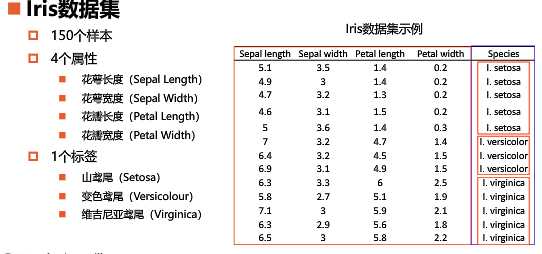
3、鸢尾花数据集
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3、鸢尾花数据集相关的知识,希望对你有一定的参考价值。
参考技术A 鸢尾花数据集是机器学习和统计学中的一个经典数据集,数据包含每朵鸢尾花花瓣的长度和宽度、花萼的长度和宽度(data),以及每朵花对应的种类(target),还有对数据的一些说明(DESCR)、种类名(target_names)、特征名(feature_names)。我们利用这个数据建立一个最简单的机器学习模型-k近邻算法。
输出
load_iris返回的对象是一个Bunch对象,与字典非常相似,里面包含键和值。其中DESCR键对应的值是数据集的简要说明,target即Y值,target_names即花的种类,feature_names即特征名,data即X值。
可以看到记录了150条数据,有4个特征,花瓣的长度、花瓣的宽度、花萼的长度、花萼的宽度。
模型精度约为97%。
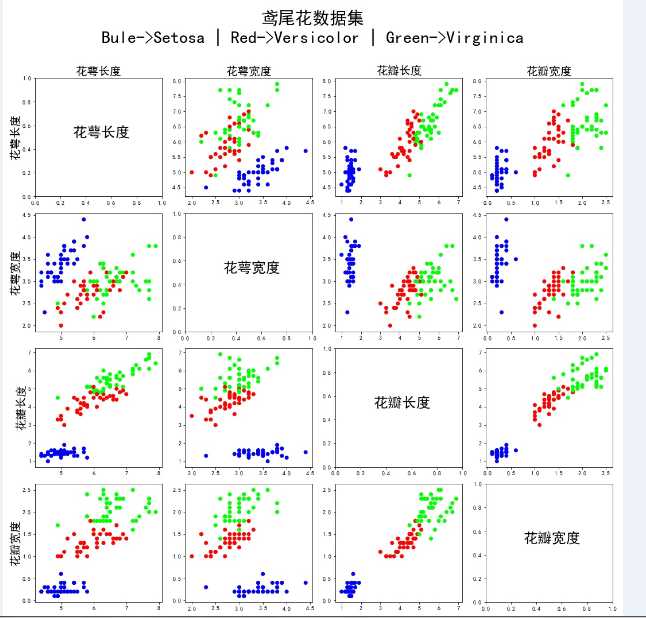
鸢尾花数据集可视化
数据集描述:其包含120条训练集和30条测试集
对鸢尾花的属性和标签之间的可视化操作:
1 import tensorflow as tf 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 6 #鸢尾花数据集 7 8 TRAIN_URL = ‘http://download.tensorflow.org/data/iris_training.csv‘ #数据下载地址 9 train_path = tf.keras.utils.get_file(TRAIN_URL.split(‘/‘)[-1], TRAIN_URL) #下载数据,并返回路径(默认路径) 10 names = [‘花萼长度‘,‘花萼宽度‘,‘花瓣长度‘,‘花瓣宽度‘,‘品种‘] #自定义列标题 11 df_iris = pd.read_csv(train_path,header=0, names=names) #names指定的列标题会替代header指定的列标题 12 #df_iris.head() #读取前5行,参数n可以指定行数 tail(n)函数读取后n行数据 13 14 #可视化 15 fig = plt.figure(‘Iris Data‘, figsize=(15,15)) 16 plt.suptitle(‘鸢尾花数据集 Bule->Setosa | Red->Versicolor | Green->Virginica‘, fontsize = 30) 17 18 for i in range(4): 19 for j in range(4): 20 plt.subplot(4,4, 4*i+(j+1)) #创建4*4的子画布,一行一行的循环画,其中每个子图的索引为 4*i+(j+1) 21 if i ==j: 22 plt.text(0.3,0.5, names[i], fontsize = 25) #正对角线上的子图只显示标签 23 else: 24 plt.scatter(np.array(df_iris)[:,j], np.array(df_iris)[:,i], c=np.array(df_iris)[:,4], cmap = ‘brg‘) 25 if i == 0: 26 plt.title(names[j], fontsize= 20) #为了美观,把title当X轴标签 27 if j == 0: 28 plt.ylabel(names[i], fontsize = 20) #设置Y轴标签 29 30 plt.tight_layout(rect=[0,0,1,0.9]) #自动调整子图布局,设置0.9是为了给全局标题一点空间,避免拥挤 31 plt.savefig(‘Iris.jpg‘) 32 plt.show()
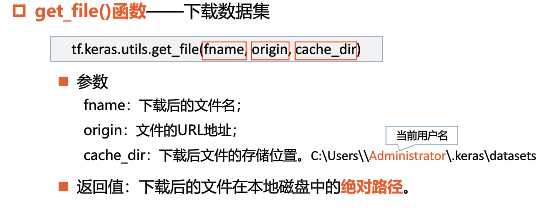
tf.keras.utils.get_file函数用于下载数据集,其参数介绍如下:
这里说明一下plt.scatter()函数中的参数c和 cmap,c用于指定一个有重复列表,cmap是一个颜色序列。
例如c=[0,1,2,0,1,2,0,1,2],cmap = ‘brg’ ,那么在绘图的过程中cmap中的颜色序列就会对c列表中值进行配对,最后0->b, 1->r, 2->g
所以c中的序列画出来的颜色就是[b,r,g,b,r,g,b,r,g]
以上是关于3、鸢尾花数据集的主要内容,如果未能解决你的问题,请参考以下文章