调试器是个大骗子!
Posted 轩辕之风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了调试器是个大骗子!相关的知识,希望对你有一定的参考价值。
我叫GDB,是一个调试器,程序员通过我可以调试他们编写的软件,分析其中的bug。
作为一个调试器,调试分析是我的看家本领,像是给目标进程设置断点,或者让它单步执行,又或是查看进程中的变量、内存数据、CPU的寄存等等操作,我都手到擒来。
你只要输入对应的命令,我就能帮助你调试你的程序。
我之所以有这些本事,都得归功于一个强大的系统函数,它的名字叫ptrace。

不管是开始调试进程,还是下断点、读写进程数据、读写寄存器,我都是通过这个函数来进行,要是没了它,我可就废了。
它的第一个参数是一个枚举型的变量,表示要执行的操作,我支持的调试命令很多都是靠它来实现的:
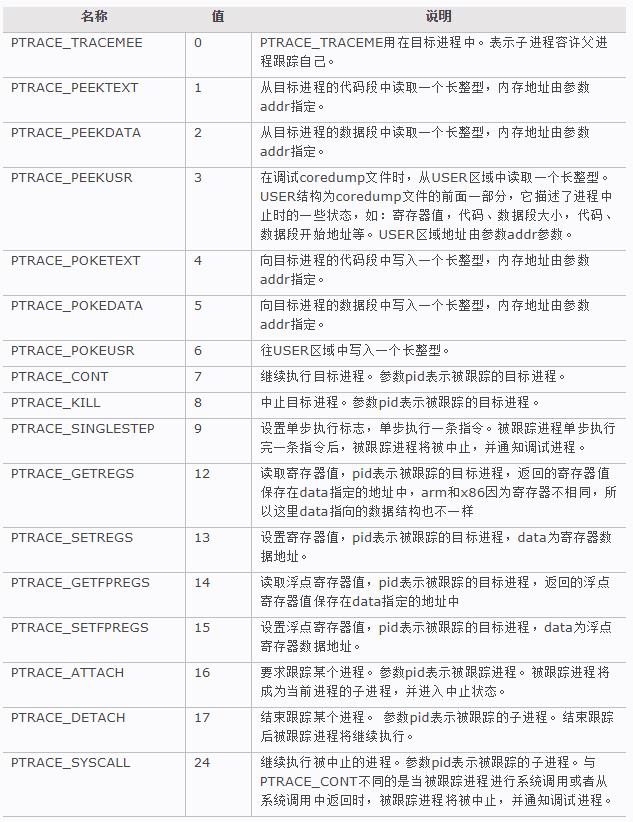
你可以通过我来启动一个新的进程调试,我会使用fork创建出一个新的子进程,然后在子进程中通过execv来执行你指定的程序。
不过在执行你的程序之前,我会在子进程中调用ptrace函数,然后指定第一个参数为PTRACE_TRACEME,这样一来,我就能监控子进程中发生的事情了,也才能对你指定的程序进行调试。
你也可以让我attach到一个已经运行的进程分析,这样的话,我直接调用ptrace函数,并且指定第一个参数为PTRACE_ATTACH就可以了,然后我就会变成那个进程的父进程。
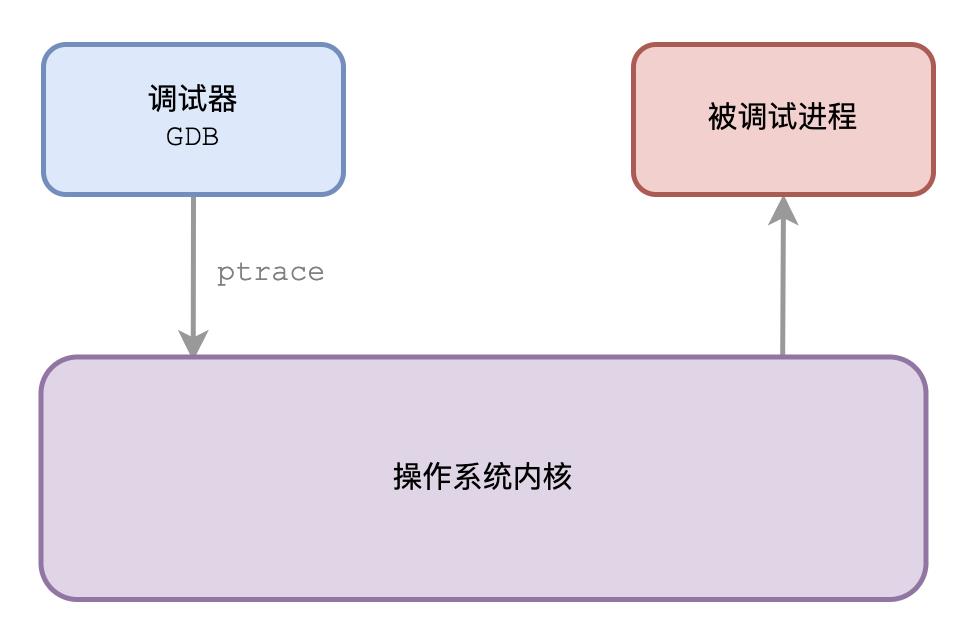
具体要选择哪种方式来调试,这就看你的需要了。不过不管哪种方式,最终我都会“接管”被调试的进程,它里面发生的各种信号事件我都能得到通知,方便我对它进行调试操作。
软件断点
作为一个调试器,最常用的功能就是给程序下断点了。
你可以通过break命令告诉我,你要在程序的哪个位置添加断点。
当我收到你的命令之后,我会偷偷把被调试进程中那个位置的指令修改为一个0xCC,这是一条特殊指令的CPU机器码——int 3,是x86架构CPU专门用来支持调试的指令。
我的这个修改是偷偷进行的,你如果通过我来查看被调试进程的内存数据,或者在反汇编窗口查看那里的指令,会发现跟之前一样,这其实是我使的障眼法,让你看起来还是原来的数据,实际上已经被我修改过了,你要是不信,你可以另外写个程序来查看那里的数据内容,看看我说的是不是真的。
一旦被调试的进程运行到那个位置,CPU执行这条特殊的指令时,会陷入内核态,然后取出中断描述符表IDT中的3号表项中的处理函数来执行。
IDT中的内容,操作系统一启动早就安排好了,所以系统内核会拿到CPU的执行权,随后内核会发送一个SIGTRAP信号给到被调试的进程。
