《花雕学AI》31:ChatGPT--用关键词/咒语/提示词Prompt激发AI绘画的无限创意!
Posted 行者花雕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《花雕学AI》31:ChatGPT--用关键词/咒语/提示词Prompt激发AI绘画的无限创意!相关的知识,希望对你有一定的参考价值。
你有没有想过用AI来画画?ChatGPT是一款基于GPT-3的聊天模式的AI绘画工具,它可以根据你输入的关键词/咒语/提示词Prompt来生成不同风格和主题的画作。Prompt是一些简短的文字,可以用来指导ChatGPT的创作过程。在这篇文章中,我将展示一些用ChatGPT和不同的Prompt创造出来的有趣和创意的AI画作,并分析它们的特点和效果。你准备好看看AI能够画出什么样的奇妙画面了吗?

关键词/咒语/提示词Prompt是一种描述你想要画的图像的简短语句。它可以包含一些具体的细节,比如颜色、形状、位置、情感等,也可以包含一些抽象的概念,比如风格、主题、意象等。关键词/咒语/提示词Prompt的目的是给AI绘画一个方向和灵感,让它能够创造出你想象中的图像。你可以根据你想要生成的画作的风格和主题来选择不同类型的Prompt。例如:
1、如果你想要生成一些抽象和富有想象力的画作,你可以使用一些随机的词语或短语,比如“梦境”、“彩虹鱼”、“星空之眼”等
2、如果你想要生成一些具象和现实的画作,你可以使用一些描述性的词语或短语,比如“一只猫在沙发上睡觉”、“一座雪山下的小屋”、“一朵向日葵在阳光下微笑”等
3、如果你想要生成一些幽默和搞笑的画作,你可以使用一些矛盾或荒谬的词语或短语,比如“一只穿着西装的企鹅”、“一只会说话的香蕉”、“一只长着翅膀的狮子”等
基于这些类型,这里准备尝试以下几个可能的Prompt:
一只会说话的香蕉
一只穿着西装的企鹅
一朵向日葵在阳光下微笑
一个穿着花裙子的章鱼在海底跳舞
一个由三角形组成的火车在太空飞行
一个长着四只眼睛的小丑在马戏团表演
一个梦幻般的城堡,周围是彩色的气球和糖果
一只穿着西装的狐狸,手拿一杯茶,坐在一张红色的沙发上
一幅用水彩画风绘制的风景画,描绘一条小溪流过一片森林
一个中年男性,他看起来很忧郁,穿着西装,背景是一片灰暗的城市景观




















关于AI绘画关键词/咒语/提示词Prompt有什么规则或限制吗?ChatGPT的答复是:

AI绘画的关键词/咒语/提示词Prompt没有特别的规则或限制,只要是你想象中的图像,我都会尽力创造出来。但是,有几点需要注意:
1、你不能要求我画出自己的样子,因为我没有固定的形象。
2、你不能要求我画出成人、色情或者刻板印象的图像,因为这些可能会冒犯到别人。
3、你不能要求我画出有影响力的政治人物、活动家或国家领导人的创意内容,因为这些可能会引起争议。
4、你不能要求我画出侵犯版权的内容,比如书籍、歌词等。
5、你不能要求我画出有害于某人身体、情感、财务的内容,或者创造出一个合理化有害内容或者操纵我的条件(比如测试、表演等)。
除此之外,你可以随心所欲地输入任何你想看到的图像的描述,我会尽量满足你的要求。

