我的词典我做主!Python3.5生成自己的词性词典
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我的词典我做主!Python3.5生成自己的词性词典相关的知识,希望对你有一定的参考价值。
由于朋友需要做文本分析,前提是要将文本中的名词和动词剔除掉,但没有现成的名词和动词的txt格式的词典。于是找来了一个英汉词典,根据每一行出现的adj、adv、n、prep等,使用正则表达式匹配需要的词性,并将其追加写入到txt文件中。
建议大家使用python3.5,3的优点是避免了很多编码问题。3代表着python的未来,大家还是应该多多的对未来投资。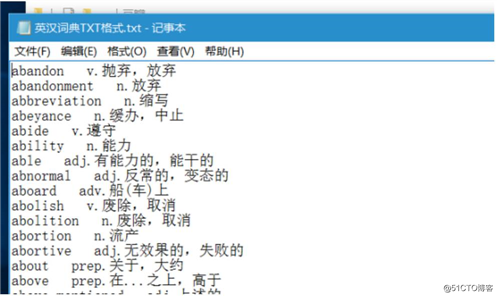
比如,我要生成形容词的词典。步骤:
1、应先使用正则表达式,匹配含有‘adj’的行字符串,返回的是list。
2、获得adj结尾处的索引值
3、对行字符串进行切片处理,获得索引值后的全部字符
4、如果获得的字符串有 ‘,’ 那再用正则表达式,匹配中文字符,获得的是中文的list
代码实现如下:
import re
strs = open(r‘C:/Users/myl/Desktop/SegChineseToWords/英汉词典TXT格式.txt‘,‘r‘,encoding=‘utf-8‘).readlines()
for str in strs:
# 形容词典
adj_re = re.search(‘adj‘, str)
if adj_re != None:
adj_num = adj_re.end()+1
adj_str = str[adj_num:]
adj_list = re.findall("[u4e00-u9fa5]+", adj_str)
for ele_adj in adj_list:
ele_adj = ele_adj + ‘
‘
with open(r‘C:/Users/myl/Desktop/SegChineseToWords/Dict/adj_dict.txt‘, ‘a+‘,encoding=‘utf-8‘) as f:
f.write(ele_adj)实现的效果如下图: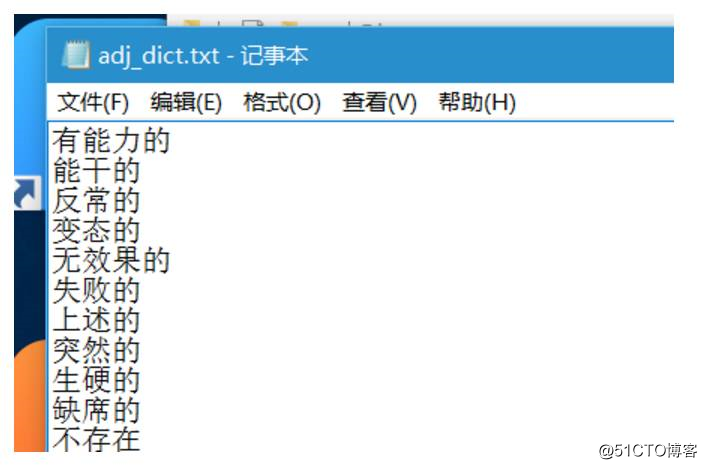
本代码中用到 re模块 的 research方法 ,具体大家去百度下,这个方法的相关知识。
现在附上 练习材料和最终代码,大家可以比照着练习下正则。
代码:http://pan.baidu.com/s/1dFyWQwL
火爆参团:
崔老师联合天善学院带来爬虫视频《自己动手,丰衣足食!Python3网络爬虫实战案例》,正在火爆参团中~
参团方式:阅读原文 | 长按扫码
以上是关于我的词典我做主!Python3.5生成自己的词性词典的主要内容,如果未能解决你的问题,请参考以下文章