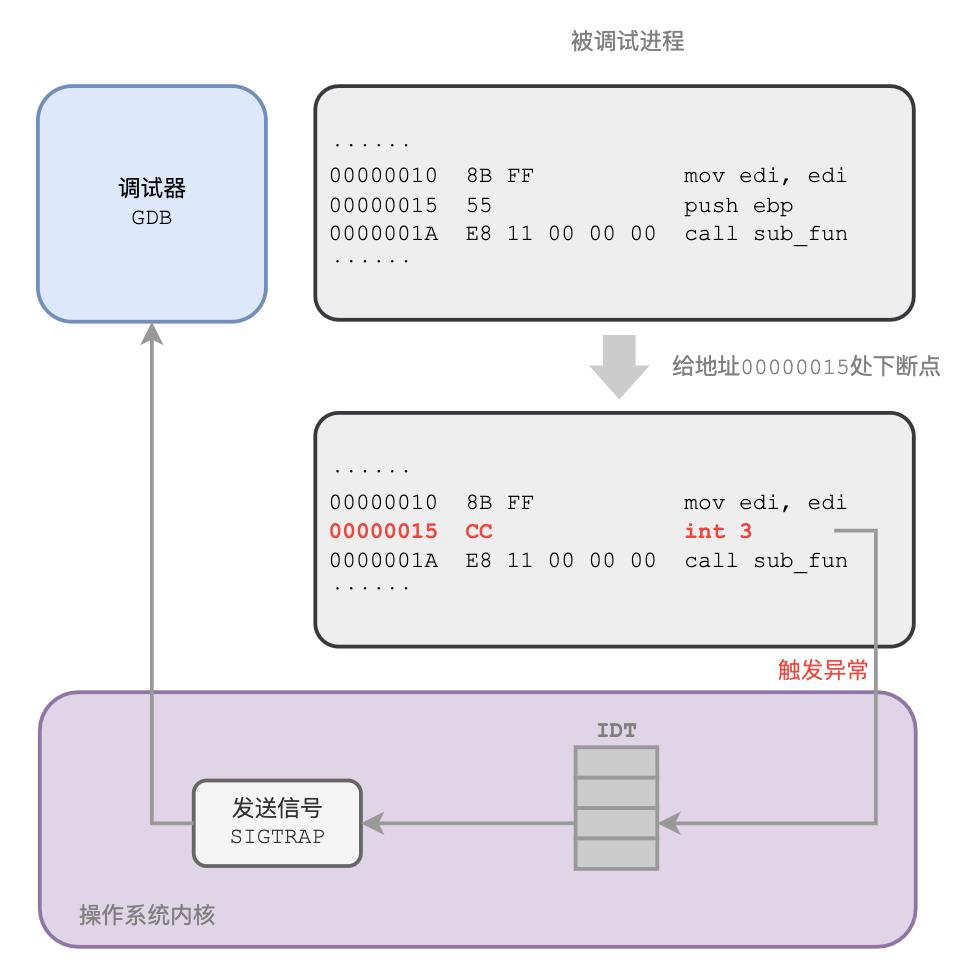
而因为我的存在,这个信号会被我截获,我收到以后会检查一下是不是程序员之前下的断点,如果是的话,就会显示断点触发了,然后等待程序员的下一步指示。
在没有下一步指示之前,被调试的进程都不会进入就绪队列被调度执行。
直到你使用continue命令告诉我继续,我再偷偷把替换成int 3的指令恢复,然后我再次调用ptrace函数告诉操作系统让它继续运行。
这就是我给程序下断点的秘密。
不知道你有没有发现一个问题,当我把替换的指令恢复后让它继续运行,以后就再也不会中断在这里了,可程序员并没有撤销这个断点,而是希望每次执行到这里都能中断,这可怎么办呢?
我有一个非常巧妙的办法,就是让它单步执行,只执行一条指令,然后又会中断到我这里,但这时候我并不会通知程序员,而仅仅是把刚才恢复的断点又给打上(替换指令),然后就继续运行。这一切都发生的神不知鬼不觉,程序员根本察觉不到。
单步调试
说到单步执行,应该算是程序员调试程序的时候除了下断点之外最常见的操作了,每一次只让被调试的进程运行一条指令,这样方便跟踪排查问题。
你可能很好奇我是如何让它单步执行的呢?
单步执行的实现可比下断点简单多了,我不用去修改被调试进程内存中的指令,只需要调用ptrace函数,传递一个PTRACE_SINGLESTEP参数就行了,操作系统会自动把它设置为单步执行的模式。
我也很好奇操作系统是怎么办到的,就去打听了一下。
原来x86架构CPU有一个标志寄存器,名叫eflags,它里面不止包含了程序运行的一些状态,还有一些工作模式的设定。
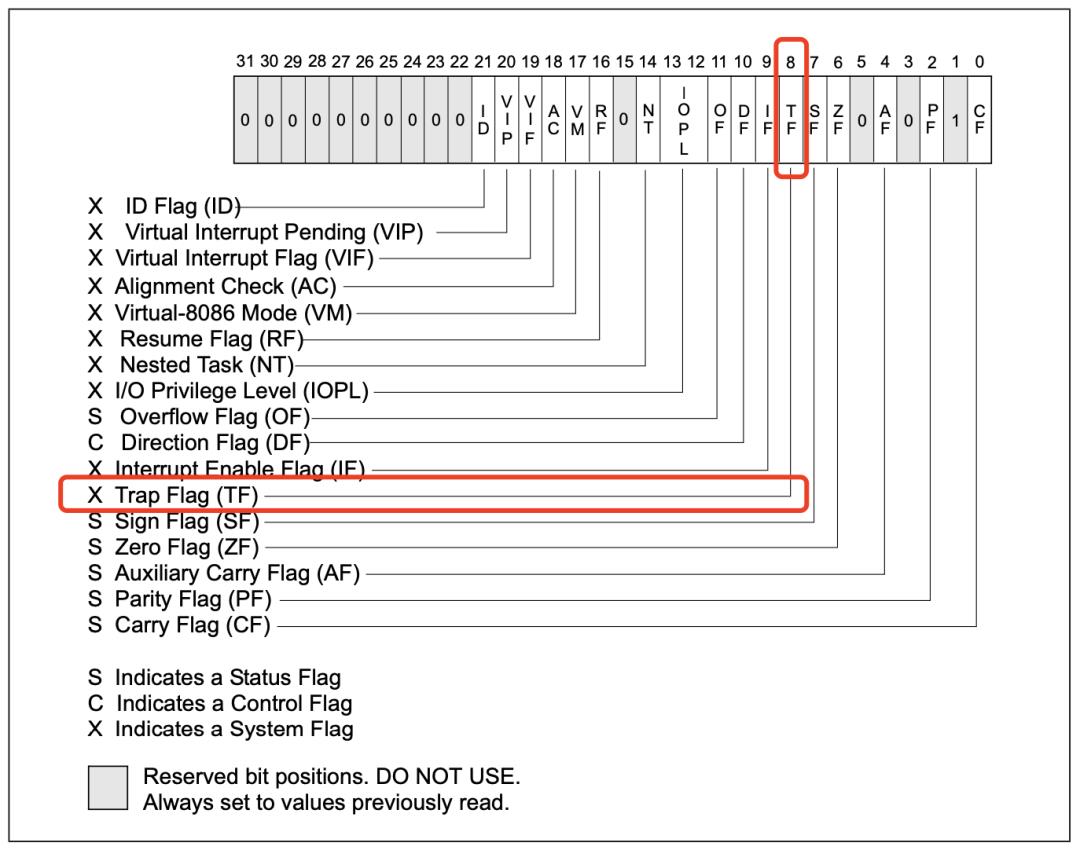
其中就有一个TF标记,用来告诉CPU进入单步执行模式,只要把这个标记为设置为1,CPU每执行一条指令,就会触发一次调试异常,调试异常的向量号是1,所以触发的时候,都会取出IDT中的1号表项中的处理函数来执行。
接下来的事情就跟命中断点差不多了,我会截获到内核发给被调试进程的SIGTRAP信号,然后等待程序员的下一步指令。
如果你继续进行单步调试,那我便继续重复这个过程。
如果你有程序的源代码,你还可以进行源码级别的单步调试,不过这里的单步就指的是源代码中的一行了。
这种情况下要稍微麻烦一点,我还要分析出每一行代码对应的指令有哪些,然后用上面说的单步执行指令的方法,一条条指令快速掠过,直到这一行代码对应的指令都执行完成。
内存断点
有的时候,直接给程序中代码的位置下断点并不能包治百病。比如程序员发现某个内存地址的内容老是莫名其妙被修改,想知道到底是哪个函数干的,这时候连地址都没有,根本没法下断点。
单步执行也不行,那么多条指令,得执行到猴年马月去才能找到?
