Python基础
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础相关的知识,希望对你有一定的参考价值。
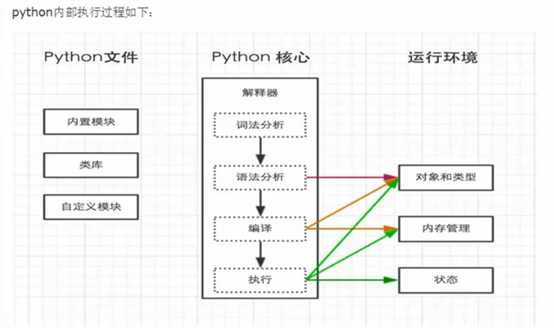
解释器
如果想要类似于shell脚本一样执行python脚本,例如:./test.py,那么就需要在test.py中的文件头部指定解释器,
1 #! /usr/bin/env python 2 3 print (‘test‘)
然后执行./test.py 就可以了。
若在linux中执行前需要给.py文件赋予执行权限, chmod 755 xxx.py
编码
2**8 ASCII 美国信息交换标准代码 是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
例:00000001
11000000
Unicode 至少16位 是计算机科学领域里的一项业界标准,包括字符集、编码方案等
例:0000000000000001
utf-8 是一种针对Unicode的可变长度字符编码,又称万国码。
英文占两个字节,16位
中文占三个字节,24位
在python中utf-8转换成gbk的过程:
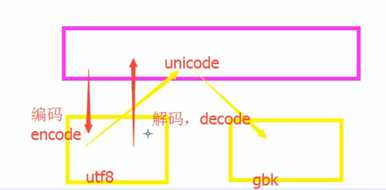
先将utf-8解码成Unicode,再从Unicode转换成gbk
pyc文件
在执行python代码中,如果导入了其他的.py 文件,那么就会在执行过程中自动生成一个与其同名的.pyc文件
,该文件就是Python解释器编码之后长产生的字节码
ps:代码经过编译可以产生字节码;字节码可以通过反编译也可以得到字节码;
.py 文件先通过解释器生成字节码,再从字节码生成机器码,然后在cpu执行
python中存在小数字池:-5~257
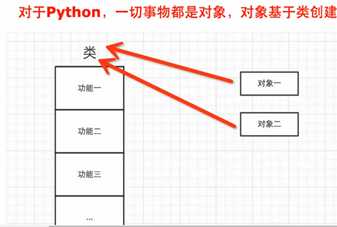
对象的功能都是在类里找的
Int 内部功能__add_例如
__floordiv__=1//2 只取整数部分
学语言 集合和字符串最重要
Python中的集合是列表元组字典
字符串:
__contain__() 判断字符串是否包含括号里的内容
1 >>> name = ‘1234‘ 2 >>> result = name.__contains__(‘1‘) 3 >>> print(result) 4 True
.casefold() 将其变为小写
1 >>> name = ‘RESULT‘ 2 >>> result = name.casefold() 3 >>> print(result) 4 result
.center 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格。
1 >>> name = ‘RESULT‘ 2 >>> result = name.center(30,‘-‘) 3 >>> print(result) 4 ------------RESULT------------
.count 计数
1 >>> result=‘1234567891111‘ 2 >>> result1=result.count(‘1‘) 3 >>> print(result1) 4 5
.encode 方法以 encoding 指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
.decode 方法以指定的编码格式解码 bytes 对象。默认编码为 ‘utf-8‘。(‘enconding’,‘errors’)
- encoding -- 要使用的编码,如"UTF-8"。
- errors -- 设置不同错误的处理方案。默认为 ‘strict‘,意为编码错误引起一个UnicodeError。 其他可能得值有 ‘ignore‘, ‘replace‘, ‘xmlcharrefreplace‘, ‘backslashreplace‘ 以及通过 codecs.register_error() 注册的任何值。
1 str = "测试"; 2 utf8 = str.encode("UTF-8") 3 gbk = str.encode("GBK") 4 5 print(str) 6 7 print("UTF-8 编码:", utf8) 8 print("GBK 编码:", gbk)
10 print("UTF-8 解码:", utf8.decode(‘UTF-8‘,‘strict‘)) 11 print("GBK 解码:", gbk.decode(‘GBK‘,‘strict‘)).endswith() 以什么结尾 0,3 是大于等于0小于3
-
1 >>> result = ‘test‘ 2 >>> result1 = result.endswith(t) 3 >>> result1 = result.endswith(‘t‘) 4 >>> print (result1) 5 True 6 >>> result1 = result.endswith(‘s‘,0,3) 7 >>> print (result1) 8 True