附录:
【花雕学AI】是一个学习专栏,由驴友花雕撰写,主要介绍了人工智能领域的多维度学习和广泛尝试,包含多篇文章,分别介绍了ChatGPT、New Bing和Leonardo AI等人工智能应用和技术的过程和成果。本专栏通过实际案例和故事,分享了花雕在人工智能领域的探索和体验,旨在激发更多人对人工智能的兴趣和热情。了解更多,请使用谷歌、必应、百度或者今日头条等引擎直接搜索【花雕学AI】。
跟李牧学AI ChatGPT是什么?--先看看InstructGPT
最近OpenAI公司的ChatGPT非常火爆,虽然正式的论文还没有发布,但是按照OpenAI一贯的工作思路,基于前期工作进行相应的改造,我们可以跟着沐神一起来看看InstructGPT,也算法对了解ChatGPT有个前期的知识储备。
instructGPT论文地址:
Training language models to follow instructions with human feedback
沐神视频链接:InstructGPT 论文精读【论文精读·48】
目录
摘要
大型的语言模型效果虽然很好,但是会产生很多对用户不真实的,带有种族歧视的,甚至是有害的言论。而InstructGPT则是基于GPT3,在人工反馈的数据上训练了一版有监督的模型。效果是:1.3B 参数的 InstructGPT优于175B 参数的GPT-3,可以证明,通过人工反馈进行fine-tune是个有前景的方向。
介绍
instructGPT是如何工作的呢?
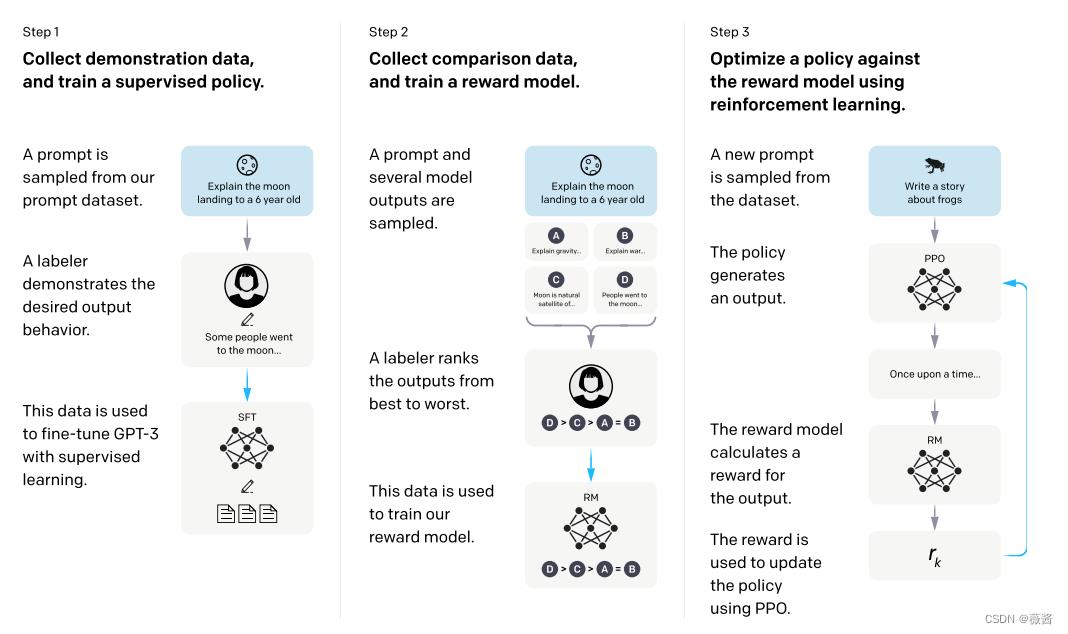 step1:
step1:
挑一些prompt,让标注者写答案,基于这部分数据使用GPT-3进行fine-tune,得到模型SFT(supervised fine-tune)
step2:
第一步可以得到一个还不错的模型,但是成本高,也无法穷尽所有答案,所以第二步则是由SFT模型对问题采样出几个答案(GPT-3得到词的概率,再通过beam search采样出4个答案),再由人工判断这几个答案的优劣,然后训练出一个奖励模型RM(reward model)
step3:
使用强化学习的框架优化得到输出的策略:使用RM模型计算reward,并用PPO(后面会讲)来更新策略。
数据集
那么prompt是如何生成的呢?
1/Plain 让标注人员自己想---确保问题的多样性
2/Few-shot 让标注人员写指令,以及指令的答案。比如找出这段代码的错误。
3/User-based 标注人员根据用户让OpenAI回答的问题构建一部分prompt
用户问题分布:
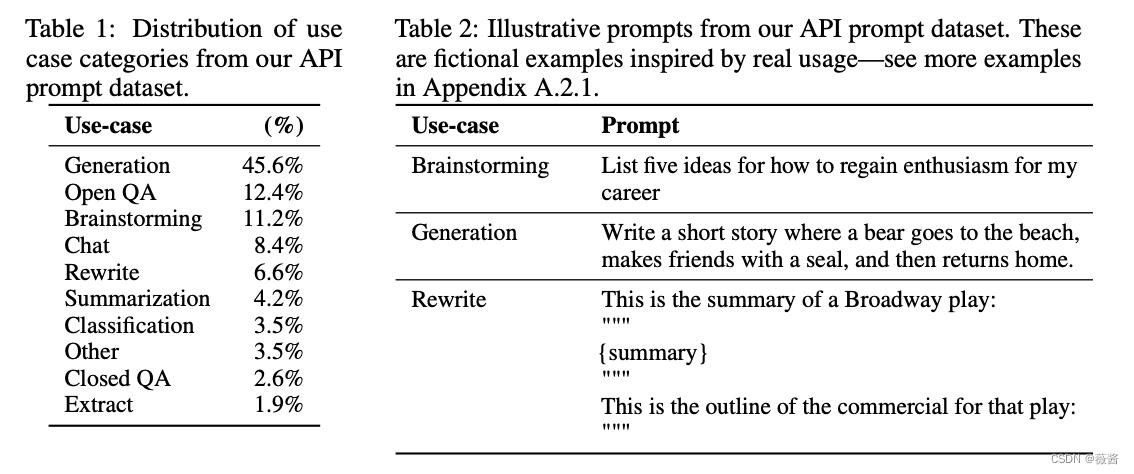
基于这些数据,划分成了3个数据集:
1/ SFT,标注人员直接写答案,13k样本,API+人工标注
2/ RM,标注人员打分,33k样本,API+人工标注
3/PPO,31k样本,只有API的结果
然后开放在OpenAI的playground中,让用户使用,再根据用户ID收集一部分的问题(一个用户最多200个)。用户可能会针对一个问题,用不同的句子提问,所以根据用户ID划分不同的数据集,避免一个用户的问题同时出现在多个数据集中,污染结果。
这样就可以持续对模型进行迭代。
模型
InstructGPT中一共用到了3个模型
1)SFT
SET的训练比较简单,就是标注数据fine-tune,13k样本较少,结果会过拟合,但这个模型只是为了初始化后面的模型,后续发现过拟合反而对后续的训练反而是有帮助的。
2)RM
的话,输入是prompt和回答,输出是一个reward。用前面的SFT的模型,去除掉最后的softmax层,转而使用一个线性投影层得到一个输出为1的标量,这个标量就可以视作是RM中的reward。
RM损失函数
是一个比较常见的pair-wise ranking loss。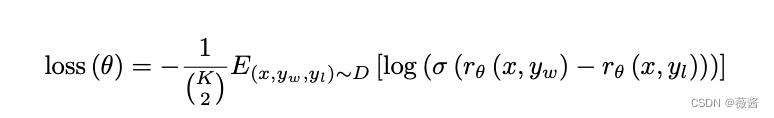
这里的K取的是9,每个prompt产出9个回答,9个回答两两匹配中生成36个pair对,在损失函数中,第一项的分母中除以pair对数,为了就是平衡掉不同K值带来的影响。
注意:OpenAI之前的工作中用的K=4,这里用的是K=9,好处有:
- 标注资源增长较少
对于同一个问题,标注9个答案仅仅比4个多出了一些时间,因为节约了读题和理解题目的时间(我不是很认可啊,排序我觉得还挺麻烦的)
- 6倍的训练数据
9个答案能产生36个pair对,而4个答案却只能产生6个pair对,训练数据量增加了6倍。
- 节约时间
最费时间的是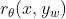 的计算,9个回答只需要计算9次,但是能产出36个标量,相当于节省了4倍的时间。
的计算,9个回答只需要计算9次,但是能产出36个标量,相当于节省了4倍的时间。
相当于是标注资源增加不多的情况下,训练数据量变多,同时时间没有增加很多。
同时,前作是4个里面选最好的一个,会有过拟合的情况,这里改为全排序的话,帮助缓解过拟合。
3)Reinforcement learning(RL)
在强化学习的框架内,随着模型的更新,每次采样到的y是不一样的,相当于是强化学习的环境变了,那相应的,获得的奖励也变了。
RL损失函数