不用担心,我可以帮你解决这个烦恼。
你可以通过watch命令告诉我,让我监视被调试进程中某个内存地址的数据变化,一旦发现被修改,我都会把它给停下来报告给你。
猜猜我是如何做到的呢?
我可以用单步执行的方式,每执行一步,就检查一下内容有没有没修改,一旦发现就停下来通知你们程序员。
不过这种方式实在是太麻烦了,会严重拖垮被调试进程的性能。
好在x86架构的CPU提供了硬件断点的能力,帮我解决了大问题。
在x86架构CPU的内部内置了一组调试寄存器,从DR0到DR7,总共8个。通过在DR0-DR3中设置要监控的内存地址,然后在DR7中设置要监控的模式,是读还是写,剩下的交给CPU就好了。

CPU执行的时候,一旦发现有符合调试寄存器中设置的情况发生时,就会产生调试异常,然后取出IDT中的1号表项中的处理函数来执行,接下来的事情就跟单步调试产生的异常差不多了。
CPU内部依靠硬件电路来完成监控,可比我们软件一条一条的检查快多了!
现在,你不止可以使用watch命令来监控内存被修改,还可以使用rwatch、awatch命令来告诉我去监控内存被读或者被写。
我叫GDB,是你调试程序的好伙伴,现在你该知道我是如何工作的了吧!
【完】
这里是编程技术宇宙,一个专注用故事分享硬核又有趣计算机知识的公众号~
觉得不错的话,欢迎一键三连哦~
Expert 诊断优化系列------------------锁是个大角色
前面几篇已经陆续从服务器的几个大块讲述了SQL SERVER数据库的诊断和调优方式。加上本篇可以说已经可以完成常规的问题诊断及优化,本篇就是SQL SERVER中的锁。为了方便阅读给出系列文章的导读链接:
SQL SERVER全面优化-------Expert for SQL Server 诊断系列
首先阅读本文之前,大家都应该知道锁是影响你性能的一个重大因素,那么SQL SERVER为什么要引入锁呢?那就是要解决多个用户同时对数据库的并发操作时会带来以下数据不一致的问题。我想为了保证数据一致性,哪怕牺牲再多也是值得的!本文主要介绍怎么找到这个牺牲的点,及如何让你的牺牲降到最低!
还记得等待篇中的那个北京三环么?

等待很多时候都是在等待获取对象上的锁!当数据库中出现很多很多锁时,系统瞬间就无法提供正常服务。此时观察系统资源的使用情况,会发现CPU使用率不高,内存占用量也不高,还有很多未使用的内存,网络带宽也充足,硬盘也不繁忙,通过数据库管理工具查询的话,SQL SERVER中的数据也正常无误,但是使用系统的用户访问此数据库时却要需要等很多久很久,更多的就出现连接超时,数据库无响应。