.expandtabs 将tab转换成空格
.find,index 找某个子序列,然后返回子序列的位置 有些区别find没找到返回false,另一个报错
1 >>> result1= result.find(‘e‘) 2 >>> print(result1) 3 1
.format 拼接
1 >>> result = "result {0}" 2 >>> result1 = result.format(‘test‘) 3 >>> print(result1) 4 result test
join 拼接
1 >>> name = [‘t‘,‘e‘,‘s‘,‘t‘] 2 >>> result ="".join(name) 3 >>> print(result) 4 test 5 >>> result ="~".join(name) 6 >>> print(result) 7 t~e~s~t
.ljust 放在左边 rjust 放在右边 center 放在中间
.lower小写
.lstrip 只去掉左边的()
.rstrip
.partition 分割
1 >>> name = ‘printthistest‘ 2 >>> result = name.partition(‘this‘) 3 >>> print (result) 4 (‘print‘, ‘this‘, ‘test‘)
.replace 替换(’’要替换的老字符,’替换成什么字符’,x)x=转换几个
1 >>> name = ‘printthistest‘ 2 >>> result = name.replace(‘this‘,‘-‘) 3 >>> print (result) 4 print-test 5 >>>name = ‘printthisthistest‘ 6 >>> result = name.replace(‘this‘,‘-‘,1) 7 >>> print (result) 8 print-thistest 9 >>> result = name.replace(‘this‘,‘-‘,2) 10 >>> print (result) 11 print--test 12 >>>
rfind 从右向左找
1 >>> name = ‘printthisthistest‘ 2 >>> result = name.rfind(‘this‘) 3 >>> print(result) 4 9
rsplit 从左指定字符分割字符串
1 >>> name = ‘1,2,3,4,5,6,7,8,9‘ 2 >>> result = name.rsplit(‘3‘) 3 >>> print(result) 4 [‘1,2,‘, ‘,4,5,6,7,8,9‘] 5 >>>
startwith 以…开头
swapcase 大小写转换
title 将你第一个字母大写
upper 大写
List:
clear 把列表清空
1 >>> list = [1,2,3,4,5,6,7] 2 >>> list1 = list.clear 3 >>> print (list1) 4 <built-in method clear of list object at 0x01FF8210>
append往列表的最后添加
>>> print (list) [1, 2, 3, 4, 5, 6, 7] >>>list.append(‘100‘) >>> print (list) [1, 2, 3, 4, 5, 6, 7, ‘100‘]
copy 这里的copy是浅拷贝 只是把第一层拷贝了
>>> list1 = list.copy() >>> print(list1) [1, 2, 3, 4, 5, 6, 7, ‘100‘] >>>
count 计数
>>> list [1, 2, 3, 4, 5, 6, 7, ‘100‘, ‘100‘] >>> list1 = list.count(‘100‘) >>> list1 2
extend 扩展一个列表,或扩展一个元组,括号是元组 列表是[]
>>> list.extend([100]) >>> list [1, 2, 3, 4, 5, 6, 7, ‘100‘, 100] >>> list.extend(‘100‘) >>> list [1, 2, 3, 4, 5, 6, 7, ‘100‘, 100, ‘1‘, ‘0‘, ‘0‘] >>>
insert指定下标添加
>>> list.insert(10,4) >>> list [1, 2, 3, 4, 5, 6, 7, ‘100‘, ‘100‘, 100, 4, ‘1‘, ‘0‘, ‘0‘, 1] >>>
index 下标
pop 默认拿走一个元素,可以下标
