CosineSimilarity
Posted Joker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CosineSimilarity相关的知识,希望对你有一定的参考价值。
余弦相似度
implementation \'org.apache.commons:commons-text:1.10.0\'
Measures the Cosine similarity of two vectors of an inner product space and compares the angle between them.
For further explanation about the Cosine Similarity, refer to http://en.wikipedia.org/wiki/Cosine_similarity.
Since:
1.0
百度百科:
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
其余弦相似性θ可以推倒得出:

以程序为例:
已知两个字符串
a = "Hello World"
和
b = "Hello Shaun Murphy Hello World"
其内部有一个工具类CosineDistance.class
1. 分别提取a和b中有多少单词,并对单词进行计数
此时两个句子共有Hello,在a中出现频率为1,在b中出现频率为2,World在a中出现1次,在b中出现1次
final CharSequence[] leftTokens = tokenizer.tokenize(left);
final CharSequence[] rightTokens = tokenizer.tokenize(right);
final Map<CharSequence, Integer> leftVector = Counter.of(leftTokens);
final Map<CharSequence, Integer> rightVector = Counter.of(rightTokens);
2. 求公式中的分子
Hello单词在a中出现的次数在b中出现的次数 + World单词在a中出现的次数在b中出现的次数之和
1 * 2 + 1 * 1 = 3
private Set<CharSequence> getIntersection(final Map<CharSequence, Integer> leftVector,
final Map<CharSequence, Integer> rightVector)
final Set<CharSequence> intersection = new HashSet<>(leftVector.keySet());
intersection.retainAll(rightVector.keySet());
return intersection;
先拿到两个句子公共单词,然后对两个句子的公共部分分别计数
private double dot(final Map<CharSequence, Integer> leftVector, final Map<CharSequence, Integer> rightVector,
final Set<CharSequence> intersection)
long dotProduct = 0;
for (final CharSequence key : intersection)
dotProduct += leftVector.get(key) * (long) rightVector.get(key);
return dotProduct;
3. 求公式中的分母
依旧是两个求和在相加,但这次是对各自的单词出现的次数的平方进行求和
d1 = 1 * 1 + 1 * 1 = 2
d2 = 2 * 2 + 1 * 1 + 1 * 1 + 1 * 1 = 7
double d1 = 0.0d;
for (final Integer value : leftVector.values())
d1 += Math.pow(value, 2);
double d2 = 0.0d;
for (final Integer value : rightVector.values())
d2 += Math.pow(value, 2);
4. 求出相似度
余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越接近;越趋近于-1,他们的方向越相反;接近于0,表示两个向量近乎于正交。
两数相除得出相似度,这里对小于零的情况(这里不会发生)也做了判断
cosineSimilarity ≈ 3 / 3.74166 ≈ 0.80
final double cosineSimilarity;
if (d1 <= 0.0 || d2 <= 0.0)
cosineSimilarity = 0.0;
else
cosineSimilarity = dotProduct / (Math.sqrt(d1) * Math.sqrt(d2));
5. 补充
①. 最后求CosineDistance的时候,用的是:
1.0 - similarity
这里表示两个字符序列的距离,距离越远,越不相似。
②. CosineDistance内部使用的正则表达式,不包含中文,因此测试用例用的英文
final class RegexTokenizer implements Tokenizer<CharSequence>
/** The whitespace pattern. */
private static final Pattern PATTERN = Pattern.compile("(\\\\w)+");
/**
* @inheritDoc
*
* @throws IllegalArgumentException if the input text is blank
*/
@Override
public CharSequence[] tokenize(final CharSequence text)
Validate.isTrue(StringUtils.isNotBlank(text), "Invalid text");
final Matcher matcher = PATTERN.matcher(text);
final List<String> tokens = new ArrayList<>();
while (matcher.find())
tokens.add(matcher.group(0));
return tokens.toArray(ArrayUtils.EMPTY_STRING_ARRAY);
70自然语言处理与词嵌入
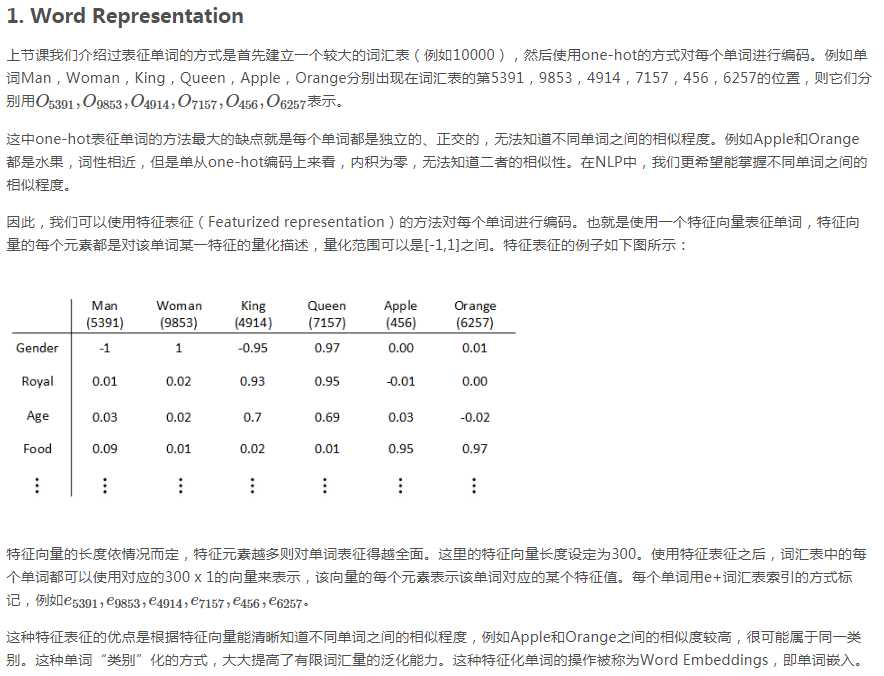
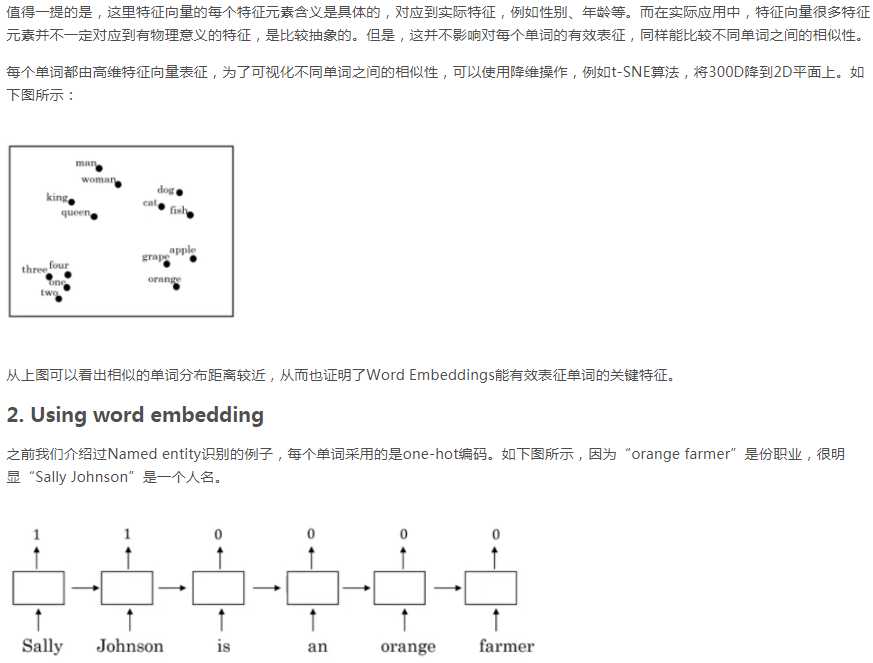