这就好比本来就是早高峰,前面还撞了!十一车连撞很壮观,对于数据库十一条连锁,也很给力!
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
废话不多说,直接开整-----------------------------------------------------------------------------------------
锁造成的等待主要有两种:和 LCK_ 和 PAGELATCH_
PAGELATCH_:轻量级数据库内部使用的闩锁,这里不介绍
LCK_ : 八斤半的大锁这里就说它!
注 : 锁相关的基础知识请自行百度学习!
-
诊断锁常用的性能计数器
- Lock Requests/sec 每秒锁请求数
- Lock Waits/sec 每秒锁等待数
- Lock Wait Time (ms) 锁等待时间
- Average Wait Time (ms) 平均等待时间
- Number of Deadlocks/sec 每秒死锁数
- Latch Waits/sec 闩锁等待数
- Average Latch Wait Time (ms) 闩锁平均等待时间
计数器不过多介绍,不会用的朋友请自行百度。直接上例子:
这个例子中客户反映特定时间点系统特别慢严重影响业务,那么我们按常规顺序进行一次全面分析。
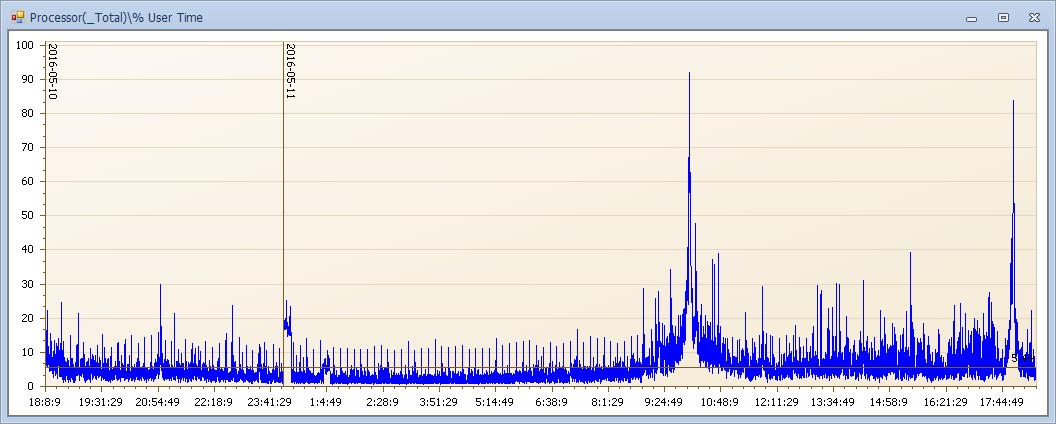
CPU来看在10点左右和晚上6点左右出现90%以上的高峰。
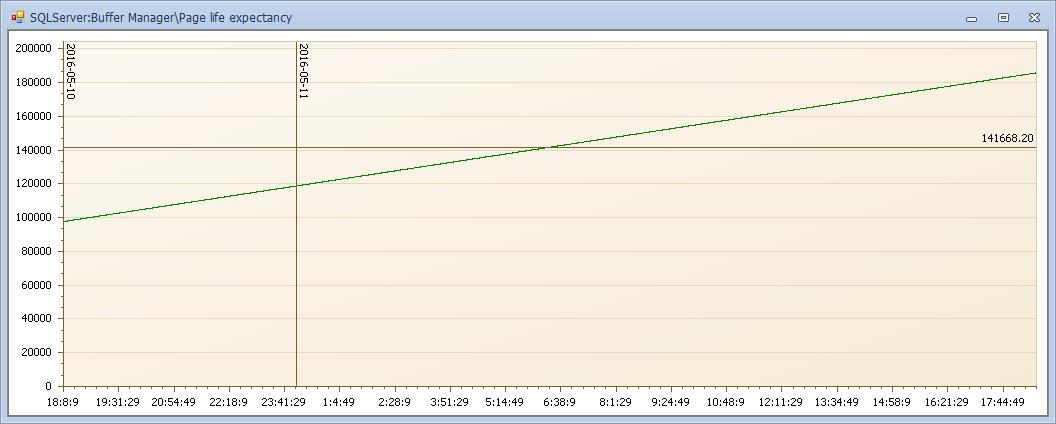
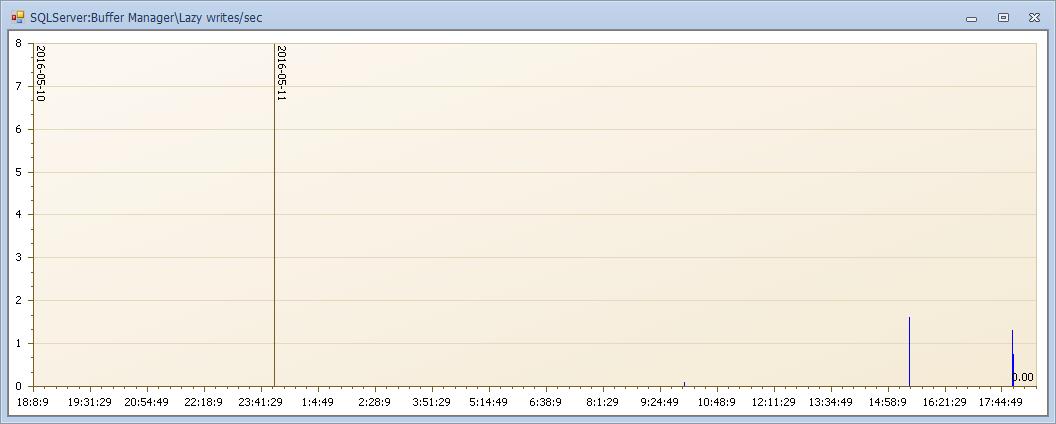
页生命周期和惰性写入器可以看出内存并无明显的压力
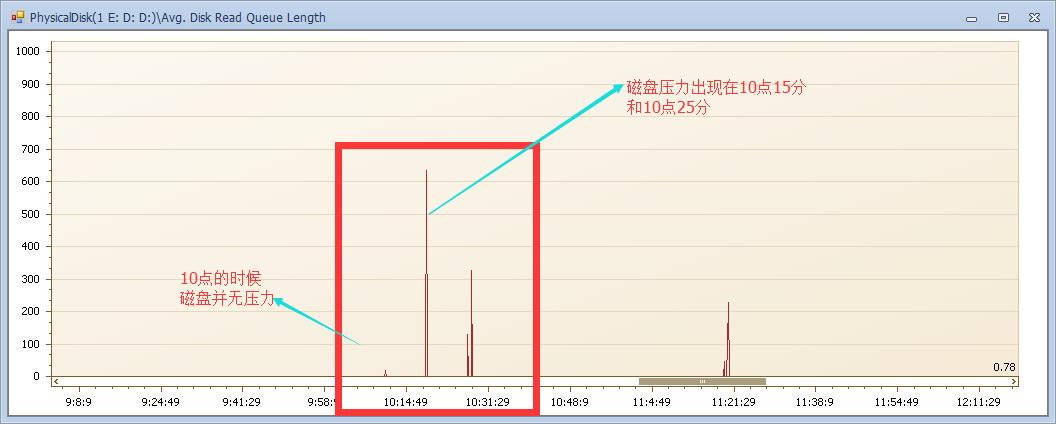
以10点为例(为什么不看六点?我默默地分析过是一样的情况)磁盘队列并不高,但10点15分的时候出现磁盘高压力。那么这是一个问题导致的还是两个呢?我们接着看。
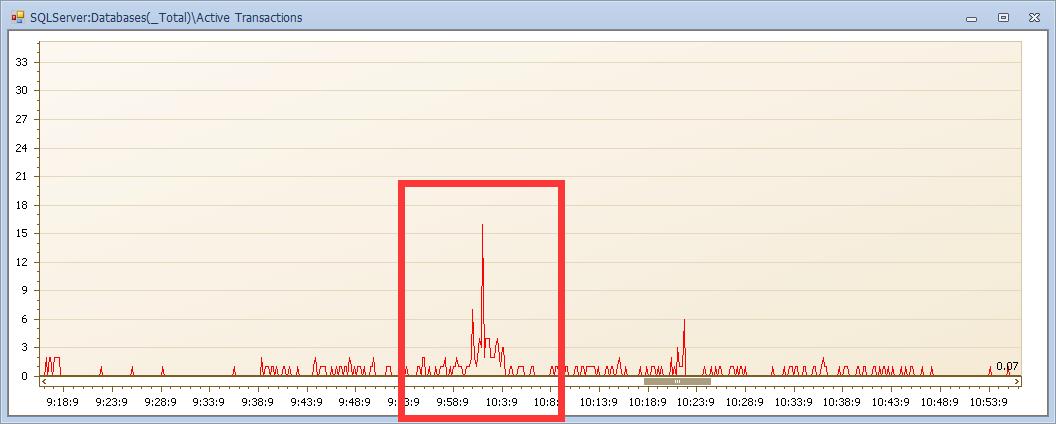
事务活动数在10点的时候达到一个很高的值。
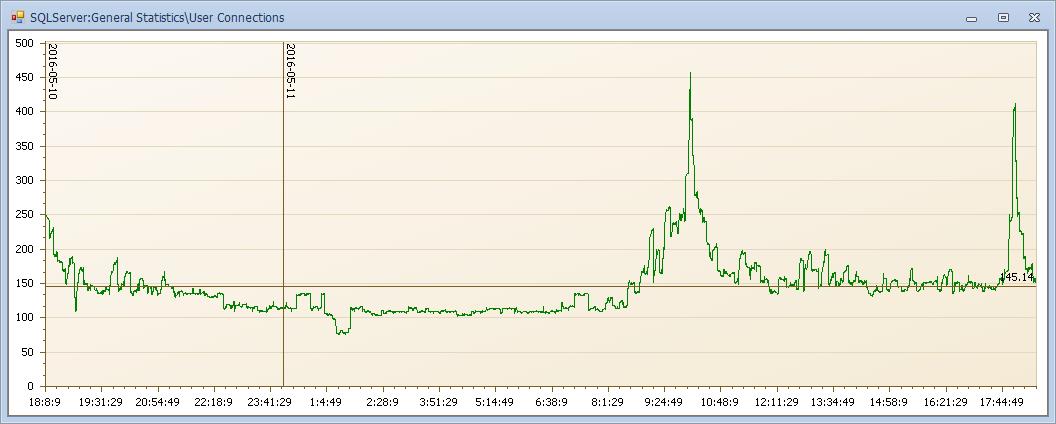
用户连接数在10点也彪高,那么问题清楚了,就是10点时候是用户连接太多了压力大了导致系统慢的!别天真了这篇主题是锁,主角还没出场怎么能结束? 反复强调不要轻易下结论!