>>> list [1, 2, 3, 4, 5, 6, 7, ‘100‘, ‘100‘, 100, 4, ‘1‘, ‘0‘, ‘0‘, 1] >>> list.pop(3) 4 >>> list [1, 2, 3, 5, 6, 7, ‘100‘, ‘100‘, 100, 4, ‘1‘, ‘0‘, ‘0‘, 1] >>> pop1=list.pop(0) >>> pop1 1 >>> list [2, 3, 5, 6, 7, ‘100‘, ‘100‘, 100, 4, ‘1‘, ‘0‘, ‘0‘, 1] >>>
remove 指定删除哪一个值
>>> list [2, 3, 5, 6, 7, ‘100‘, ‘100‘, 100, 4, ‘1‘, ‘0‘, ‘0‘, 1] >>> list.remove(100) >>> list [2, 3, 5, 6, 7, ‘100‘, ‘100‘, 4, ‘1‘, ‘0‘, ‘0‘, 1] >>> list.remove(‘100‘) >>> list [2, 3, 5, 6, 7, ‘100‘, 4, ‘1‘, ‘0‘, ‘0‘, 1] >>>
sort 排序
reverse 将顺序反过来
>>> list=[1,2,3,4,5] >>> list.reverse() >>> list [5, 4, 3, 2, 1]
这些当中 append,extend,pop,rerverse比较多用到
写元组和列表的时候一定最后带,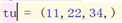
>>> tu = [11,22,34,] >>> tu [11, 22, 34] >>> tu = tuple([11,22,34,]) #tuple将这个[列表]转为(元组) >>> tu (11, 22, 34)
list是将元组转换成列表
Tuple只有count和index
字典
字典是映射类型
循环时,默认循环key
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
dic = dict(k1=‘v1‘,k2=‘v2‘) 这两个是相等的
clear 清空字典里的所有元素
1 >>> dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘} 2 >>> dic 3 {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘} 4 >>> dic.clear() 5 >>> dic 6 {}
copy 浅拷贝
1 >>> dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘} 2 >>> dic2 =dic.copy() 3 >>> dic2 4 {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘} 5 >>>
fromkeys 用于创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值。
>>> newdic=dic.fromkeys([‘k1‘,‘k2‘,‘k3‘],‘values‘) >>> newdic {‘k1‘: ‘values‘, ‘k2‘: ‘values‘, ‘k3‘: ‘values‘} >>>
get k3本身不存在,正常print会报错 而get没
有‘’里的内容就是显示None
1 >>> newdic 2 {‘k1‘: ‘values‘, ‘k2‘: ‘values‘, ‘k3‘: ‘values‘} 3 >>> print(newdic.get(‘k1‘)) 4 values 5 >>> print(newdic.get(‘k4‘)) 6 None 7 >>> print(newdic.get(‘k3‘)) 8 values 9 >>>
update 把字典dict2的键/值对更新到dict里。
1 >>> dic 2 {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘} 3 >>> newdic 4 {‘k1‘: ‘values‘, ‘k2‘: ‘values‘, ‘k3‘: ‘values‘} 5 >>> dic.update(newdic) 6 >>> dic 7 {‘k1‘: ‘values‘, ‘k2‘: ‘values‘, ‘k3‘: ‘values‘} 8 >>>
小练习

1 tu = [11,22,33,44,55,66,77,88,99] 2 dic = {} 3 for i in tu: 4 if i>66: 5 if ‘k1‘ in dic.keys(): 6 dic[‘k1‘].append(i) 7 else: 8 dic[‘k1‘]=[i,] 9 else: 10 if ‘k2‘ in dic.keys(): 11 dic[‘k2‘].append(i) 12 else: 13 dic[‘k2‘]=[i,] 14 print(dic)
以上是关于Python基础的主要内容,如果未能解决你的问题,请参考以下文章