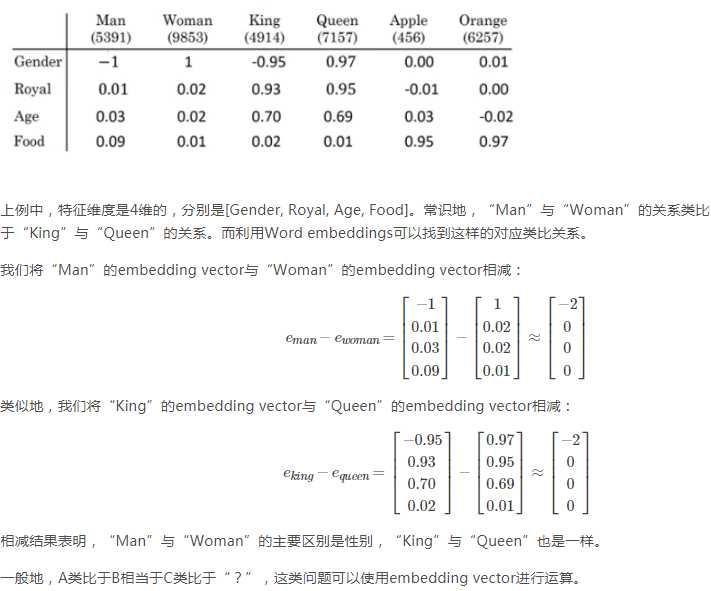
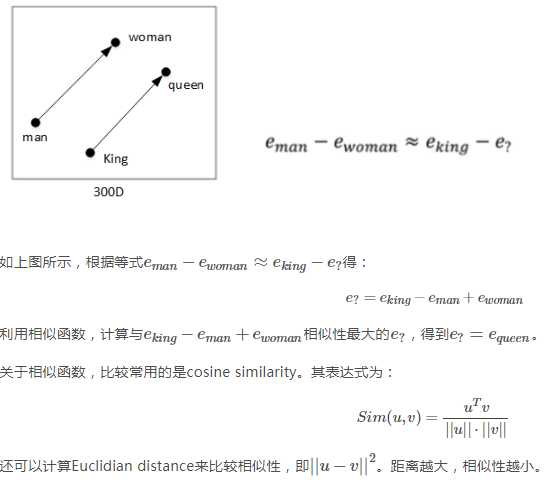
如果相似函数是cosine similarity,且A类比于B相当于C类比于“?” 该如何求“?”
首先求出sim(A,B) 然后令sim(C,?)=sim(A,B) 然后求出?,再找到与?相似性最大的向量e?。
或者求出sim(A,B)后,将其他向量逐一代入sim(C,?) 看看哪个与Sim(A,B)最接近。



以上是关于CosineSimilarity的主要内容,如果未能解决你的问题,请参考以下文章