连接数量多,还一个原因就是连接执行语句的时间长很长时间才能释放,那么其他的应用只能打开新连接,所以连接数会彪高,
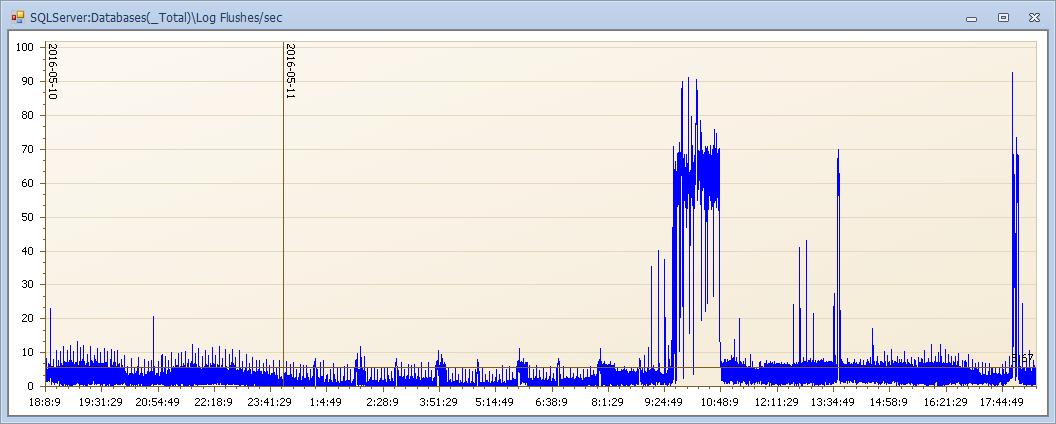
log刷新数量彪高这时间点在insert、delete或update?(后文证实是update)
-----------------------------------------下面进入正题了--------------------
我大量update系统会很慢?会跑不动?
我们看下锁相关的计数器
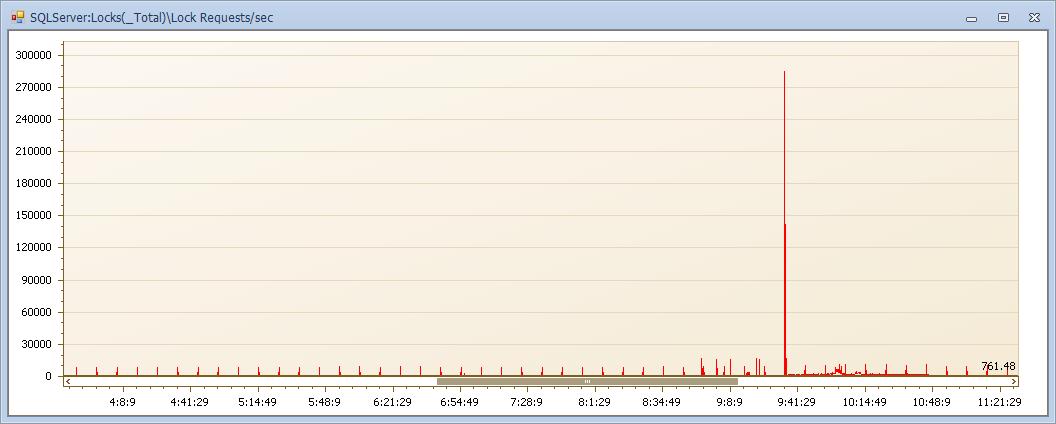
锁请求数! 这个时间点大量的锁请求产生!
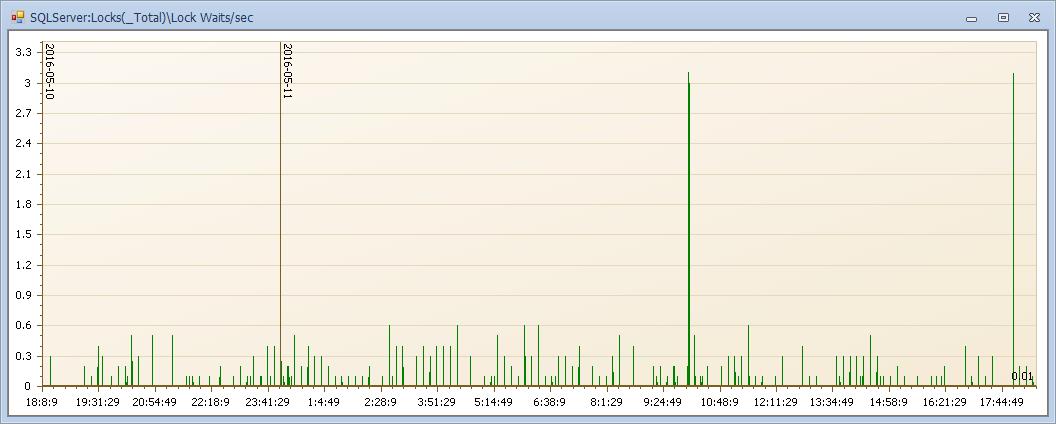
锁等待,大量锁等待
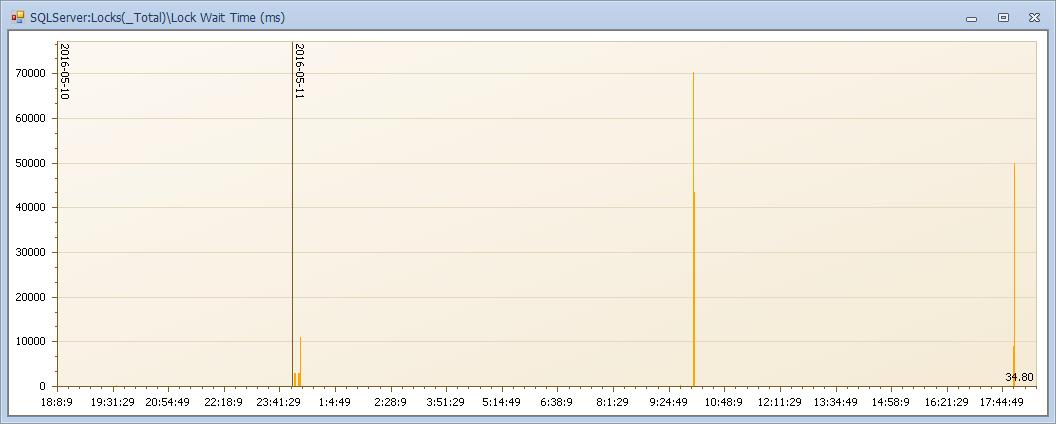
再看等待时间,高峰点已经达到了70秒!! 要等待70秒是啥概念? 简直是高考学校门口,还是个早高峰!!
