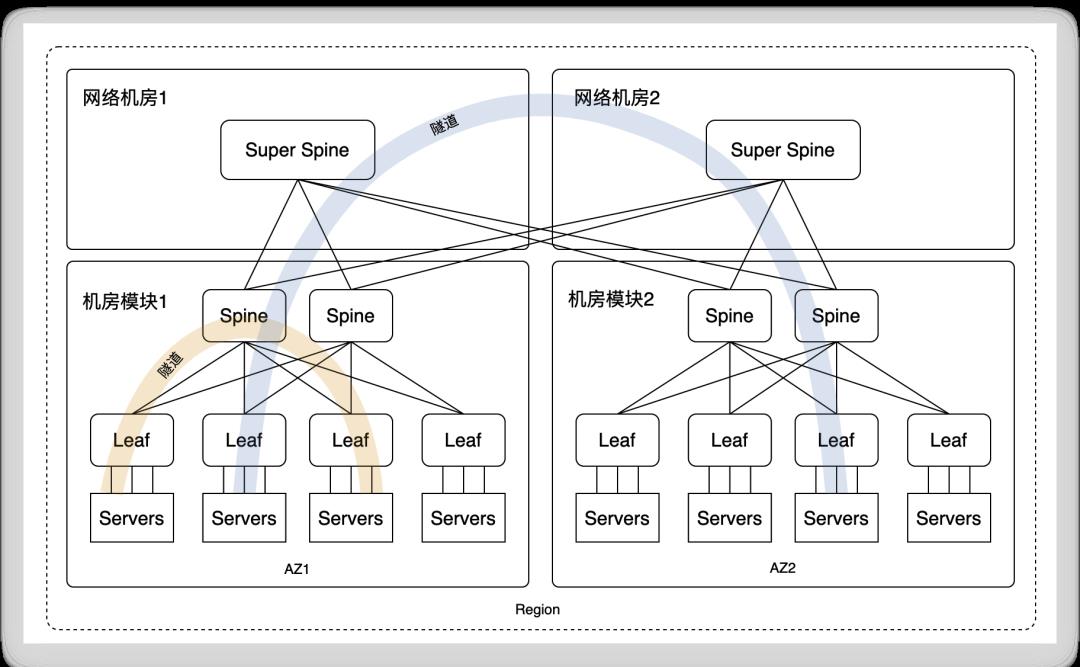 通过隧道,在物理网络上构建虚拟网络
通过隧道,在物理网络上构建虚拟网络
上图使用两台Super Spine,四台Spine,八台Leaf,并通过在不同机房部署,提供了一套网络资源池,供多个AZ共同使用。这样,虽然VPC子网和虚机可能在不同AZ和机房内,但通过VxLAN隧道,它们之间的通信就像在一个交换机下面的二层通信。
那么,云原生是什么
看到现在,你大概知道云原生是什么了吧。
整个IT被云化了,不管是搞开发的,还是搞运维的,都在使用云,依靠云,发展云。
IT的一切,都尽可能用软件定义,都尽可能虚拟化,一切都是为了简单、自动、弹性、安全。
所有使用云的人,都只是点点鼠标,就可以完成以前很复杂的事。
IT在给其他行业搞数字化转型的同时,给自己搞了个数字化转型。
本质上,IT人终于把自己给解放了。
他们感叹说,云里原来才是我们生活应有的样子。
文|卫剑钒
参考链接:
10+ Deploys Per Day: Dev and Ops Cooperation at Flickr(https://www.bilibili.com/video/av929343748/)
云原生:运用容器、函数计算和数据构建下一代应用(https://e.jd.com/30613841.html)
云Stack中Global、Region、AZ、资源池以及主机组 (https://bbs.huaweicloud.com/blogs/231197)
openstack中region、az、host aggregate、cell 概念 (http://t.zoukankan.com/xingyun-p-4703325.html)
以上是关于阀权值是个啥概念?的主要内容,如果未能解决你的问题,请参考以下文章