Python爬虫豆瓣登录
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫豆瓣登录相关的知识,希望对你有一定的参考价值。
前面(1)(2)的内容已经足够爬虫如链家网之类的不需要登录可以直接获取数据的网站。
而要爬取社交网站比较鲜明的特点就是需要登录,否则很多东西都无法获取。经过测试发现,微博,知乎都不是很好登录,知乎有时候的验证码会类似12306那样,而微博除了验证码,在传递参数的时候会对用户名进行base64加密。这里讲简单的豆瓣的登录以及简单的爬取。
对于Chrome内核的浏览器来说,可以右键,审查元素,选择network,登录一下自己的账号。
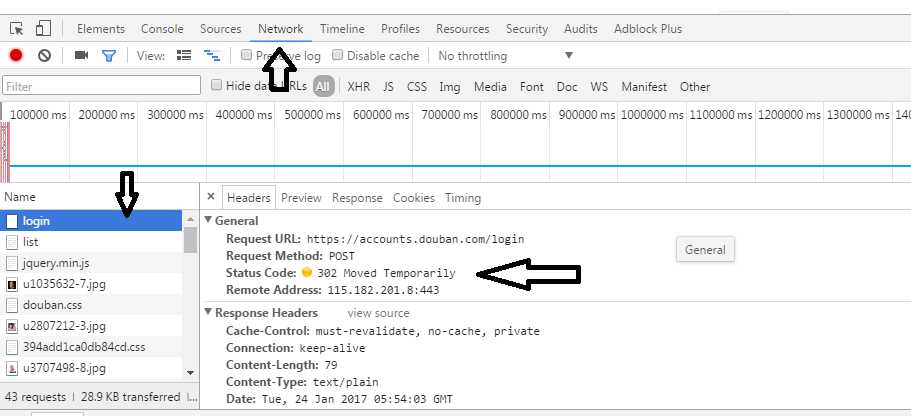
选中login会有各种post还是get,url,连接头各种信息。
往下拉找到formdat,像微博就把formdata给加密了。
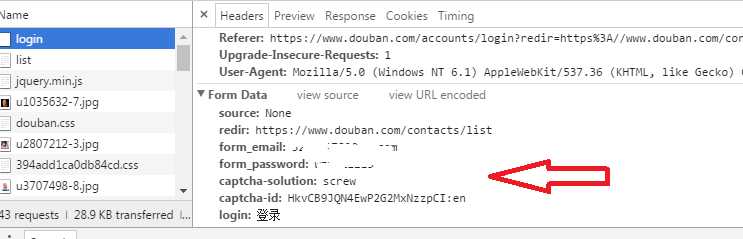
form data里有我们登录所需要的所有信息,其中captcha-solution就是登录验证码,有时候有 有时候没有所以在请求的时候,需要判断有没有。
import requests
import re
from bs4 import BeautifulSoup as bs
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
s = requests.Session()
url_login = ‘http://accounts.douban.com/login‘
url_contacts = ‘https://www.douban.com/contacts/list‘
formdata = {
‘source‘:‘index_nav‘,
‘redir‘: ‘https://www.douban.com‘,
‘form_email‘: ‘22222‘,
‘form_password‘: ‘111111‘,
‘login‘: u‘登录‘
}
headers = {‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36‘}
r = s.post(url_login, data=formdata, headers=headers)
content = r.text
soup = bs(content, ‘lxml‘)
captcha = soup.find(‘img‘, id=‘captcha_image‘)
if captcha:
captcha_url = captcha[‘src‘]
re_captcha_id = r‘<input type-"hidden" name="captcha-id" value="(.*?)"/‘
captcha_id = re.findall(re_captcha_id, content)
print captcha_id
print captcha_url
captcha_text = raw_input(‘Please input 验证码啊‘)
formdata[‘captcha-solution‘] = captcha_text
formdata[‘captcha-id‘] = captcha_id
r = s.post(url_login, data=formdata, headers=headers)
这样就成功登录啦。
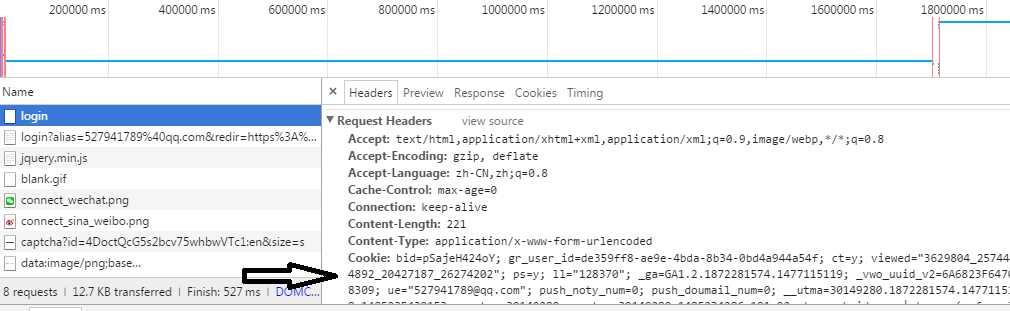
其实还有一种简单的办法,就是在登录的时候 选择记住我,然后在Request Headers里复制下来cookie,cookie可以用很久,所以还是足够自用的。
import requests
import os
headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36‘}
cookies = {‘cookie‘:1‘}
url = ‘http://www.douban.com‘
r = requests.get(url, cookies=cookies,headers=headers)
r.encoding = ‘utf-8‘
print r.text
with open(‘douban.txt‘,‘wb+‘,encoding = ‘utf‘) as f:
f.write(r.content)
以上是关于Python爬虫豆瓣登录的主要内容,如果未能解决你的问题,请参考以下文章