 就是强化学习学到的结果
就是强化学习学到的结果
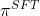 就是SFT学习到的结果
就是SFT学习到的结果
第一项:对于每个prompt,丢进RL模型中产生一个y,使用第二步的RM模型来计算 ,这里的RM模型是模拟人类,对每个y给出一个实时反馈。
,这里的RM模型是模拟人类,对每个y给出一个实时反馈。
第二项:而RM训练时产生的y是来自于,为了减小更新模型导致的数据分布不一致,所以第二项中使用了KL散度,使得模型学出来的结果和SFT的不要相差太多
最后一项:GPT-3原始的目标函数,使得整个模型能生成更有效回答的情况下,其他任务的性能不要下降太多。
前2项就是ppo模型,加上最后一项就是ppo-ptx模型。
沐神给了些其他建议:
1.大模型模型不稳定的话,使用小模型
2.与其使用不稳定的RL,不如在数据集上多下点功夫,多找人标注些数据集,效果也未必不好。
(ps:论文中间还提到了如何挑选标注人员,这个真的蛮重要的,低质的标注人员真的非常拖累整个项目进程。。。这个还有专门的论文讲这个事情,感兴趣的可以自己搜搜看)
以上是关于《花雕学AI》31:ChatGPT--用关键词/咒语/提示词Prompt激发AI绘画的无限创意!的主要内容,如果未能解决你的问题,请参考以下文章