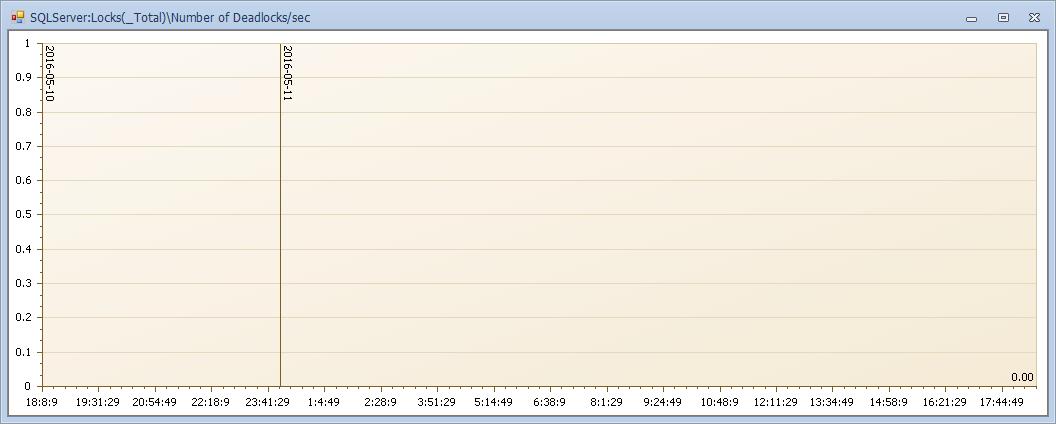
天啊,还好没有死锁....
------------------------------语句及等待诊断--------------------
我通过计数器可以发现2个主要问题:1. 十点的时候大量update更新,导致系统大面积阻塞,语句运行时间过长。2.十点15分以后有大量磁盘读操作,导致磁盘队列暴增。
下面我们看一下语句和等待的情况:
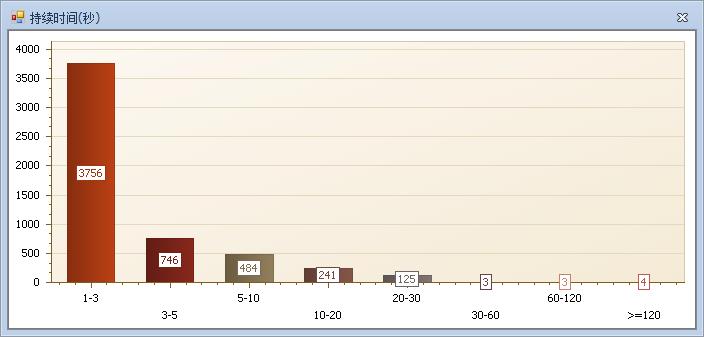
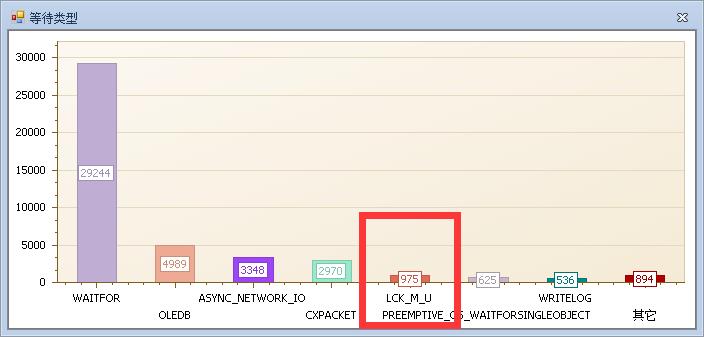
语句和等待总体反应情况很正常,长时间语句少,而且等待并不严重。那么说明,这么系统问题点就是在特定时间点(这也是用户反应的系统慢的原因,开篇就已经提过)
那下面我们就深入10点,看看那时候到底怎么了!
首先 我们先看看语句情况!
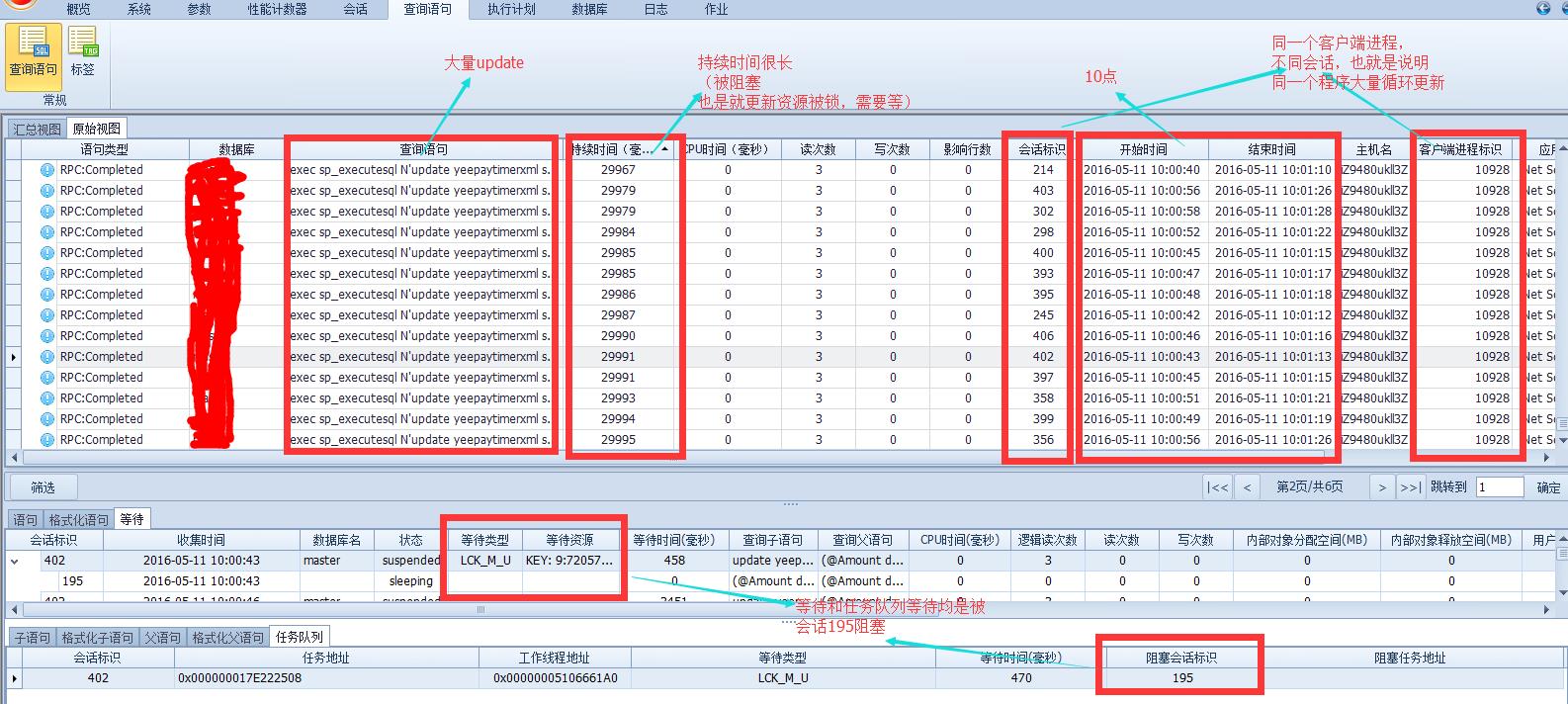
上面图中我们只是展示了问题时点的一部分语句,主要可以看出如下结论:
- 问题时间点确实有大量的更新操作
- 更新操作被严重阻塞(锁)
- 且是一个程序循环调用的更新
- 语句运行时间长
- CPU高是因为这个时间点除了update以外还有大量的查询导致CPU高(一般情况下,系统大面积锁等待的时候CPU 资源不能有效利用,CPU会低)
接着我们看一下等待的情况,看看到底是怎么搞得,竟然锁的这么厉害!
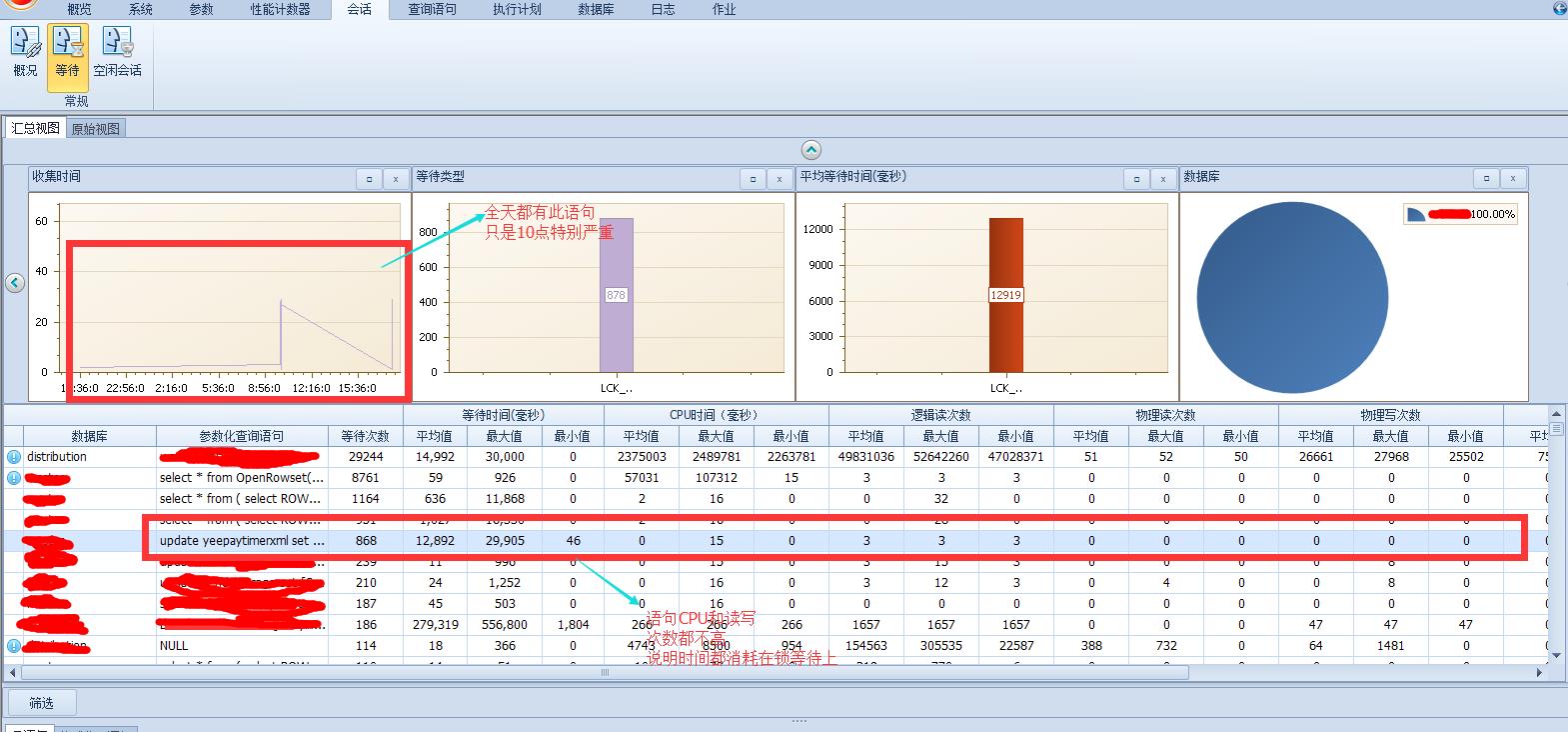
语句总体等待来看全天都有但十点大量,并且造成系统卡死(默认30秒超时,很多都应该超时了,所以用户体验非常差!),语句的CPU和读写都不多,也说明就是相互锁的很严重!
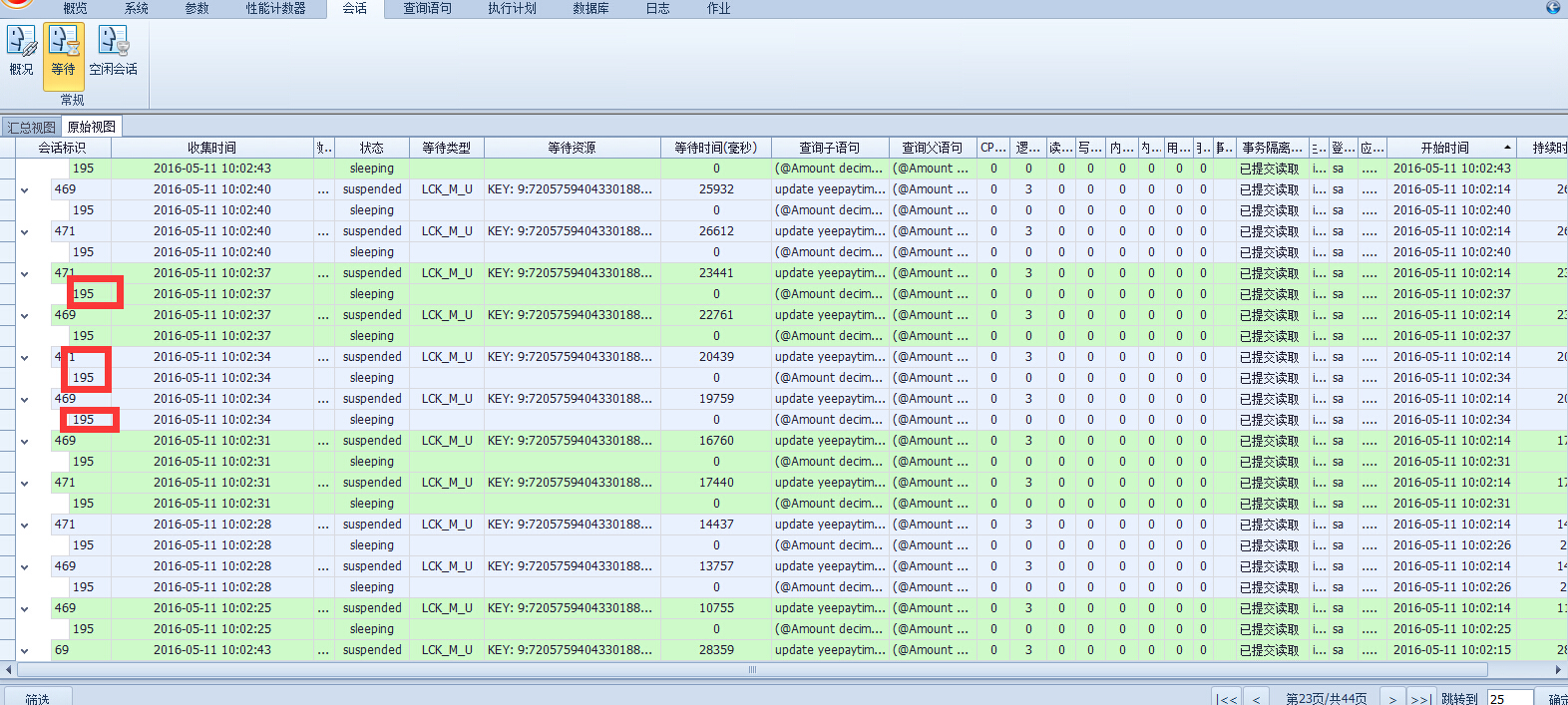
大量的语句都是被195锁住的,而195其实本身也是同样的一个update,客户的程序中有频繁的这条update,并且在10点的时候会有另一个程序的一次大批量的循环更新,这也是造成这个大面积锁阻塞的原因!
这个问题的一个最终解决办法就是修改这个大批的循环更新,首先把每个单次处理和计算的结果进行统一计算,在做一次批量更新。这样既缩短事务的时间,降低锁定的时间。同时也降低了整个批语句的执行时间!
类似以SQL 中的游标,和程序中的for 循环单条操作,都可以修改成批量处理,不仅可以减少事务长度,减少锁时间,更是一种很有效的优化手段 !
第二个问题,磁盘10点15为什么那么高?和更新有关系?
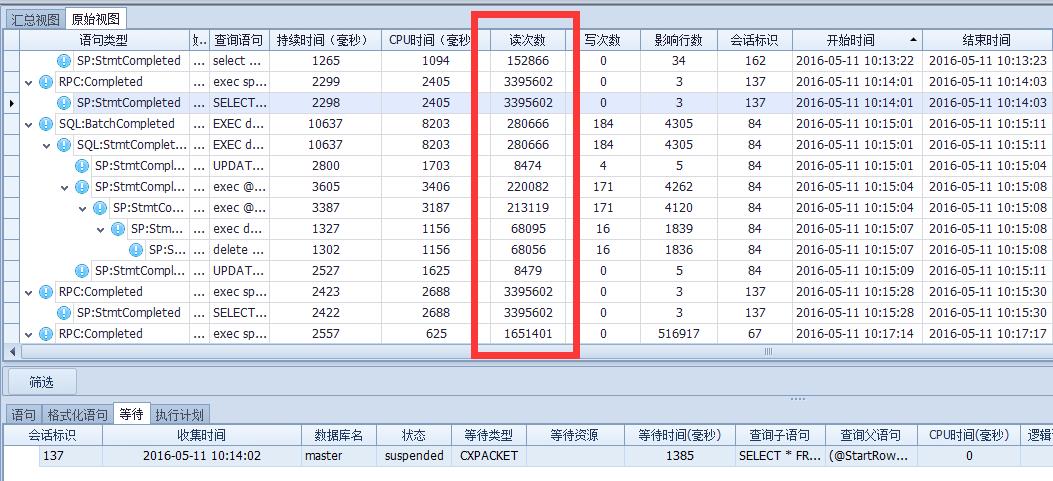
这里可以看出第二个问题10点15的时候确实有很多大逻辑读的查询,还跟新没什么关系,但和业务有无关联就不得而知了。导致系统磁盘压力变大,和主题关系不大这里不说了..
-
关于锁的一个小误区
select 会阻塞 update 么? (这里指的是默认隔离级别,read committed)
上段简单小代码

create table a (a int) insert into a select OBJECT_ID from sys.objects where object_id between 1 and 1000 begin tran select * from a with(holdlock) where a = 3 --------------新开一个session 执行 update a set a = 30 where a = 3
这里的with(holdlock) 是让查询保持S锁,模拟你的查询还没结束。
sp_who2 或 select session_id,status,command,blocking_session_id,wait_type from sys.dm_exec_requests where session_id = 58 查看一下

高能预警: 查询也会阻塞更新的哦~~
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
总结:语句运行时间长,很可能的一个原因就是阻塞导致的,而阻塞大部分情况都是因为资源之间的所等待。
语句调优的时候有必要对系统做一个全面的分析。(如本文所讲)
锁的优化可以说是比较深入问题分析,减少锁的相互影响,主要也可以从语句优化入手,降低消耗缩短时间。另外也可以从业务设计方面入手,降低热点资源的争用。
锁主要是为了维护数据一致性而不得不做的牺牲。我们只能尽一切办法降低他的影响。
PS:限于篇幅本文没有讲述一些基本知识,请自行学习,如隔离级别、锁矩阵兼容性等等.....
补上使用工具链接 : Expert for sqlserver
----------------------------------------------------------------------------------------------------
原创链接:http://www.cnblogs.com/double-K/archive/2016/06/02/5538249.html
为了方便阅读给出系列文章的导读链接:
SQL SERVER全面优化-------Expert for SQL Server 诊断系列
以上是关于调试器是个大骗子!的主要内容,如果未能解决你的问题,请参考以下文章